
















Background information
As data volumes experience exponential growth, enterprises and organizations face increasingly severe challenges in database management. Declining performance, rising storage costs, and growing operational complexity are making data management significantly more difficult for DBAs and developers. To address these challenges, organizations require more granular lifecycle data management across four critical phases: online, nearline, archival, and disposal. Among these, historical database management during the nearline and archival phases proves particularly crucial.
Scenario
Historical data storage plays an important role in both nearline and archival phases. In the archival phase, databases or offline files can be used. For archived data that still requires a small amount of querying, a historical database solution is typically chosen. This solution is actually a strategy to separate hot and cold data, improving performance by reducing the load on the online database. The cold data in a historical database is usually accessed infrequently, so machine types with larger disk space and lower CPU configurations can be selected to achieve cost savings.
Many users seek an effective solution for managing large-scale historical data. They want to reduce costs without compromising performance and data availability. This topic will guide you through modernizing the architecture of your historical database and introduce how OceanBase can help optimize the management of your historical database.
Architecture
A historical database must meet the following requirements:
It must have sufficient storage space to store a large amount of data and efficiently and continuously import data from online databases.
It must be highly scalable to handle increasing amounts of data without modifying the storage architecture.
It must offer lower storage costs to store more data with fewer disks and less expensive storage media.
It must provide sufficient query capabilities to efficiently handle both transactional queries and analytical queries.
It must maintain the same application interface as online databases to reduce application complexity.
Given these requirements, OceanBase emerges as a natural choice. Its architecture combines elastic scalability (seamless standalone to distributed expansion) and HTAP capabilities (hybrid transactional/analytical processing). This allows OceanBase to efficiently support both online transaction systems and historical data repositories.
Moreover, OceanBase reduces storage costs by at least 50% compared to conventional solutions. Some customers report up to 80% cost savings after migrating historical data from other databases to OceanBase – a primary reason for its adoption in historical data scenarios.
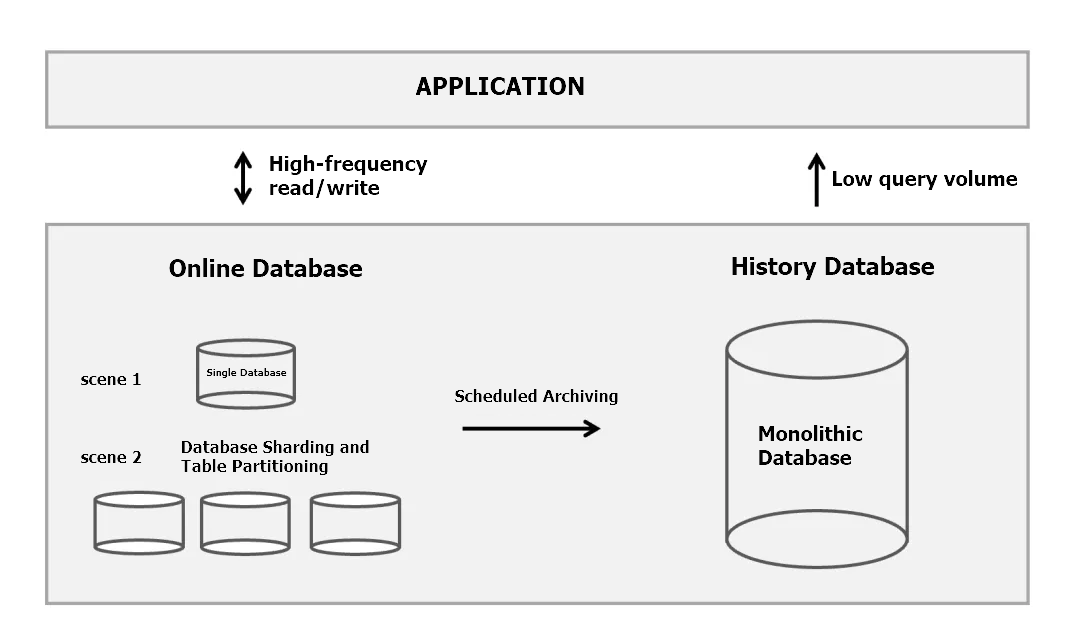
As OceanBase refines its historical database solution, several key architectural considerations emerge:
- Consistency with online database architecture
While online databases may adopt sharding architectures due to data scale and performance requirements, historical databases typically have lower performance demands. Depending on usage scenarios, maintaining identical architectures is not necessary. Sharding architectures impose additional costs for database deployment, maintenance, backup and restore. Particularly when using OceanBase as the historical database, a single table can easily support dozens of TBs of data. Even with large data volumes, partitioned tables can be used instead.
