

















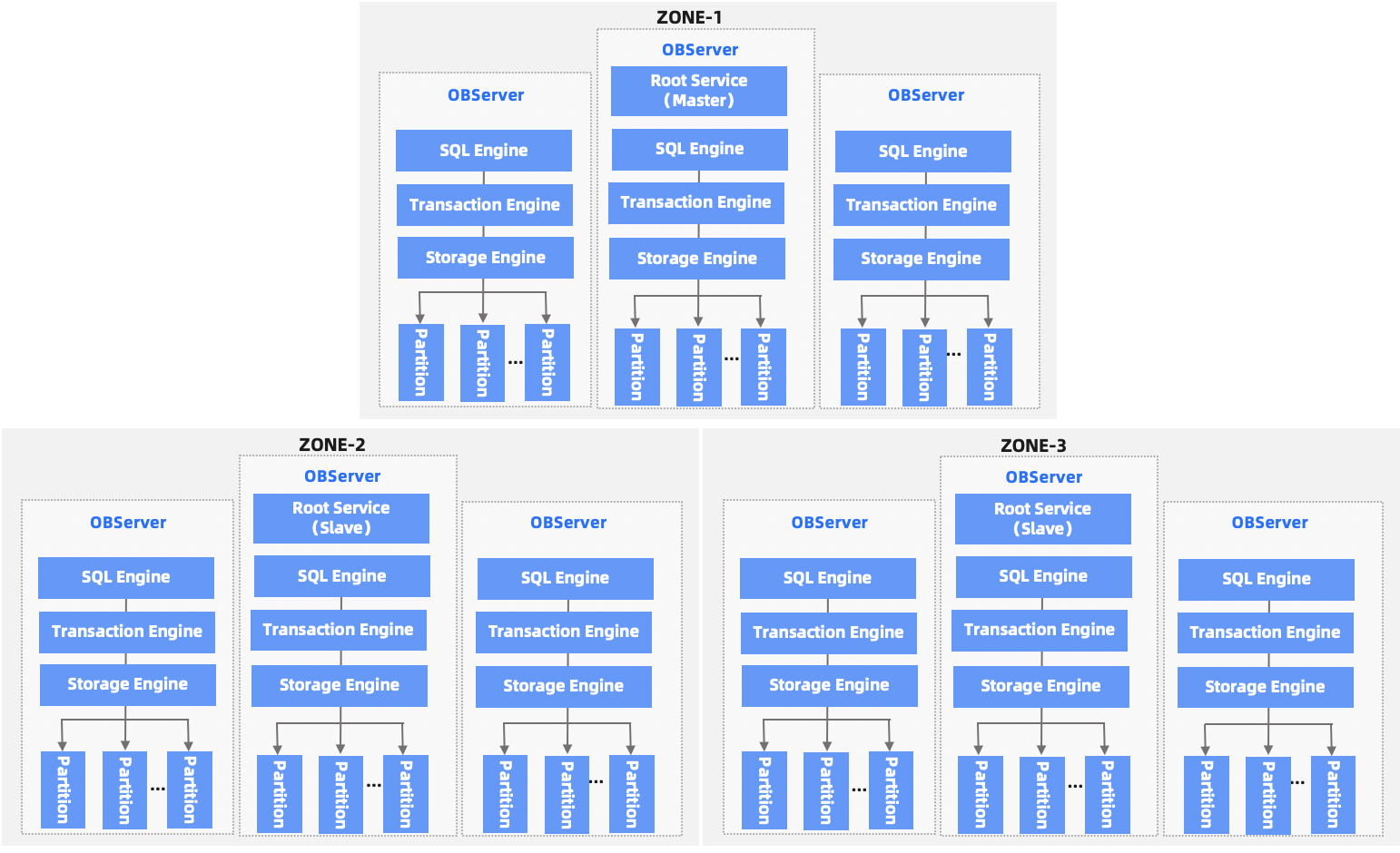
OceanBase Database is a distributed database system that processes massive amounts of transactions. OceanBase Database uses the concept of zone, which refers to a group of servers in an IDC, including multiple OceanBase Database servers (OBServers). Each OBServer runs an SQL engine, transaction engine, and storage engine and serves multiple data partitions. Each zone has an OBServer that runs the RootService to perform operations such as cluster management, server management, and automatic load balancing. The SQL engine parses and optimizes your SQL queries and converts them to internal calls to be sent to the transaction engine and storage engine. For cross-server operations, OceanBase Database also performs highly consistent distributed transactions to implement the atomicity, consistency, isolation, and durability (ACID) properties on distributed clusters.
OceanBase Database adopts the Shared-Nothing architecture to implement node peering. Each node has its SQL engine, transaction engine, and storage engine, and is run on a cluster of ordinary PC servers. This architecture provides core features such as scalability, high availability, high performance, and low cost.
