

















OceanBase Database supports the shared-nothing (SN) architecture and the shared-storage (SS) architecture.
The distributed cluster architecture in shared-nothing mode is a common deployment method for OceanBase Database. In this mode, all nodes are equal, with each node equipped with its own SQL engine, storage engine, and transaction engine. This setup operates on a cluster of standard PC servers, delivering key advantages such as high scalability, availability, performance, cost-effectiveness, and strong compatibility with mainstream databases.
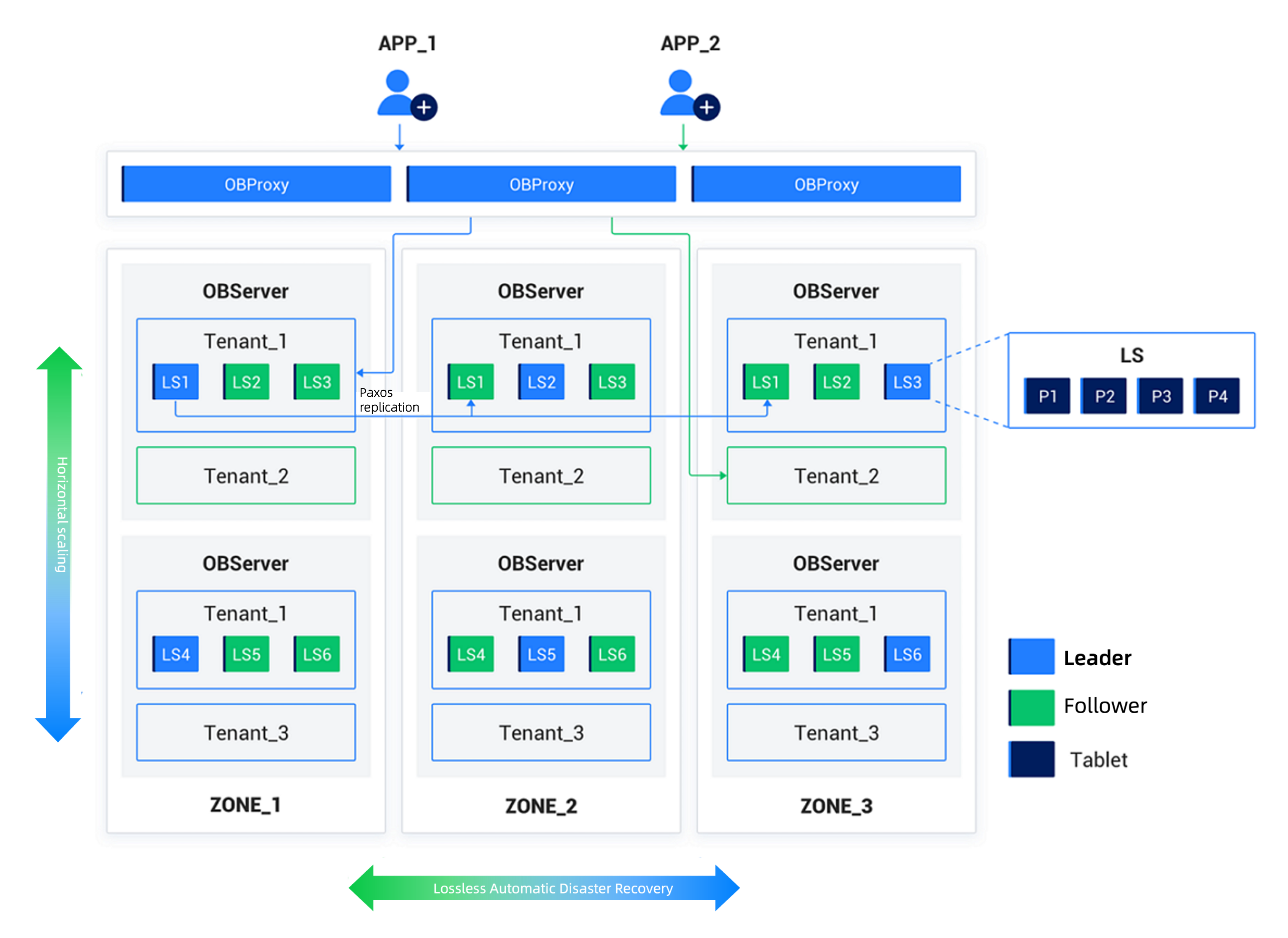
An OceanBase cluster consists of multiple nodes. These nodes are distributed across several zones, with each node belonging to one zone. A zone is a logical concept that represents a group of nodes that share similar hardware availability in the cluster. Its meaning varies depending on the deployment mode. For example, in a scenario where the cluster is deployed in one IDC, nodes in a zone can belong to the same rack or the same switch. If the cluster is deployed across IDCs, each zone can correspond to one IDC. Each zone has two attributes: IDC and region. These attributes specify the IDC in which the zone is located and the region to which the IDC belongs. Typically, the region refers to the city where the IDC is located. The IDC and region attributes of a zone should reflect the actual deployment circumstances to ensure the proper functioning of automatic disaster recovery mechanisms and optimization strategies within the cluster. To meet different high availability requirements of business for database systems, OceanBase Database offers various deployment modes. For more information, see HA deployment solutions for OceanBase clusters.
