

















Columnar engine
In scenarios involving large-scale data analytics or extensive ad-hoc queries, columnar storage stands out as a crucial feature of an analytical processing (AP) database. Columnar storage is a way to organize data files. Different from row-based storage, columnar storage physically arranges data in a table by column. When data is stored by column, the system can scan only the columns involved in the query and calculation, instead of scanning the entire row. This way, the consumption of resources such as I/O and memory is reduced and the calculation is accelerated. In addition, columnar storage naturally has better data compression conditions and usually offers a higher compression ratio, thereby reducing the required storage space and network transmission bandwidth.
OceanBase Database has focused on the log-structured merge-tree (LSM-tree) architecture from the very beginning. The database supports various types of typical transaction processing (TP) business based on continuous updates of features, and adapts to various extreme loads through continuous performance optimization. With abundant engineering practice and experience, OceanBase Database develops a set of cutting-edge fully featured storage engine based on the LSM-tree architecture. Online analytical processing (OLAP) scenarios generally involve batch writes with limited random updates to ensure that data in columnar storage is static. The LSM-tree architecture is naturally suitable for these scenarios.
Based on its technology accumulation, OceanBase Database extends the storage engine to support columnar storage in V4.3. This implements integrated row-column storage on one OBServer node with one set of code and one architecture, thus achieving a balance between the performance of TP queries and that of AP queries.
Overall architecture
As a native distributed database, OceanBase Database stores user data in multiple replicas by default. To leverage the advantages of multi-replica deployment and improve user experience in strong verification of data and reuse of migrated data, OceanBase Database makes several targeted changes in the design of the independently developed LSM-tree-based storage engine. First, user data is divided into the following two parts:
Baseline data
Unlike other databases with LSM-tree-based storage engines, OceanBase Database introduces the concept of daily major compaction based on distributed multi-replica deployment. A tenant selects a global version on a regular basis or based on your operation, and a major compaction is initiated for all replicas of tenant data based on the version to generate baseline data of the version. The baseline data of the same version is physically consistent for all replicas.
Incremental data
All user data written after the latest version of baseline data is incremental data. Incremental data can be memory data written into MemTables or disk data compacted into SSTables. Replicas of incremental data are maintained independently and are not necessarily consistent. Unlike baseline data that is generated based on a specified version, incremental data contains multi-version data.
Random updates in columnar storage scenarios are controllable. On this basis, OceanBase Database provides a set of columnar storage implementation methods transparent to upper-layer business based on the characteristics of baseline data and incremental data:
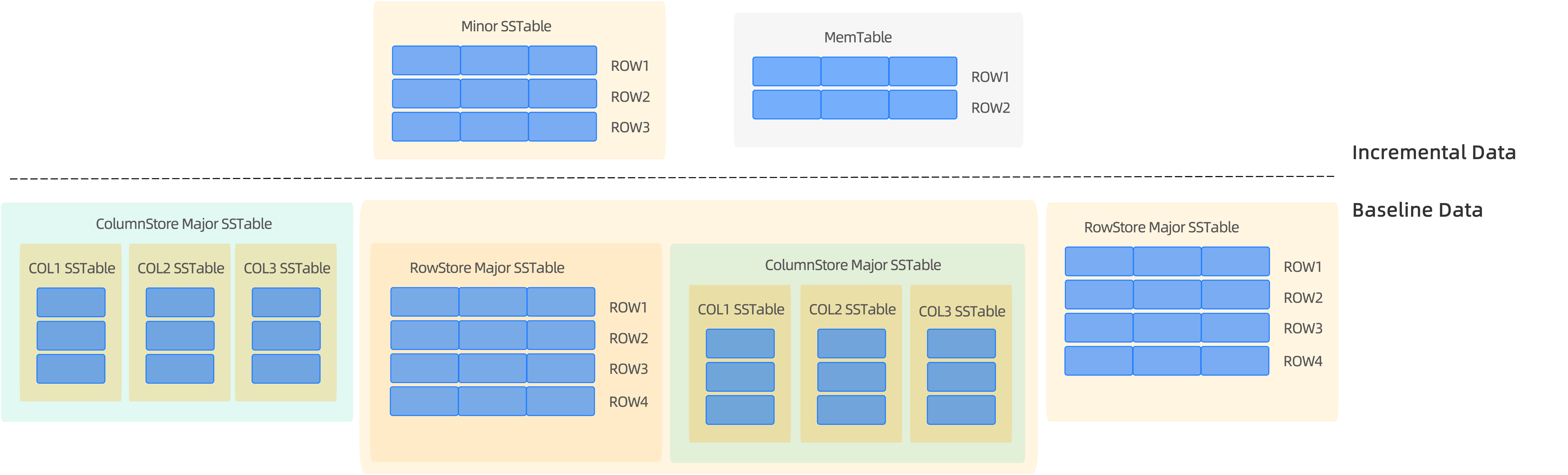
- Baseline data is stored by column, and incremental data is stored by row. Your DML operations are not affected, and upstream data and downstream data are seamlessly synchronized. You can perform transaction operations on columnstore tables the same way as on rowstore tables.