Cluster architecture
OceanBase Database supports cross-region data deployment. The regions can be cities far away from each other. Therefore, OceanBase Database supports multi-city deployment and multi-city disaster recovery. A region can contain one or more zones. A zone is a logical concept. It contains one or more servers on which the OBServer process runs. A server where the OBServer process runs is an OBServer. Each zone retains one replica (full-featured replica or log replica). As the data replicas of OceanBase Database are organized in partitions, the data of the same partition is retained by multiple zones. The server where the active replica of each partition is located is called the leader, and the zone where the server is located is called the primary zone. If you do not specify a primary zone, the system automatically selects one of the full-featured replicas as the leader based on the load balancing policy.
Each zone provides two services: RootService and PartitionService. Each zone has an OBServer running the RootService and this server is also known as the RootServer (RS). However, each cluster has only one primary RS and RSs in other zones run as the standby RSs. The RootService is responsible for resource scheduling, resource allocation, data distribution management, and schema management in the entire cluster. The following list describes the features in detail:
Resource scheduling refers to the process of adding or deleting OBServers to or from the cluster and creating resources in OBServers for users, such as resource configuration and tenants.
Resource allocation refers to the migration of various resources (such as units) between zones or OBServers.
Data distribution management refers to the process that the RootService determines the location for data distribution. For example, the RootService determines the OBServers to which the data of a partition is to be distributed.
Schema management refers to the process that the RootService schedules and manages various DDL statements.
PartitionService is responsible for running the management and operation module of partitions in each OBServer. This module frequently calls the transaction engine and storage engine.
Based on the Paxos distributed election algorithm, OceanBase Database provides high availability at the partition level. In an OceanBase cluster, the data of each partition is replicated and stored in all zones. Data replicas of different partitions in the cluster are synchronized through the Paxos protocol. Each data partition and its replicas make up an independent Paxos replication group. In this group, one partition serves as the leader and the others are followers. All write requests to this replica are automatically routed to the corresponding leader partition. The leader partition can be distributed on different OBServers. Therefore, write operations on different replicas can be distributed to different data nodes. This enables multi-node data writing and improves system performance.
Storage engine
The storage engine of OceanBase Database adopts the LSM-Tree-based architecture, where baseline data and incremental data are stored in SSTables and MemTables respectively. This architecture separates read and write operations. You can only modify incremental data in MemTables. Therefore, all DML operations are performed on MemTables, providing excellent performance. The incremental data in the memory may be different from the baseline data in the persistent storage. OceanBase Database merges the incremental data and the baseline data to ensure that the latest data can be read.
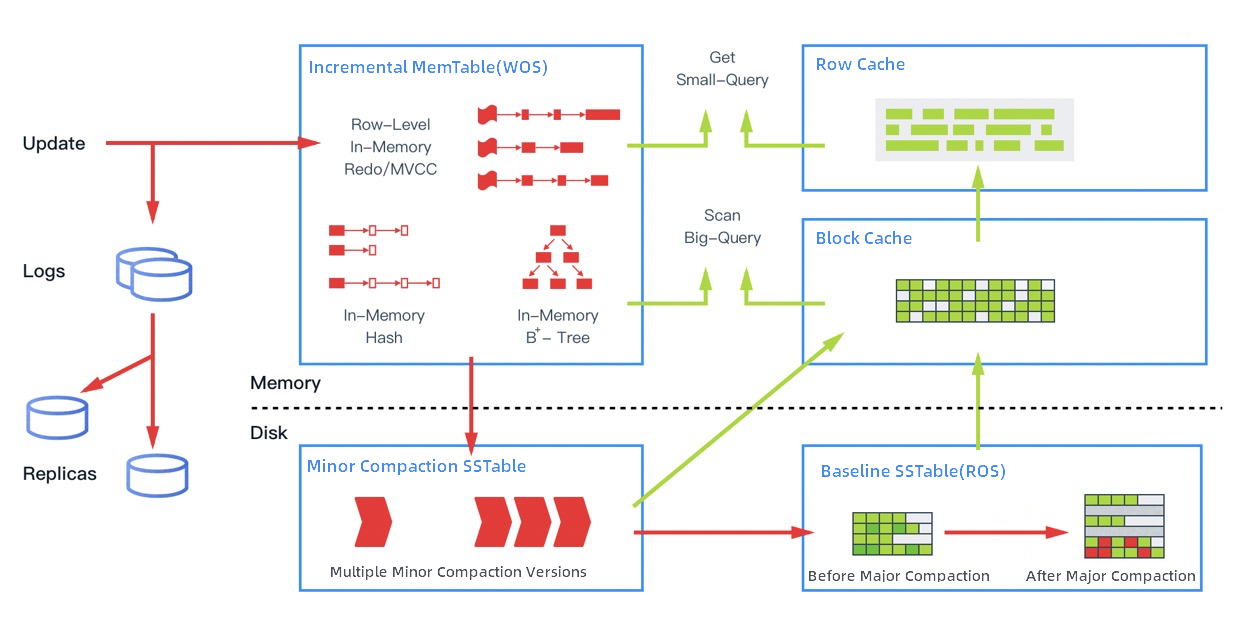
As shown in the preceding figure, OceanBase Database provides multiple cache structures to handle different types of in-memory data access. In addition to caching data blocks, OceanBase Database also caches rows, which can boost the performance of single-row queries. To avoid querying for rows that do not exist, OceanBase Database provides Bloom filters for row caching and caches the Bloom filters. Most online transaction processing (OLTP) operations are small queries. In traditional databases, entire data blocks must be parsed. OceanBase Database optimizes small queries to avoid parsing entire data blocks. This offers the performance close to that of in-memory databases. When the incremental data in the memory reaches a specific size, the incremental data is merged into the baseline data in the disks. The system performs a daily major compaction during idle hours every night. In addition, OceanBase Database supports different compression algorithms for different types of data, because the baseline data is read-only and is continuously stored in OceanBase Database. This ensures a high compression ratio and greatly reduces the cost without affecting the query performance.
