

















You can create a data migration task that migrates data from a TiDB database to a MySQL-compatible tenant of OceanBase Database. The task performs schema migration, full data migration, and incremental synchronization to seamlessly migrate existing business data and incremental data from the source database to the target database.
Notice
If a data migration task remains inactive for a long time (with a status of Failed, Paused, or Completed), it may not be recoverable due to factors such as the retention period of incremental logs. Data migration will automatically release tasks that have been inactive for more than 7 days to reclaim resources. We recommend that you configure alerts for tasks and promptly address any related exceptions.
Background information
A hybrid transactional/analytical processing (HTAP) database that supports online transaction processing (OLTP) and online analytical processing (OLAP), TiDB is a distributed database system. To synchronize incremental data from a TiDB database to a MySQL-compatible tenant of OceanBase Database, you must deploy a TiCDC cluster and a Kafka cluster.
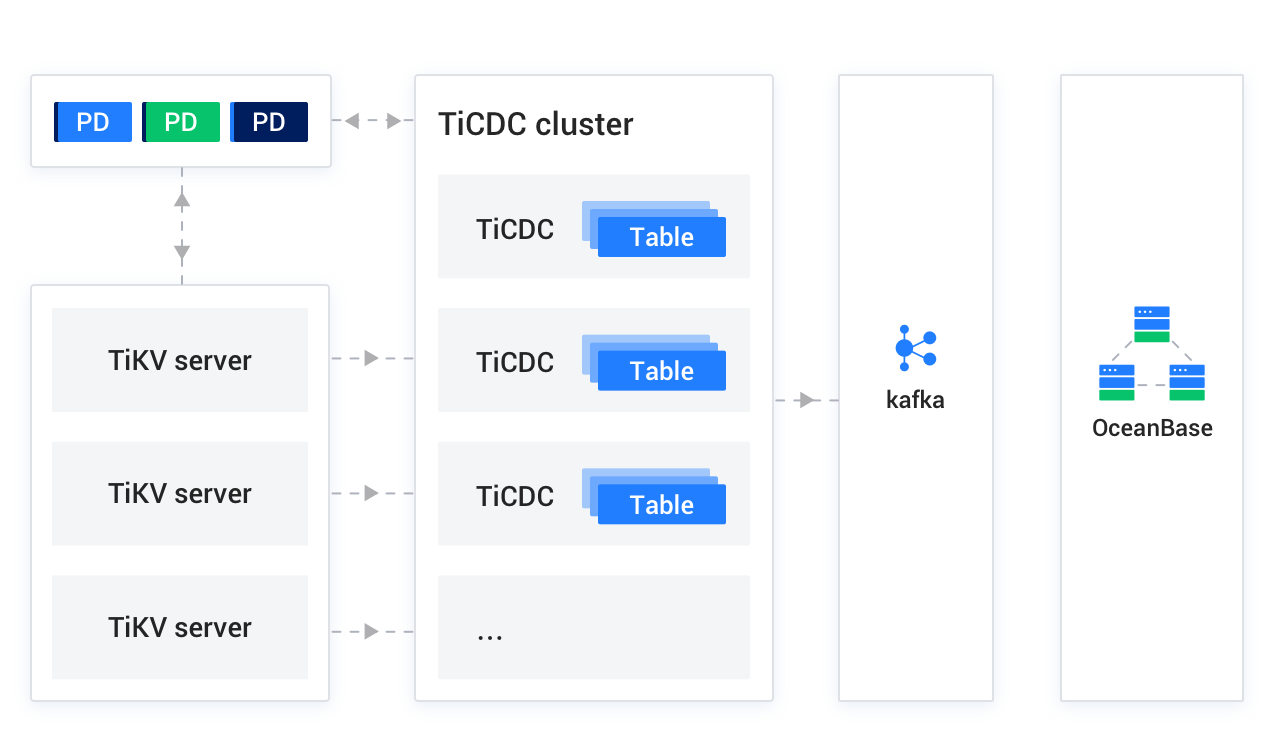
TiCDC is an incremental data synchronization tool for TiDB. It ensures high availability by using a PD cluster, which usually consists of three PD nodes. The TiKV server in the TiDB cluster actively sends change data to the TiCDC cluster in the form of change logs. The TiCDC tool then synchronizes the data to the Kafka cluster through multiple TiCDC processes. The Kafka cluster stores the incremental logs of the TiDB database converted by TiCDC. During incremental data synchronization, the data migration service retrieves the corresponding data from the Kafka cluster and real-time migrates it to the MySQL-compatible tenant of OceanBase Database. If you do not bind a Kafka data source when creating a TiDB data source, you cannot perform incremental synchronization.