- Support for data updates
Technically feasible, historical databases can support updates or be configured as read-only. However, from a total cost perspective, implementing read-only historical databases is recommended. Read-only historical databases involve fewer random read/write operations, enabling the use of cheaper storage hardware (e.g., SATA disks instead of SSDs). Additionally, read-only historical databases reduce backup costs, requiring only one backup copy to be maintained.
- Minimizing impact on online databases
This is critically important. The online database is key to stable business operations. In large-scale data scenarios, bulk data reading, computation, and deletion can strain online databases. Therefore, the data archiving process must ensure online database stability.
Core capabilities of OceanBase data archiving
Separate hot and cold data to enhance online database performance
Generally, some business data is accessed less frequently or not at all after a period of time. This data, which is referred to as "cold" data, can be archived to a historical database, while only the data of the most recent period is retained in the online database.
The traditional data archiving methods consume a lot of time and human resources and are at risk of errors and data loss. In addition, manual archiving hinders efficient data management and flexibility of operations. To address these challenges, the data archiving feature was introduced in ODC from V4.2.0, aiming to improve data management efficiency and security.
You can use the data archiving feature of ODC to separate hot and cold data:
Log in to Web ODC.
Choose Ticket > Create Ticket > Data Archiving.
On the data archiving ticket creation page, specify the details of the ticket.
For example, the following figure shows a data archiving task that archives the tb_order table from an online database to a historical database. The option to clear archived data in source database is also selected so that the archived data in the source database is cleared after the archiving is completed. For more information, see Archive data.
Notice
Here, the variable archive_date is used, which is set to a time value of 1 year prior to the current time. By referencing this variable in the filtering condition, each execution of the archiving task will automatically archive data that is exactly 1 year old.
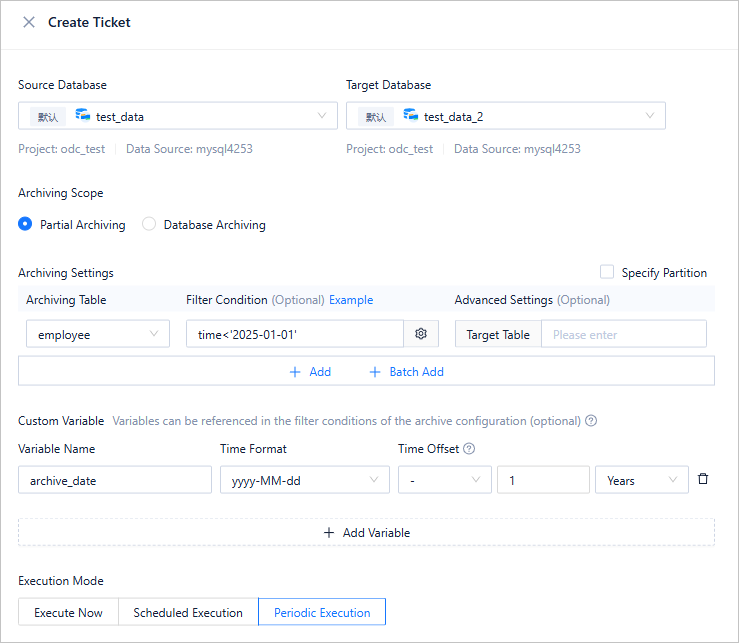
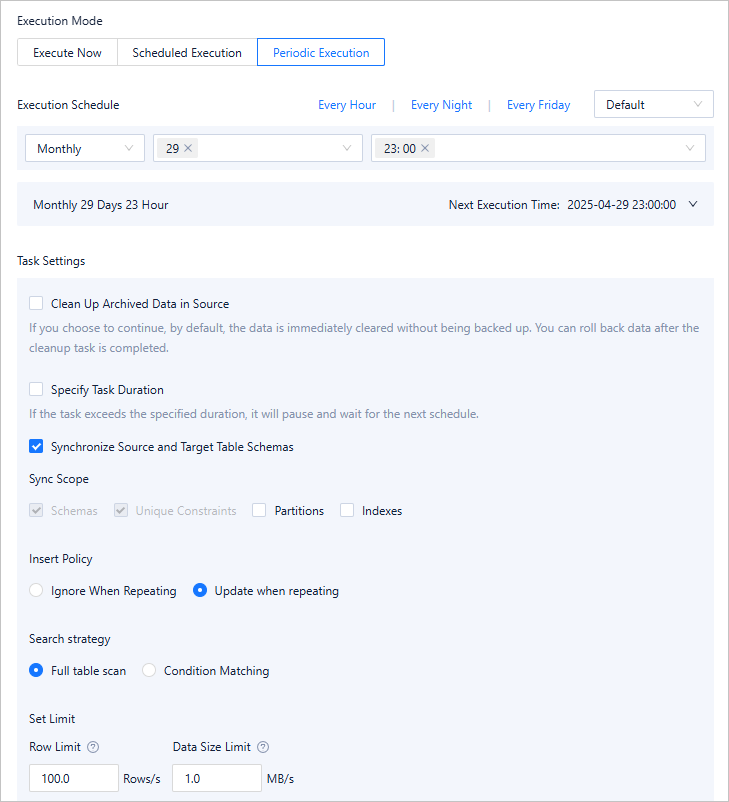
ODC supports various execution scheduling strategies for data archiving, including immediate execution, scheduled execution, and periodic execution. You can also configure schema synchronization, data insertion, and flow control for data archiving. During schema synchronization, you can choose to synchronize partitions and indexes. Historical databases may have different partition designs from online databases, and the query requirements of historical databases and online databases can also differ. By using fewer indexes, you can further reduce the storage costs.
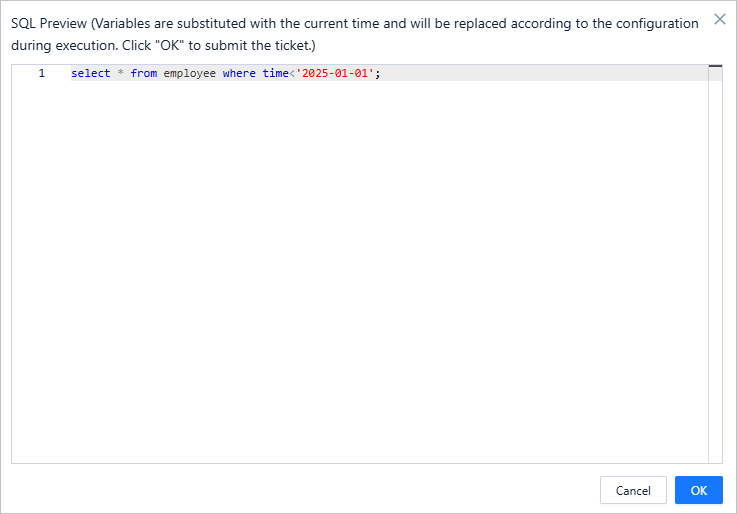
After you click Create Task, the preview of the archiving SQL statement is displayed, allowing you to confirm the data range to be archived. With the data archiving task of ODC, you can successfully archive cold data from an online database to a historical database with minimal configuration, achieving hot/cold data separation in the online database.