- In columnar storage mode, the data of each column is stored as an independent SSTable, and the SSTables of all columns are combined into a virtual SSTable as baseline data for columnar storage, as shown in the following figure.
- Based on the storage mode that you specified when you created the table, baseline data can be stored by row, column, or both row and column (with redundancy).
In addition to implementing the columnar storage mode in the storage engine, OceanBase Database optimizes and adapts the optimizer, executor, storage, and other related modules for columnar storage. This allows you to migrate data from other OLAP databases or upgrade your OceanBase Database to support columnar storage to meet your OLAP needs. The migration or upgrade have no impact on your business, and you can experience the same performance improvements as those brought by row-based storage after you switch to columnar storage. This way, OceanBase Database integrates TP and AP and provides a hybrid transaction/analytical processing (HTAP) engine to support different types of business with one engine and one set of code.
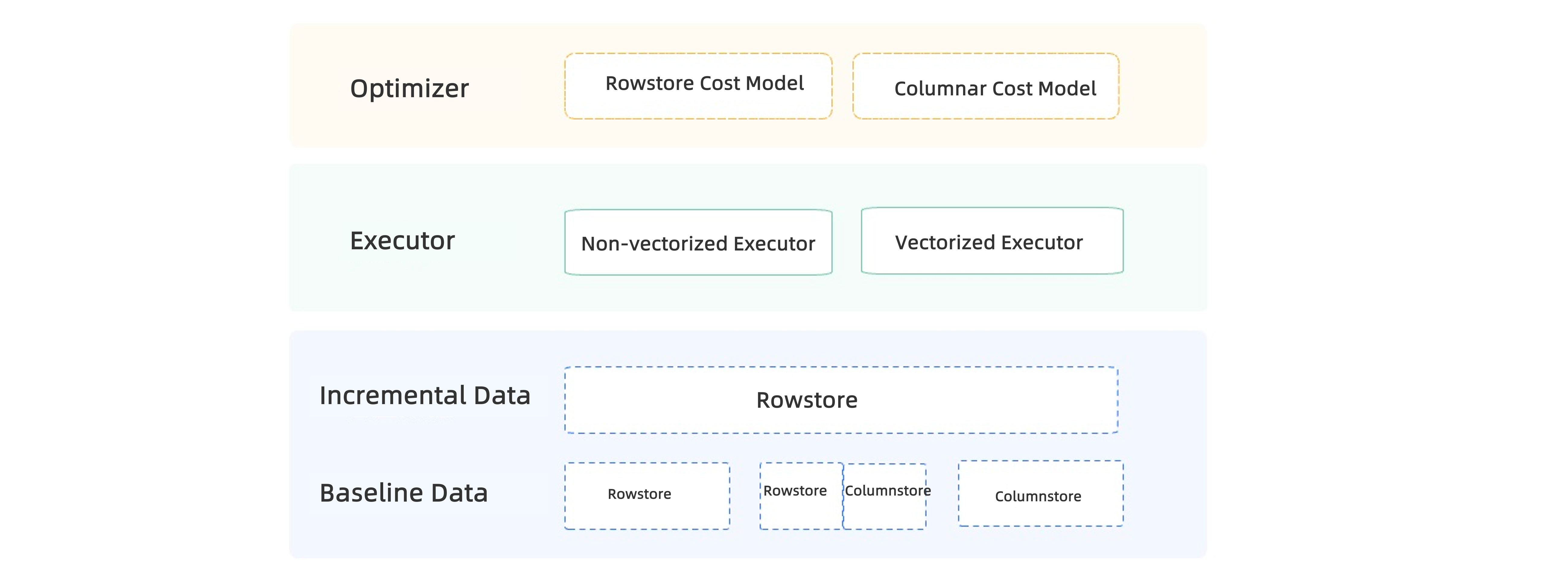
- Integrated SQL
- OceanBase Database provides a new cost model and statistics for columnar storage. The optimizer automatically selects a plan based on costs and the storage mode of data tables.