Prerequisites
You have created a source database instance.
You have created an instance and a tenant for the target OceanBase Database. For more information, see Create an instance and Create a tenant.
You have created dedicated database users for data migration in the source and target databases and granted the required privileges to these users. For more information, see User privileges.
Limitations
Only project roles with the Project Owner, Project Admin, or Data Services Admin role can create data migration tasks.
Limitations on operations in the source database
- Do not perform DDL operations to modify the schema of a database or table during schema migration or full data migration. Otherwise, the data migration task may fail.
At present, the data migration service supports TiDB database V4.x, V5.4, V6.x, and V7.x and OceanBase Database (in the MySQL compatible mode) V2.x, V3.x, and V4.x.
When you migrate data from a TiDB database to a MySQL-compatible tenant of OceanBase Database, you cannot synchronize DDL operations.
The data migration service supports only objects whose names consist of ASCII characters without special characters (., |, ", ', `, (, ), =, ;, /, &, and newline).
The data migration service supports only the TiCDC open protocol. If you use any other protocol, the JDBC-Connector throws an exception with a null pointer error.
The data migration service does not support triggers in the target database. If a trigger exists, the data migration task may fail.
If you select TiCDC as the incremental synchronization method, you must refer to TiCDC Overview to understand the limitations. Otherwise, data inconsistency may occur.
Considerations
If the source database contains foreign keys with the same name, an error will occur during schema migration. You can modify the foreign key constraint names and then resume the task.
If the source database uses the UTF-8 character set, it is recommended to use a compatible character set on the target database (such as UTF-8 or UTF-16) to avoid issues like garbled characters due to incompatibility.
Do not write data to the topic used for synchronization by TiCDC. Otherwise, it may cause exceptions in the JDBC-Connector, resulting in a null pointer error.
If you need to modify unique indexes on the target database, you must restart the data migration task to ensure data consistency.
In scenarios involving table aggregation:
It is recommended to map the relationships between the source and target databases using matching rules.
It is recommended to create the table structure manually on the target database. If you choose to let the data migration service create the structure, skip failed objects during the schema migration step.
If the table structures of the source and target databases are not completely consistent, data inconsistencies may occur. Known scenarios include:
When users manually create table structures that exceed the supported range of data migration, implicit conversion issues may arise, leading to type mismatches between columns on the source and target databases.
If the length of data on the target database is shorter than that on the source database, data truncation may occur, causing inconsistencies between the two.
If there are table objects with only case differences between the source and target databases, data migration results may not meet expectations due to case insensitivity on either side.
Clock desynchronization between nodes or between the client terminal and the server can lead to inaccurate incremental synchronization latency.
For example, if the clock is earlier than standard time, the latency may be negative. If the clock is later than standard time, it may cause delays.
Verify whether the precision of column types such as DECIMAL, FLOAT, and DATETIME during data migration meets your expectations. If the precision of the target field type is less than that of the source field type, truncation may occur, leading to data inconsistencies between the two.
When creating a new data migration task, if you configure only Incremental Synchronization, the source database's local incremental logs must be retained for more than 48 hours.
If you configure Full Migration + Incremental Synchronization, the source database's local incremental logs must be retained for at least 7 days. Otherwise, the data migration task may fail due to the inability to obtain incremental logs, potentially causing data inconsistencies between the source and target databases.