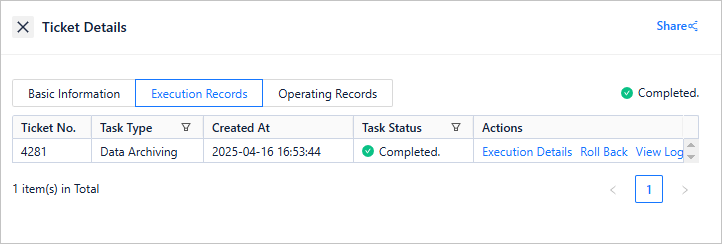
In future scenarios, if business changes or errors occur, you may need to restore the data from the historical database to the online database. ODC offers an easy-one-click rollback feature. For example, assume that you need to restore the data that was archived earlier to the online database. On the execution record page, you can click the rollback button next to the data archiving task record to initiate a rollback task.
Purge expired data to reduce storage costs
The data archiving feature of ODC allows you to separate hot and cold data in online databases and migrate the cold data to a historical database to reduce costs and improve efficiency. In practice, cold data stored in the historical database does not need to be retained permanently. Some cold data, such as log data, may become expired after a period of time and will never be used again. If this expired data is promptly purged, the storage costs can be further reduced. To address this, ODC provides a data cleanup feature to periodically purge expired data from databases, thereby optimizing storage resources.
Log in to the ODC console.
Choose Ticket > Create Ticket > Data Cleanup.
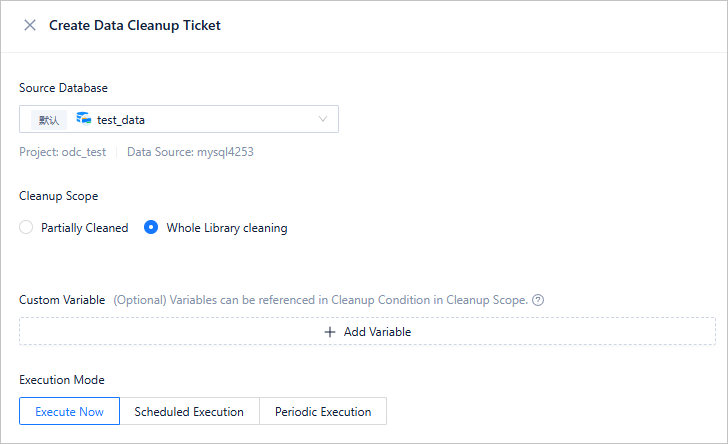
The data cleanup ticket creation page appears. The configuration of a data cleanup ticket is similar to that of a data archiving ticket. The following example shows a data cleanup ticket configured to run on a periodic basis. For more information about all configurations, see Clean up data.
Note
ODC also supports triggering a data verification task in the historical database before data is purged.
End-to-end data archiving link
As of ODC V4.3.4, the following data archiving links are supported:
OceanBase MySQL Compatible Mode/MySQL Online Database → OceanBase MySQL Compatible Mode Historical Database
OceanBase Oracle Compatible Mode/Oracle Online Database → OceanBase Oracle Compatible Mode Historical Database
OceanBase MySQL Compatible Mode/MySQL Online Database → MySQL Historical Database
OceanBase Oracle Compatible Mode/Oracle Online Database → Oracle Historical Database
PostgreSQL Online Database → OceanBase MySQL Compatible Mode Historical Database
OceanBase MySQL Compatible Mode, OceanBase Oracle Compatible Mode, MySQL, Oracle, PostgreSQL → Object Storage (OSS, COS, OBS, S3)
ODC is available in the following editions:
Web Edition for private cloud, which can connect to OceanBase Database Community Edition, Enterprise Edition, or OceanBase Cloud.
OceanBase Cloud version, which provides the data archiving capability of ODC in the OceanBase Cloud console. You can purchase OceanBase Cloud service and start using ODC's data archiving feature immediately.