- OceanBase Database provides a new vectorized execution engine for critical operators, and adaptively determines whether to use vectorized execution and the batch size for vectorized execution.
- Integrated storage
- You can specify the columnar storage, row-based storage, or hybrid row-column storage mode for a table based on the type of its business load. The storage mode does not affect operations, such as queries and backup and restore, on the table.
- Columnstore tables support all online and offline Data Definition Language (DDL) operations, all data types, and secondary indexes. This ensures that you can use columnar storage the same way you use row-based storage.
- Integrated transactions
- Incremental data is stored by row. The logic of recording logs for data changes made in transactions and that of multiversion concurrency control (MVCC) are consistent with those in row-based storage.
Core features
Adaptive major compactions
Major compactions in columnar storage are significantly different from those in row-based storage. Specifically, incremental data is stored by row, and must be merged with baseline data before it is split and saved to a separate SSTable for each column. The compaction time and resource usage will significantly increase compared with those in row-based storage.
To speed up major compactions of columnstore tables, OceanBase Database greatly optimizes the compaction process. In addition to horizontal splitting and parallel major compactions as with rowstore tables, columnstore tables also support vertical splitting. Major compactions for multiple columns in a columnstore table are combined into one major compaction task. The database can automatically increase or decrease the number of columns in a task based on system resources. This achieves a balance between the major compaction speed and the memory overheads.
Column encoding algorithm
Data stored in OceanBase Database undergoes two stages of compression: hybrid row-column encoding provided by OceanBase Database and general compression. As a built-in algorithm of the database, hybrid row-column encoding supports direct queries without decompression. It also accelerates processing of queries, especially AP queries, based on encoded information.
Hybrid row-column encoding is designed mainly for row structures. Therefore, OceanBase Database provides a new column encoding algorithm for columnstore tables. Compared with the original encoding algorithm, the new algorithm supports comprehensive vectorized execution of queries, supports single instruction, multiple data (SIMD) optimization for compatibility with various instruction sets, and greatly increases the compression ratio for numeric types. This way, the new algorithm achieves great improvements in terms of the performance and compression ratio.
Skip index
Regular columnstore databases pre-aggregate column data at a specific granularity. The aggregation results are persisted along with the data. When you query or request to access column data, the database can filter data by using the pre-aggregated data. This significantly reduces data access overheads and I/O consumption.
OceanBase Database supports the skip index feature in the columnar engine. The data of each column is aggregated at the microblock granularity for calculating the maximum value, minimum value, and total number of NULLs. Then the aggregation and accumulation are performed upwards, layer by layer, to obtain values at the macroblock, SSTable, and larger granularities. When you initiate a query, the system continuously drills down to select aggregated values of the appropriate granularity based on the scan range to perform filtering and provide aggregated output.
Query pushdown
OceanBase Database preliminarily supports simple query pushdown since V3.2. OceanBase Database V4.x and later fully support vectorized storage and support more complex pushdown. In the columnar engine, the pushdown feature is further enhanced and expanded in the following aspects:
- All query filters are pushed down. At the same time, the database further utilizes the skip index feature and encoded information for speed-up based on the filter type.
- Regular aggregate functions are pushed down. Currently, the database can push down the
COUNT(),MAX(),MIN(),SUM(), andAVG()functions to the storage engine in scenarios without theGROUP BYoperator. - The
GROUP BYoperator is pushed down. For a column with a small number of distinct values (NDV), theGROUP BYoperator can be pushed down to the storage for calculation. This can significantly speed up calculation based on the dictionary information in microblocks.