Supported source and target instance types
In the following table, the supported instance types for OceanBase MySQL Compatible include Dedicated (Transactional) and Dedicated (Analytical).
Cloud vendor |
Source |
Target |
|---|---|---|
| AWS | Self-managed TiDB | OceanBase MySQL Compatible |
| Huawei Cloud | Self-managed TiDB | OceanBase MySQL Compatible |
| Google Cloud | Self-managed TiDB | OceanBase MySQL Compatible |
| Alibaba Cloud | Self-managed TiDB | OceanBase MySQL Compatible |
Data type mappings
TiDB Database |
OceanBase Database (MySQL Compatible Mode) |
|---|---|
| INTEGER | INTEGER |
| TINYINT | TINYINT |
| MEDIUMINT | MEDIUMINT |
| BIGINT | BIGINT |
| SMALLINT | SMALLINT |
| DECIMAL | DECIMAL |
| NUMERIC | NUMERIC |
| FLOAT | FLOAT |
| REAL | REAL |
| DOUBLE PRECISION | DOUBLE PRECISION |
| BIT | BIT |
| CHAR | CHAR |
| VARCHAR | VARCHAR |
| BINARY | BINARY |
| VARBINARY | VARBINARY |
| BLOB | BLOB |
| TEXT | TEXT |
| ENUM | ENUM |
| SET | SET |
| DATE | DATE |
| DATETIME | DATETIME |
| TIMESTAMP | TIMESTAMP |
| TIME | TIME |
| YEAR | YEAR |
Procedure
Create a data migration task.
Log in to the OceanBase Cloud console.
In the left-side navigation pane, select Data Services > Migrations.
On the Migrations page, click the Migrate Data tab.
In the upper-right corner of the Migrate Data tab, click Create Task.
In the text box for editing the task name, enter a custom migration task name.
We recommend that you use a combination of Chinese characters, digits, and letters. The name must not contain spaces and must be no longer than 64 characters.
On the Configure Source and Target page, configure the parameters.
In the Source section, configure the parameters.
If you want to reference an existing data source, click Quick Fill next to Source, select the target data source from the drop-down list, and then the configurations in the Source section will be automatically filled in. If you want to save the current configuration as a new data source, click the Save icon in the upper-right corner of the Source section.
You can also click Manage Data Sources in the Quick Fill drop-down list to go to the Data Sources page, where you can view and manage data sources. This page provides unified management of different types of data sources. For more information, see Data Sources.
ParameterDescriptionCloud vendor Currently supports AWS, Huawei Cloud, Google Cloud, and Alibaba Cloud. Database type Select TiDB as the database type for the source. Instance type Currently only supports Self-managed TiDB. Region Select the region where the source database is located. Connection type Includes Endpoint and Public IP. - If you select Endpoint as the connection type, you need to add the displayed account ID to the allowlist of your endpoint service to allow the endpoint to connect to the endpoint service. For more information, see Select Private Connection.
- When Cloud Vendor is set to AWS, if you selected Acceptance required for the Require acceptance for endpoint parameter when creating the endpoint service, a prompt will appear when the data migration service first connects via private link, asking you to go to the AWS console and perform the Accept Endpoint Connection Request action.
- When the cloud vendor is set to Google Cloud, you need to add the authorized project to Published Services. After adding authorization, manual authorization is no longer required during data source testing.
- If you select Public IP as the connection type, you need to add the displayed data source IP address to the allowlist of your TiDB database instance to ensure connectivity. For more information, see Select Public Connection.
Note
The page will display the IP address to be added to the allowlist only after you have selected the regions for both the source and target.
Connection information - If you select Connection Type as Endpoint, enter the endpoint service name.
- If you select Connection Type as Public IP, enter the IP address and port number of the database host.
Database account The username of the TiDB database used for data migration. Password The password of the database user. If you want to use Kafka to obtain incremental data from TiDB, fill in the Incremental Synchronization Settings section to enable the Binlog and TiCDC data sources. If you do not fill in the following configurations, you will be unable to select Incremental Synchronization on the Select Type & Objects page.