Core technologies of OceanBase data archiving
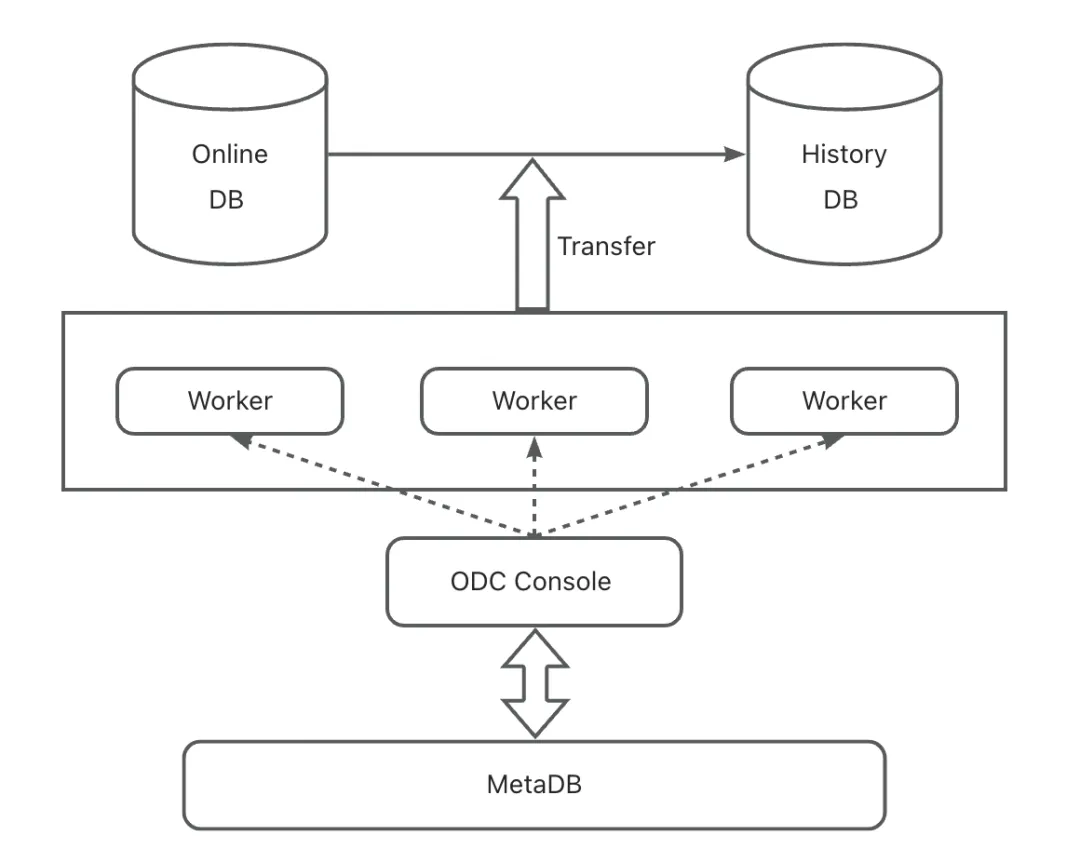
To ensure the stability, speed, and accuracy of data archiving, especially in large-scale data scenarios, ODC data archiving introduces features such as multi-dimensional rate limiting, shard-based parallel processing, data verification, and checkpoint recovery. The following figure shows the technical architecture of data archiving, which comprises three components:
Worker (task executor, responsible for executing the task logic)
MetaDB (used to store the metadata of the task, ensuring high availability using OceanBase Database)
ODC Console (the entry for user operations, used for task scheduling and management)
Multi-dimensional rate limiting to ensure online database stability
ODC data archiving employs both active and passive rate limiting strategies to maximize the performance stability of online databases.
Active rate limiting includes throughput limits and row count limits, applied to both read and write operations. Throughput limits prevent network card overload from excessive traffic or resource exhaustion due to high-speed operations. Row count limits control excessive RPS (requests per second) that could impact DRC (Data Replication Control).
Passive rate limiting continuously monitors the CPU and memory usage of the source database during task execution. When predefined thresholds are reached, the task executor enters a dormant state until metrics return to acceptable levels. This effectively manages resource consumption, ensuring tasks proceed under optimal conditions.
Shard-based parallel processing for high-performance archiving
As data volumes grow exponentially, archiving efficiency becomes critical. ODC improves performance through a primary key-based sharding strategy. This divides the target table's data into smaller subtasks processed concurrently by multiple threads, significantly accelerating archiving operations.