For more information about columnar storage, see Columnar storage.
New vectorized engine
Vectorized execution is an efficient technique to process data in batches, which can greatly improve performance in analytical queries. The vectorized execution engine was introduced in OceanBase Database V3.2 and was disabled by default. Starting from OceanBase Database V4.0, the vectorized execution engine is enabled by default, and in V4.3, vectorized engine 2.0 is introduced. This significantly enhanced the performance of the vectorized engine by optimizing data formats, operators, and storage vectorization.
Optimization of data formats
Vectorized optimization of data formats is the core improvement in vectorized engine 2.0. In vectorized engine 1.0, after data is projected at the storage layer, a batch of data in a column expression is organized in memory in a format that consists of multiple continuous data description units and actual data. Each data description unit contains the nullability description, data length, and data pointer. Actual data values are not included in the data description units but stored at the address indicated by the data pointer. This data format causes the following problems to fixed-length data:
Inefficient read/write access
Each read/write access must obtain the data description unit first, and then access the data stored at the address indicated by the data pointer in the data description unit.
High memory usage
For example, if you want to store N rows of int32_t data, a total of N × (12+4) bytes of storage space are required, including 12 bytes for each data description unit and only N × 4 bytes for actual data. The storage space required increases by 4 times, resulting in higher overheads of memory access, data materialization, and data shuffling.
Inconvenience of SIMD computing
The actual data corresponding to a batch of data is not necessarily stored continuously, which makes SIMD computing inconvenient.
High serialization and materialization overheads
During data serialization and materialization, the data pointer must be swizzled, namely, converted into a relative offset.

To optimize the data formats in vectorized engine 1.0, vectorized engine 2.0 adopts new column-based data formats. The nullability description, data length, and data pointer are separately stored in continuous columns to avoid redundant data storage. Vectorized engine 2.0 supports three data formats for different data types and scenarios: fixed-length data format, variable-length discrete format, and variable-length continuous format.
Fixed-length data format
This data format consists of a null bitmap, continuous data, and length information. Only one length value is stored for one batch of data. The data pointer for indirect access is also omitted. Compared with the data format in vectorized engine 1.0, this data format does not contain redundant information, which saves storage space. It supports direct access to data and ensures good data locality. It also ensures continuous storage of data, which facilitates SIMD computing. In addition, during data serialization and materialization, the data pointer does not need to be swizzled, thus improving efficiency.
Variable-length discrete format
In this data format, a batch of data can be discontinuously stored in memory, and each piece of data is described by a data pointer and a data length that are separately stored in continuous columns. In this data format, if encoded data is stored at the storage layer, only the data length and data pointer need to be projected without deeply copying data. In a short-circuit operation, only a few rows in a batch of data are calculated. In this case, you can also describe the data in this format without reorganizing data.
Variable-length continuous format
In this data format, data is continuously stored in memory, and the length and offset address of each piece of data are described by an offset array. Compared with the variable-length discrete format, this data format requires continuous organization of data and is more efficient for data access and batch data copy. However, it is not friendly for short-circuit operations or projection of encoded column data because data must be reorganized and deeply copied. This data format is mainly used for column-based materialization.
Optimization of operator and expression performance
Vectorized engine 2.0 optimizes operators and expressions based on new formats. It properly uses attribute information of batch data and optimizes algorithms, data structures, as well as specialized implementations. This reduces CPU cache misses, CPU branch prediction errors, and CPU instruction overheads, and improves overall execution performance. Vectorized engine 2.0 redesigns and implements operators and expressions such as SORT, HASH JOIN, HASH GROUP BY, data shuffle, and aggregate computing based on new formats to comprehensively improve the computing performance.