ParameterDescriptionKafka Data Source The Kafka data source stores information about the incremental logs of TiDB data converted by the Binlog and TiCDC tools for consumption during data migration. Notice
You can only select a Kafka data source provided by the same cloud service provider as your TiDB cluster.
Topic Select the topic of the Kafka data source you want to bind from the drop-down list. TiDB Data Format When migrating data from the TiDB database to the MySQL compatible mode of OceanBase Database, you can choose the TiCDC or TiDB Binlog format from the drop-down list. - If you select Endpoint as the connection type, you need to add the displayed account ID to the allowlist of your endpoint service to allow the endpoint to connect to the endpoint service. For more information, see Select Private Connection.
In the Target section, configure the parameters.
If you want to reference an existing data source, click Reference Data Source next to Target and select the target data source from the drop-down list. After you select the data source, the configuration parameters in the Target section will be automatically filled in. If you want to save the current configuration as a new data source, click the Save icon in the upper-right corner of the Target section.
You can also click Manage Data Sources in the Reference Data Source drop-down list to go to the Data Sources page, where you can view and manage data sources. This page centrally manages different types of data sources. For more information, see Data Sources.
ParameterDescriptionCloud vendor Currently, AWS, Huawei Cloud, Google Cloud, and Alibaba Cloud are supported. You can choose the same cloud vendor as the source or migrate data across cloud vendors. Note
By default, cross-cloud vendor data migration is not enabled. If you want to use this feature, contact OceanBase Cloud technical support.
Database type Select OceanBase MySQL Compatible for the target database type. Instance type Currently, Dedicated (Transactional) and Dedicated (Analytical) are supported. Region Select the region where the target database is located. Instance The ID or name of the instance where the MySQL-compatible tenant of OceanBase Database belongs. You can view the ID or name of the target instance on the Instances page. Note
If the cloud vendor is Alibaba Cloud, you can also select an Alibaba Cloud main account instance with cross-account authorization. For more information, see Authorize an Alibaba Cloud account.
Tenant The ID or name of the MySQL-compatible tenant of OceanBase Database. You can view the ID or name of the target tenant by expanding the target instance on the Instances page. Note
This parameter is not displayed if the instance type is Dedicated (Analytical).
Database account The username of the MySQL-compatible tenant of OceanBase Database used for data migration. Password The password of the database user.
Click Test and Continue.
On the Select Type & Objects page, configure the parameters.
Note
Currently, only one-way synchronization is supported when migrating data from a TiDB database to a MySQL-compatible tenant of OceanBase Database.
In the Migration Type section, select the migration type for the current task.
The Migration Type field supports Schema Migration, Full Migration, and Incremental Synchronization.
ParameterDescriptionSchema Migration Schema migration requires you to define character set mappings. Data migration copies the schema of the source database to the target database without affecting the source schema. Full Migration After a full migration task starts, the data migration service migrates existing data from the source database tables to the corresponding tables in the target database. Incremental Synchronization After an incremental synchronization task starts, data migration synchronizes changes in the source database, such as new, modified, or deleted data, to the corresponding tables in the target database. Incremental Synchronization supports DML Synchronization, which you can customize as needed. For more information, see Customize DML/DDL settings. In the Select Migration Objects section, configure the method for selecting the migration object.
You can select the migration object by using Specify Objects or Match by Rule.
