

















OceanBase Database has been committed to the LSM-tree architecture since its inception, continuously refining its features to support a wide range of typical TP workloads, and continuously optimizing its performance to handle extreme load pressures. Through extensive engineering practice, OceanBase Database has developed a fully self-developed, highly distinctive, and industry-leading LSM-tree storage engine. In V4.3.0, building on its strong technological foundation, OceanBase Database extended its storage engine to support columnar storage, achieving integrated storage. This means that with just one OBServer node, you can seamlessly handle both row-based and columnar data. This advancement truly achieves a balance between TP and AP query performance.
Overall architecture
As a natively distributed database, OceanBase Database stores user data in multiple replicas by default. To leverage the advantages of multi-replica deployment and enhance user experience in aspects such as data integrity verification and reuse of migrated data, the self-developed LSM-tree-based storage engine has been designed with several targeted features. To begin with, user data can be divided into the following two parts:
Baseline data
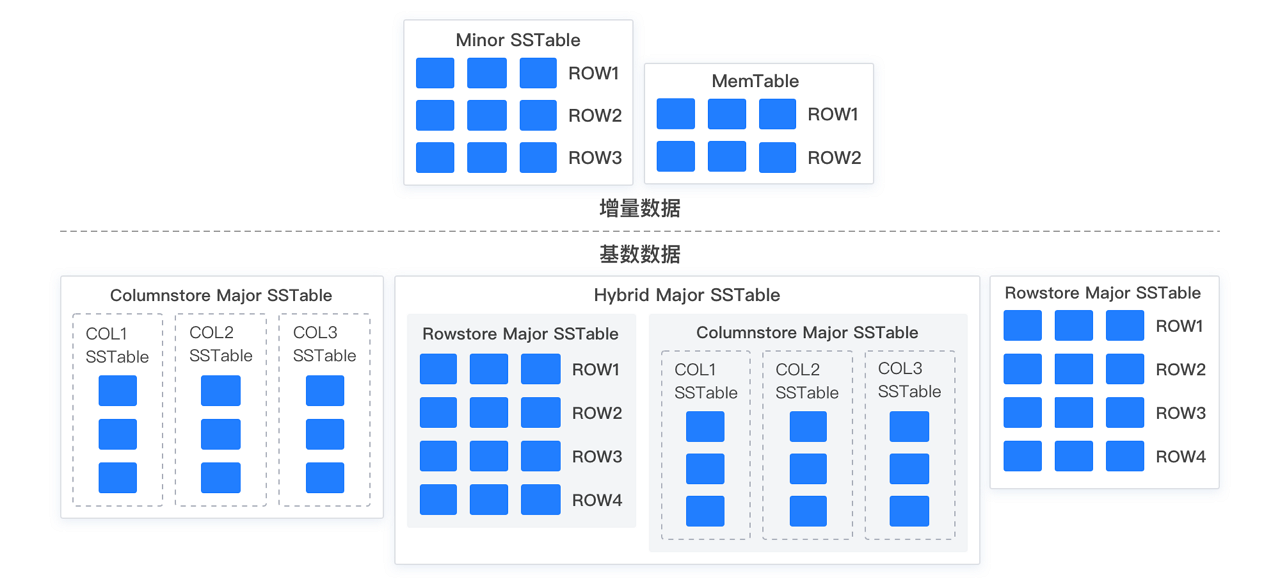
Unlike other mainstream databases that use the LSM-tree-based storage engine, OceanBase Database introduces the concept of "daily major compaction" based on its distributed multi-replica feature. Specifically, the system selects a global version number on a regular basis or based on user operations. Then, all replicas of tenant data complete a round of major compaction based on this version, generating baseline data for the specified version. The baseline data of all replicas for the same version is physically identical.
Incremental data
Relative to baseline data, all data written to the latest version of baseline data belongs to incremental data. Specifically, incremental data can be memory data newly written into the MemTable or disk data compacted into the SSTable. For all replicas of user data, each incremental replica is independently maintained, and consistency is not guaranteed. Unlike baseline data, which is generated based on a specific version, incremental data contains multi-version data.
Taking into account the controllable nature of random updates in columnar storage application scenarios, OceanBase Database has proposed a columnar storage implementation that is transparent to upper-layer applications, leveraging the characteristics of baseline and incremental data:
Baseline data is stored in columnar format, while incremental data remains in row format. This way, all user DML operations are unaffected, and upstream and downstream synchronization is seamless. Additionally, data in columnar tables can still support all transactional operations just like in row tables.
In columnar storage mode, each column of data is stored as an independent SSTable. The combination of all column SSTables forms a virtual SSTable, which serves as the columnar baseline data for the user. The following figure shows an example.
Based on the specified table storage mode when you create a table, the baseline data can be in one of the following three modes: row-based storage, columnar storage, or redundant row-column storage.
In addition to implementing columnar storage in the storage engine, OceanBase Database has also adapted and optimized the optimizer, executor, and other related modules for columnar storage to facilitate easier migration from other AP databases and help existing AP users upgrade to columnar storage. This way, users can seamlessly enjoy the performance benefits of columnar storage after migration without significant impact on their business. OceanBase Database thus truly achieves the integration of TP and AP, supporting different types of business with a single engine and codebase, and delivering a comprehensive HTAP engine.