Use of attribute information of batch data
Vectorized engine 2.0 maintains feature information of batch data during execution. The information indicates whether the data contains
NULLvalues and whether rows in the data are filtered. The vectorized engine can greatly accelerate expression evaluation based on such information. If the data does not containNULLvalues, the vectorized engine does not need to specially processNULLvalues during expression evaluation. If none of rows in the data are filtered, the vectorized engine does not need to determine whether each row is filtered during evaluation. In addition, SIMD computing is easier to implement because the data is continuous and not filtered.Optimized algorithms and data structures
To optimize algorithms and data structures, vectorized engine 2.0 adopts a more compact intermediate result materialization structure that supports row- and column-based data materialization. This saves storage space and improves access efficiency. The
SORToperator supports separate materialization of sort keys and non-sort keys. With ordered encoding of sort keys, theSORToperator has fewer cache misses when accessing the data cache during comparison. This speeds up comparison computing, and improves overall sorting efficiency. In ordered encoding, multiple columns of data are encoded into one column, and you can directly usememcpyto compare data. TheHASH GROUP BYoperator optimizes the schemas of hash tables so that data in hash buckets is organized in a more compact manner. It also optimizes low-cardinality group keys by using arrays and optimizes continuous storage of grouping and aggregation results in memory.Optimized specialized implementations
Vectorized engine 2.0 optimizes specialized implementations for different scenarios based on templates. For example, the specialized
HASH JOINoperator encodes multiple fixed-length join keys into one fixed-length column and stores the join keys in a bucket. Expectations for data are also optimized to reduce cache misses when multiple columns of data are accessed. The specialized aggregate computing performs different aggregate computing operations separately. This reduces the number of aggregate function instructions and branch judgments in each computation, greatly improving the execution efficiency.
Optimization of storage vectorization
The storage layer fully supports new vectorized formats. SIMD is more frequently used for projection, predicate pushdown, aggregation pushdown, and GROUP BY operator pushdown. Fixed-length data and variable-length data are projected in batches through shallow copying based on templates. The templates are customized based on the column type, the column length, and whether the data contains NULL values. After predicates are pushed down, simple predicates are directly computed in column encoding, and complex predicates are projected to new vectorized formats and computed in expressions by batch. Aggregation pushdown makes full use of pre-aggregated information, such as the COUNT, SUM, MAX, and MIN values, of intermediate layers. GROUP BY operator pushdown makes full use of encoded data and significantly accelerates the encoding of dictionary-type data.
Materialized views
Materialized views are a key feature for AP business scenarios. By precomputing and storing the query results of views, real-time calculations are reduced to improve query performance and simplify complex query logic. Materialized views are commonly used for rapid report generation and data analysis scenarios. Materialized views need to store query result sets to optimize the query performance. Due to data dependency between a materialized view and its base tables, data in the materialized view must be refreshed accordingly when data in any base tables changes. Therefore, the materialized view refresh mechanism is also introduced in the new version, including complete refresh and incremental refresh strategies. Complete refresh is a more direct approach where each time the refresh operation is executed, the system will re-execute the query statement corresponding to the materialized view, completely calculate and overwrite the original view result data. This method is suitable for scenarios with relatively small data volumes. Incremental refresh, by contrast, only deals with data that has been changed since the last refresh. To ensure precise incremental refreshes, OceanBase Database has implemented a materialized view log mechanism similar to that in Oracle databases, which tracks and records incremental update data of the base table in detail through logs, ensuring that the materialized view can be quickly incrementally refreshed. Incremental refresh is suitable for business scenarios with substantial data volumes and frequent data changes.
You can use materialized views in the following scenarios:
- Data summary: Sales data and user behavior statistics are summarized on a daily, weekly, or monthly basis.
- Generation of statistics reports: The report system needs to generate fixed-format data reports on a regular basis.
- Optimization of complex queries: You can materialize the results of resource-consuming queries, such as JOIN operations, to avoid repeated query computations.
- Data distribution.
- Pre-aggregation of monitoring metrics.
For more information about materialized views, see Overview (MySQL compatible mode) and Overview (Oracle compatible mode).
Real-time write
OceanBase Database is a high-performance and high-availability distributed relational database system that uses a unique storage architecture to meet the needs of modern applications. To cope with large-scale data write and analytical processing, OceanBase Database combines columnar storage and LSM-tree-based storage. This design ensures the real-time write capabilities of OceanBase Database and optimizes the performance of analytical queries. The following sections describe the real-time write capabilities of OceanBase Database in detail.
Core storage mechanisms
Columnar storage
OceanBase Database uses columnar storage to optimize its analytical processing capabilities. In columnar storage, data is independently stored in columns. This way, the system can efficiently read data from related columns when executing analytical queries. This greatly reduces unnecessary I/O operations and improves query efficiency. In addition, columnar storage facilitates data compression and encoding, thus improving utilization of data storage space.