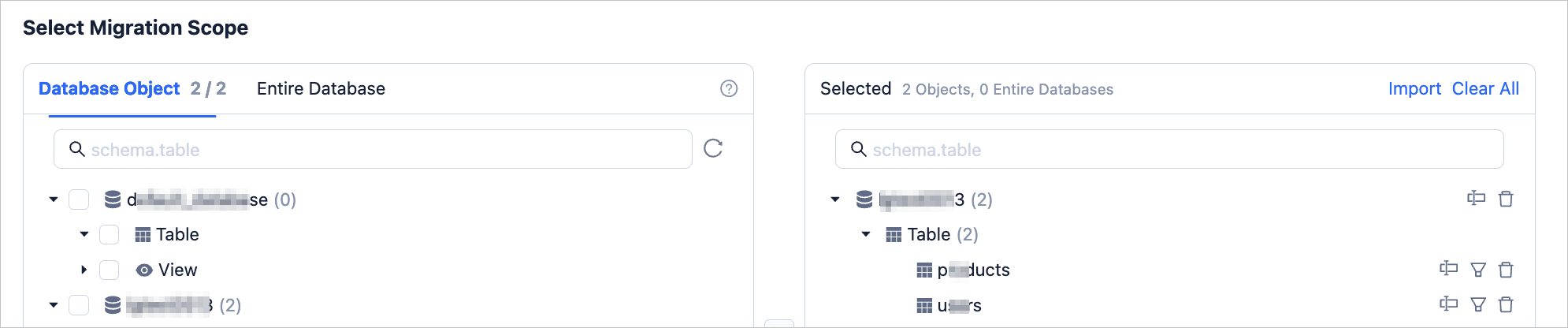
In the Select Migration Scope section, select the objects to migrate.
If you select Specify Objects, data migration supports Table-level and Database-level. Table-level migration allows you to select one or more tables or views from one or more databases as migration objects. Database-level migration allows you to select an entire database as a migration object. If you select table-level migration for a database, database-level migration is no longer supported for that database. Conversely, if you select database-level migration for a database, table-level migration is no longer supported for that database.
After selecting Table-level or Database-level, select the objects to be migrated in the left pane and click > to add them to the right pane.
Data migration supports importing objects via text and allows renaming of target objects, setting row filters, viewing column information, and removing individual or all migration objects.
Note
If you select Database-level, only the database names will be displayed in the right pane, and specific objects cannot be shown.
ActionDescriptionImport Objects Click Import Objects in the upper-right corner of the right pane. For more information, see Import Migration Objects. Rename Data migration supports renaming migration objects. For more information, see Rename Database Tables. Row Filtering Data migration supports using WHEREconditions to filter rows. For more information, see SQL Condition Filtering. You can also view column information of migration objects in the View Columns section.Remove/Clear All Data migration supports removing temporarily selected objects to the target during data mapping. - Remove a Single Migration Object
Click the Remove icon next to the target object in the right pane to remove it. - Remove All Migration Objects
Click Clear All in the upper-right corner of the right pane. In the dialog box that appears, click OK to remove all migration objects.
- Remove a Single Migration Object
For details on configuring matching rules, see Configure matching rules for database-to-database migration.
Click Next. On the Migration Options page, configure the parameters.
Full migration
In the Select Type & Objects step, select One-way Sync > Full Migration to display the following parameters.
ParameterDescriptionRead Concurrency This parameter specifies the number of concurrent threads for reading data from the source during full migration. The maximum number of concurrent threads is 512. A high number of concurrent threads may cause high pressure on the source and affect business operations. Write Concurrency This parameter specifies the number of concurrent threads for writing data to the target during full migration. The maximum number of concurrent threads is 512. A high number of concurrent threads may cause high pressure on the target and affect business operations. Rate Limiting for Full Migration You can decide whether to limit the full migration rate based on your needs. If you enable this option, you must also set the source read RPS (maximum number of rows that can be read from the source per second during full migration), source read BPS (maximum amount of traffic that can be read from the source per second during full migration), target write RPS (maximum number of rows that can be written to the target per second during full migration), and target write BPS (maximum amount of data that can be written to the target per second during full migration). Note
The RPS and BPS values specified here are only for throttling and limiting capabilities. The actual performance of full migration is limited by factors such as the source, target, and instance specifications.
Handle Non-empty Tables in Target Database This parameter specifies the strategy for handling records in target table objects. Valid values: Stop Migration and Ignore. - If you select Stop Migration, data migration will report an error when target table objects contain data, indicating that migration is not allowed. Please handle the data in the target database before resuming migration.