Verify before delete to ensure historical data integrity
The database is the ultimate guarantee of consistency. Even for historical databases, the validity and integrity of historical data must be ensured. Currently, ODC's data archiving tasks provide an additional layer of consistency verification when cleaning online database data. Before deleting data, ODC pulls data from both the online and historical databases for comparison. Only data that meets the consistency policy is allowed to be deleted, ensuring there is no risk of data loss. The current data consistency verification strategy uses full-field equality comparison - only when the online and historical database data are completely identical will ODC permit deletion of the online database data. Similar to data migration, data deletion is also performed with a memory exhaustion prevention mechanism to ensure system stability.
Checkpoint recovery to meet large-scale data scenario requirements
In large-scale data scenarios, when tasks experience unexpected termination or require manual interruption, the cost of restarting tasks is often unacceptable. Therefore, it must meet the reliability requirements of archiving in large-scale data scenarios.
ODC data archiving provides checkpoint recovery capability, allowing tasks to quickly resume from the most recent checkpoint record. The implementation principle is based on shard processing of archive tables. Each subtask maintains a sliding window, and each transaction row group is placed in the sliding window after generation. Since the data reading thread of subtasks is single-threaded, these transaction row groups maintain the same order in the sliding window as their generation order. After a transaction row group is fully processed, it is marked as completed. When the earliest task in the sliding window is completed, a window "shift" occurs until the earliest task in the window is in an incomplete state. With each window shift, the last row of the shifted-out transaction row group becomes a checkpoint. For each running subtask, its checkpoint information is periodically reported to the database. If a task terminates for any reason, other nodes can continue the task by obtaining each subtask's checkpoint information from the database and resuming from the checkpoint position. The subtask generation thread also has a similar checkpoint resumption mechanism.
Real-world historical database implementation cases
Currently, over 100 customers including Alipay, Trip.com, Energy Monster, and MYBank have upgraded their historical database architecture using OceanBase, achieving remarkable results.
Alipay upgraded its historical database architecture through OceanBase, achieving PB-level data archiving and unlimited horizontal expansion, with overall storage costs reduced by 1/3 and total data storage costs decreased by 80%. As of now, Alipay has established over 20 historical database clusters, with a coverage of nearly all core businesses including transactions, payments, top-ups, membership, and accounting. The total data volume reaches 95 PB, with a monthly new data growth of 3 PB. Among these, the largest transaction payment cluster group has reached 15 PB in data volume, with daily data increments up to 50 TB. This historical database upgrade has brought Alipay significant benefits:
Significant cost reduction: The historical database uses lower-cost SATA drives to build OceanBase database clusters, reducing per-unit disk space costs to 30% of online machines. It also uses the higher compression ratio zstd algorithm to reduce overall costs by 80%. For online databases using systems like MySQL or Oracle, cost reductions are even more significant because OceanBase's data encoding, compression and LSM-Tree storage architecture makes storage costs only one-third of traditional databases.
Elastic scaling reduces maintenance costs: The historical database adopts OceanBase's three-replica architecture, with multiple OBServers in each zone distributing data across multiple units through partitioning. OceanBase has business-unaware elastic scaling capabilities that can increase capacity and performance through node expansion. This means historical databases are no longer limited by disk size, with fewer clusters able to cover all business historical databases, reducing maintenance costs.
Strong data consistency and rapid fault recovery: Data migration serves as both data archiving and logical backup. For financial businesses requiring auditing and historical data queries, data consistency is crucial. OceanBase uses the Paxos consistency algorithm at its foundation. When a single OBServer fails, it can recover quickly within 30 seconds while ensuring strong data consistency. This minimizes impact on online queries and archiving tasks.
Additionally, MYBank saved over 10 million RMB in hardware costs through OceanBase's historical database solution. And Trip.com reduced storage costs by 85% compared to their previous MySQL solution using OceanBase's historical database approach. Energy Monster achieved a 71% reduction in storage costs after migrating their historical database to OceanBase.