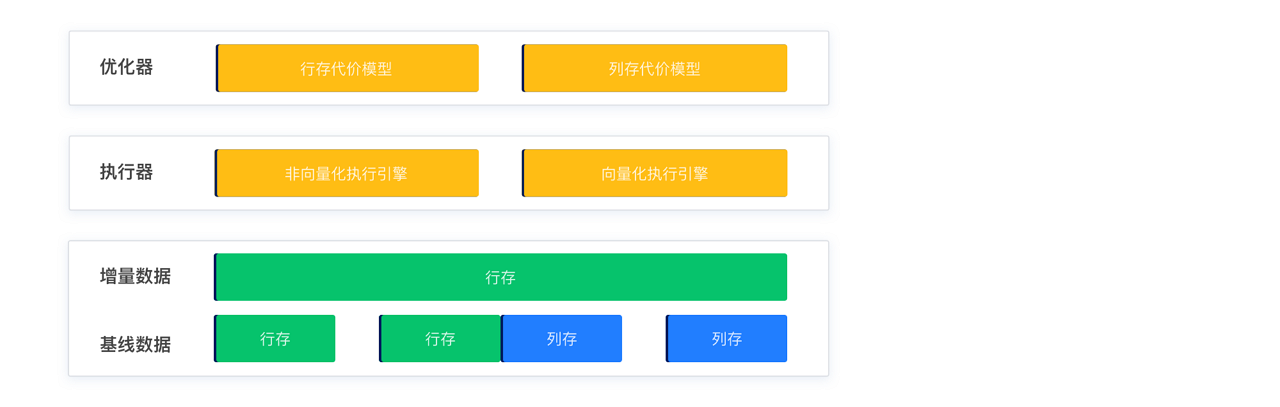
SQL integration
A new cost model has been designed and implemented for columnar storage, and relevant statistics have been added. The optimizer automatically selects execution plans based on the storage mode of data tables and cost.
A new vectorized execution engine has been implemented, and key operators have been restructured. Different execution plans adaptively choose vectorization and batch size based on cost.
Storage integration
You can flexibly set the storage mode of a table to columnar, row-based, or hybrid row-column based on the type of business workload. This change is transparent to users when they perform operations such as queries, backup, and restore.
Columnstore tables support all online and offline DDL operations, all data types, and secondary index creation, ensuring the same level of functionality as row-based storage.
Transaction integration
- Incremental data is entirely in row format. Modifications in transaction logs and multi-version control are consistent with those in row-based storage.
Core features
Adaptive compaction
With the introduction of the new columnar storage mode, the data compaction behavior has changed significantly from that of row-based data. Specifically, since all incremental data is row-based, it needs to be compacted with baseline data before being split into independent SSTables for each column. This results in a significant increase in compaction time and resource usage compared to row-based data.
To accelerate the compaction of columnar tables, OceanBase Database has significantly optimized the compaction process. For columnar tables, in addition to horizontal splitting for parallel compaction, vertical splitting is also supported. Multiple column compactions are grouped into one task, and the number of columns in a task can be dynamically adjusted based on system resources to maintain a good balance between compaction speed and memory usage.
Columnar encoding algorithm
OceanBase Database compresses stored data in two stages: hybrid row-column encoding compression and general compression. Hybrid row-column encoding is a built-in database algorithm that supports direct queries without decompression and uses encoded information for query filtering acceleration, especially significantly accelerating AP-type queries.
The existing hybrid row-column encoding algorithm, however, is still biased towards row organization. OceanBase Database has therefore developed a new columnar encoding algorithm specifically for columnar tables. Compared with the original algorithm, the new algorithm supports comprehensive vectorized execution for queries, SIMD optimization compatible with different instruction sets, and a significant increase in compression ratio for numeric data types, achieving overall performance and compression ratio improvements over the original algorithm.
Skip index
Most conventional columnar databases pre-aggregate each column of data at a certain granularity and persist the aggregation results. This way, when a user's query request accesses column data, the database can filter data using pre-aggregated data, greatly reducing data access overheads and unnecessary I/O consumption.
OceanBase Database also supports skip index for the columnar engine. It performs maximum value, minimum value, and null value aggregation on microblocks for each column and aggregates the microblock-level values to obtain macroblock-level and SSTable-level aggregation values. During a query, the system can drill down based on the scan range to select aggregation values of appropriate granularity for filtering and aggregated output.
Query pushdown
OceanBase Database has supported simple query pushdown since V3.2.x. From V4.x, storage has comprehensively supported vectorization and more pushdown features. In the columnar engine, pushdown features are further enhanced and expanded, specifically manifested in the following aspects:
All query filters are pushed down, and skip indexes and encoding information can be further used to accelerate queries based on filter types.
Common aggregate functions are pushed down. In non-group-by scenarios, aggregate functions such as COUNT(), MAX(), MIN(), SUM(), and AVG() can be pushed down to the storage engine.
Group By is pushed down. If the number of distinct values (NDV) of a column is small, Group By can be pushed down to storage for computation. Microblock dictionary information can be used to significantly accelerate the process.