LSM-tree-based storage
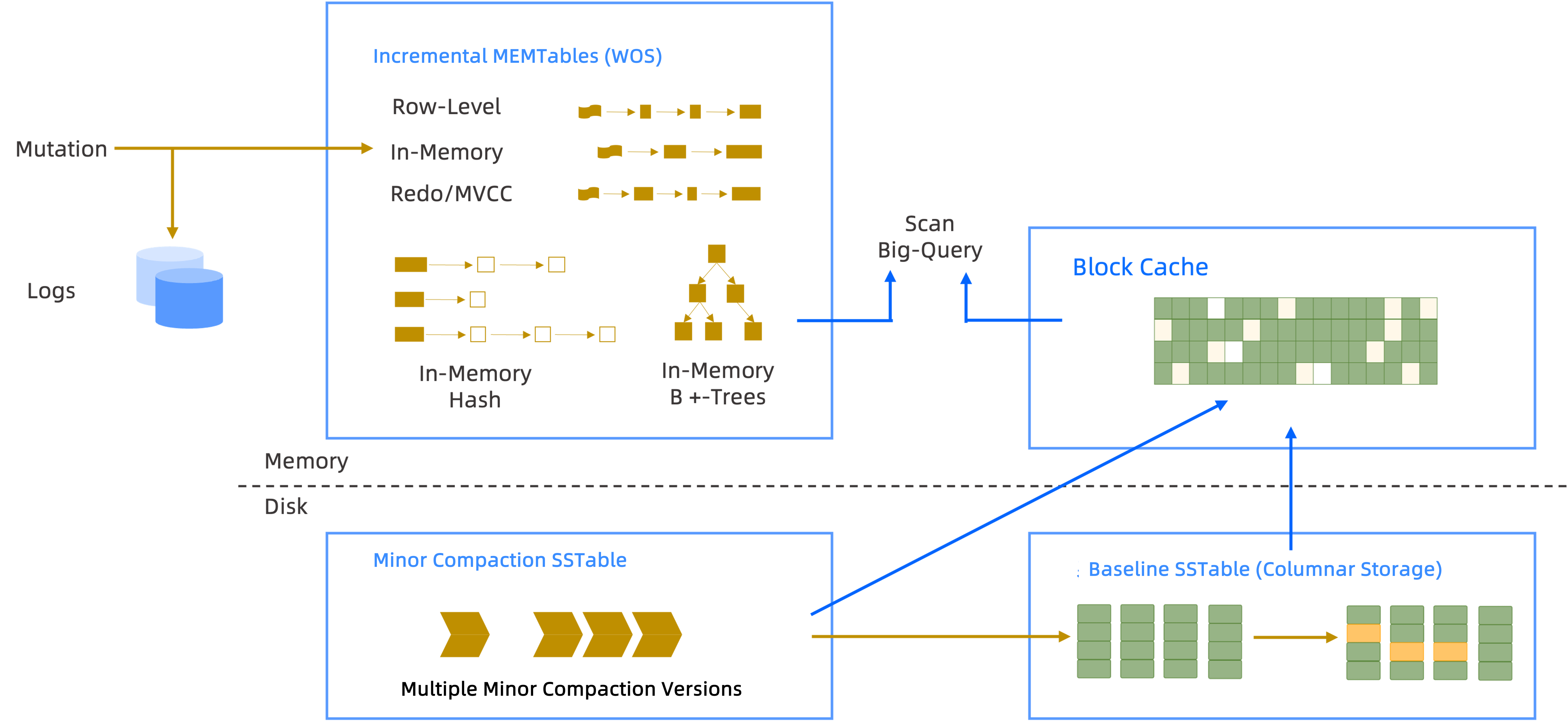
To support efficient real-time write, OceanBase Database stores incremental data based on the LSM-tree structure. The LSM-tree is a special tree structure designed to optimize write operations. It records write operations to the structures in memory and then asynchronously writes the records to the disk in batches when the number of records reaches the threshold. This greatly reduces the number of disk I/O operations and improves write performance. OceanBase Database regularly merges the incremental data with the baseline data through minor and major compactions to ensure data consistency and integrity.