Notice
If you click Restore after an error occurs, data migration will ignore this setting and continue to migrate table data. Proceed with caution.
- If you select Ignore, when target table objects contain data, data migration will adopt the strategy of recording conflicting data in logs and retaining the original data.
Notice
If you select Ignore, full verification will use the IN mode to pull data, which means it cannot verify scenarios where the target contains data not present in the source. This will result in a certain level of performance degradation.
Post-Indexing This parameter specifies whether to allow index creation to be postponed after full migration is completed. If you select this option, note the following items. Notice
Before you select this option, make sure that you have selected both Schema Migration and Full Migration on the Select Migration Type page.
- Only non-unique key indexes support index creation after migration.
If you allow index creation after full migration, we recommend that you adjust the following business tenant parameters using a command-line client tool based on the hardware conditions of OceanBase Database and current business traffic.
// File memory buffer size limit ALTER SYSTEM SET _temporary_file_io_area_size = '10' tenant = 'xxx'; // Disable throttling for OceanBase Database V4.x ALTER SYSTEM SET sys_bkgd_net_percentage = 100;- If you select Stop Migration, data migration will report an error when target table objects contain data, indicating that migration is not allowed. Please handle the data in the target database before resuming migration.
Incremental synchronization
In the Select Type & Objects step, select One-way Sync > Incremental Synchronization to display the following parameters.
ParameterDescriptionWrite Concurrency This parameter specifies the maximum number of concurrent writes during incremental synchronization, with a maximum limit of 512. Excessive concurrency may overload the target system, impacting business operations. Rate Limiting for Full Migration You can decide whether to limit the full migration rate based on your needs. If you enable this option, you must also set the source read RPS (maximum number of rows that can be read from the source per second during full migration), source read BPS (maximum amount of traffic that can be read from the source per second during full migration), target write RPS (maximum number of rows that can be written to the target per second during full migration), and target write BPS (maximum amount of data that can be written to the target per second during full migration). Note
The RPS and BPS values specified here are only for throttling and limiting capabilities. The actual performance of full migration is limited by factors such as the source, target, and instance specifications.
Incremental Synchronization Start Timestamp - If you selected Full Migration when choosing the migration type, this parameter will not be displayed.
- If you did not select Full Migration but selected Incremental Synchronization, specify the start time for data migration after a specific point in time. By default, it is set to the current system time. For more information, see Set the incremental synchronization start time.
Advanced options
This section is displayed only if the target OceanBase Database MySQL-compatible tenant is V4.3.0 or later, and Schema Migration was selected on the Select Type & Objects page.

The storage types of the objects in the target table include Default, Rowstore, Columnstore, and Mixed Row and Column Storage. This configuration determines the storage type for objects during schema migration or incremental synchronization.
Note
The Default option is adaptive to other options based on the target parameters. It writes the corresponding schema structure to the table objects during schema migration according to the specified storage type.
Click Pre-check to perform a pre-check on the data migration task.
In the Pre-check step, the system checks whether the read and write permissions of the database user and the network connection meet the requirements. You can only start the data migration task after all checks pass. If an error occurs during the pre-check:
You can troubleshoot and fix the issue, then rerun the pre-check until it succeeds.
Alternatively, you can click Skip in the Actions column of the failed pre-check item. A dialog box will appear, informing you of the specific impact of skipping this operation. After confirming that it is acceptable, click OK in the dialog box.
After the pre-check succeeds, click Purchase to go to the Purchase Data Migration Instance page.
After the purchase succeeds, you can start the data migration task. For more information about how to purchase a data migration instance, see Purchase a data migration instance. If you do not need to purchase a data migration instance at this time, click Save to go to the details page of the data migration task. You can manually purchase a data migration instance later as needed.
You can click Configure Validation Task in the upper-right corner of the details page to compare the data differences between the source database and the target database. For more information, see Create a data validation task.
The data migration service allows you to modify the migration objects when the task is running. For more information, see View and modify migration objects. After the data migration task is started, it is executed based on the selected migration types. For more information, see the "View migration details" section in View details of a data migration task.