In OceanBase Database, data in a table can be horizontally divided into multiple shards based on a specified division rule. Each shard is known as a table partition or simply a partition. A row of data belongs to and only exists in one partition. You can specify partitioning rules when you create a table. Partitions of the hash, range, and list types, and subpartitions are supported. For example, you can divide an order table in a transaction database into several partitions by user ID, and then divide each partition into several subpartitions by month. In a subpartition table, each subpartition is a physical partition, while a partition is merely a logical concept. Multiple partitions of a table can be distributed across multiple nodes within a zone. Each physical partition has a storage layer object, called a tablet, for storing ordered data records.
When you modify data in a tablet, the system records redo logs to the corresponding log stream (LS) to ensure data persistence. Each log stream serves multiple tablets on the local node. To protect data and ensure service continuity when a node fails, each log stream and tablet have multiple replicas. Typically, multiple replicas of a log stream or tablet are distributed across zones. You can modify only one of the replicas, which is referred to as the leader. Other replicas are referred to as followers. Data consistency is ensured between the leader and followers based on the Multi-Paxos protocol. If the node where the leader is located is down, a follower is elected as the new leader to continue to provide services.
Each node in the cluster runs an observer process, which contains multiple operating system threads. All nodes provide the same features. Each observer process accesses data of partitions on the node in which it runs, and parses and executes SQL statements routed to the node. The observer processes on the nodes communicate with each other by using the TCP/IP protocol. In addition, each service listens to connection requests from external applications, establishes connections and database sessions, and provides database services. For more information about observer processes, see Threads.
OceanBase Database provides the unique multitenancy feature to simplify the management of multiple business databases deployed on a large scale and reduce resource costs. In an OceanBase cluster, you can create multiple isolated "instances" of databases, which are referred to as tenants. From the perspective of applications, each tenant is a separate database. In addition, you can create a tenant in MySQL- or Oracle-compatible mode. After your application is connected to a MySQL-compatible tenant, you can create users and databases in the tenant. The user experience is similar to that with a standalone MySQL database. In the same way, after your application is connected to an Oracle-compatible tenant, you can create schemas and manage roles in the tenant. The user experience is similar to that with a standalone Oracle database. After a new cluster is initialized, a tenant named sys is created. The sys tenant is a MySQL-compatible tenant that stores the metadata of the cluster.
Applicability
OceanBase Database Community Edition provides only the MySQL-compatible mode.
To isolate the resources of different tenants, each observer process can have multiple virtual containers known as resource units that belong to different tenants. A resource unit includes CPU and memory resources. The resource units of each tenant across multiple nodes form a resource pool.
To shield applications from internal details such as the distribution of partitions and replicas in OceanBase Database and make accessing a distributed database as simple as accessing a standalone database, we provide the OceanBase Database Proxy (ODP) service (also known as OBProxy). An application does not directly connect to an OBServer node. Instead, it connects to ODP. Then, ODP forwards SQL requests to an appropriate OBServer node. ODP is a stateless service, and multiple ODP nodes provide a unified network address to the application through network load balancing (for example, SLB).
To provide users with more cost-effective database services in multi-cloud environments, OceanBase Database implements the shared-storage architecture based on general-purpose object storage. This enables cloud-native database services on the cloud, reducing database usage costs while improving performance and usability. For more information, see Storage-compute separated system architecture.