Real-time write capabilities
OceanBase Database achieves excellent performance in real-time data write based on columnar storage and LSM-tree-based storage. It can quickly respond to both small-scale data updates and large-scale data import to ensure real-time data write. OceanBase Database has the following benefits in real-time data write:
- Efficient data write: The LSM-tree-based storage allows OceanBase Database to respond to write operations in a centralized manner. This reduces the number of disk operations and improves write efficiency.
- Immediate accessibility of data: Data is accessible immediately after it is written to the LSM-tree-based storage. This ensures the real-time performance of data.
- Optimized minor and major compactions: OceanBase Database uses intelligent minor compaction and major compaction strategies to keep the underlying data in an up-to-date and optimal state to support efficient queries.
- High-concurrency processing: The distributed architecture of OceanBase Database allows it to respond to write operations on multiple OBServer nodes in parallel. This greatly improves real-time data processing.
Compatibility with the MySQL ecosystem
In addition to excellent performance and scalability, OceanBase Database also boasts high compatibility with the MySQL ecosystem. This way, you can seamlessly migrate data from MySQL databases to OceanBase Database and make full use of the existing OLAP ecosystem tools and technology stacks to achieve rapid iteration and innovation of data analytics and business insights.
Syntax compatibility: OceanBase Database fully supports the standard SQL syntax in MySQL, including but not limited to DDL, Data Manipulation Language (DML), and Data Control Language (DCL) syntax. The data query, schema definition, index creation, and privilege management statements that you wrote in MySQL can be directly executed in OceanBase Database without substantial syntax modifications. This significantly reduces the migration costs and shortens the learning curve.
- Seamless data migration: You can quickly migrate your applications from MySQL databases to OceanBase Database with slight code modifications.
- Reusability of skills: MySQL developers and database administrators (DBAs) do not need to learn new database syntax, thus shortening the adaptation period.
- Ecosystem integration: The MySQL-compatible syntax of OceanBase Database allows it to integrate the existing business intelligence (BI), extract-transform-load (ETL), and data visualization tools.
View compatibility: OceanBase Database is compatible with the INFORMATION_SCHEMA views in MySQL.
- Table queries: OceanBase Database supports the
TABLESandCOLUMNSviews. You can query these views for the schemas and columns of all tables in the database. This is essential for data dictionary management and third-party tool integration. - Privilege management: OceanBase Database supports the
SCHEMATAandSCHEMA_PRIVILEGESviews. DBAs can query these views for the privileges on the database and tables and manage the privileges.
Many database management, monitoring, and analysis tools query the INFORMATION_SCHEMA views for the database status and architecture information. OceanBase Database is compatible with these views so that these tools can directly run in OceanBase Database without custom adaptation. OceanBase Database supports a variety of OLAP ecosystem tools, including:
BI tools
- Tableau: Tableau is a cutting-edge BI tool that is widely used for visual data analysis. The MySQL-compatibility of OceanBase Database allows Tableau to directly connect to the database and quickly build dashboards and reports by using SQL queries.
- Quick BI: Alibaba Cloud Quick BI is an efficient big data analysis and display tool for enterprises. It allows you to quickly build data portals and generate interactive reports, as well as flexibly analyze data, driving intelligent business decision-making. The MySQL-compatibility of OceanBase Database allows Quick BI to directly connect to the database.
- FineBI: FineBI is a self-service data analysis platform that provides powerful data processing and visual analysis capabilities. It supports multiple data sources and helps enterprises easily convert data into value. Its adaptation to OceanBase Database has been testified.
ETL tools
- Apache Flink: Apache Flink is an open-source framework for unified stream processing and batch processing. It supports data stream processing at a high throughput and a low latency, and supports event time and state management. Apache Flink is compatible with OceanBase Database. You can seamlessly integrate it in OceanBase Database for real-time data analysis and storage to enhance OLAP capabilities.
OceanBase Database is fully compatible with the OLAP ecosystem of MySQL. This ensures smooth data migration and allows you to make full use of a rich variety of OLAP ecosystem tools to accelerate data analysis and business decision-making without wasting original technology investments.
For more information about OLAP ecosystem integration of OceanBase Database, see Ecosystem integration.