SQL engine
The SQL engine of OceanBase Database is the data computing hub of the entire database. Similar to SQL engines of conventional databases, the SQL engine of OceanBase Database consists of a parser, an optimizer, and an executor. After the SQL engine receives an SQL request, it performs syntax parsing, semantic analysis, query rewriting, and query optimization on the request. Then, the executor executes the optimized request. The difference is that in distributed databases, the query optimizer generates distributed execution plans based on the data distribution information. To query data that is stored on multiple servers, you must use a distributed execution plan. This is a key feature of the SQL engine of distributed databases and requires a high-performance query optimizer. The query optimizer of OceanBase Database has been optimized in many aspects, such as operator pushdown, intelligent connection, and partition pruning. For SQL queries that involve a large amount of data, the query execution engine of OceanBase Database also optimizes the features such as parallel processing, task splitting, dynamic partitioning, flow scheduling, task pruning, subtask result joining, and concurrency limit setting.
The following figure shows the execution process of an SQL statement and the relationship among the modules of the SQL engine.
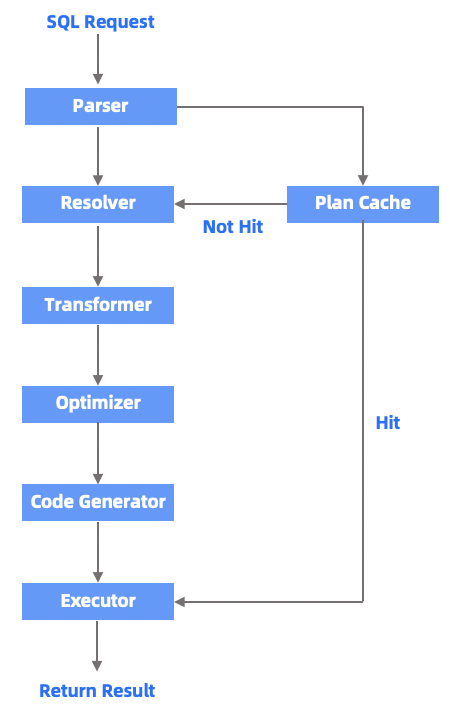
Parser (lexical and syntactic parsing module)
After Parser receives an SQL query string sent by a user, it splits the string into "words" and parses the entire query based on the preset syntax rules. Then, it converts the SQL query string into an in-memory data structure with syntax structure information, which is called the syntax tree.
To speed up SQL query processing, OceanBase Database uses the unique "fast parameterization" technique to speed up the search for execution plans.
Resolver (semantic parsing module)
Resolver converts the syntax tree generated by Parser into an internal data structure with database semantic information. During the conversion, Resolver translates tokens in the SQL query into the corresponding objects (such as libraries, tables, columns, and indexes) based on the database metadata to generate a statement tree.
Transformer (logic rewriting module)
During query optimization, OceanBase Database rewrites SQL queries of users into equivalent SQL queries to help Optimizer generate the best execution plans. This process is called "query rewrite". After Resolver generates the statement tree, Transformer analyzes the semantics of the user SQL query and rewrites it into an equivalent query based on internal rules or cost models. Then, Transformer sends the equivalent query to Optimizer for optimization. In this process, Transformer performs an equivalent transformation on the original statement tree, and the result of the transformation is still a statement tree.
Optimizer
As the core of the SQL optimization process, Optimizer generates the optimal execution plans for SQL queries. During the optimization, Optimizer needs to comprehensively consider various factors, such as SQL query semantics, object data characteristics, and physical distribution of objects. It solves many problems such as access path selection, connection order selection, connection algorithm selection, and distributed plan generation. Finally, it selects the best execution plan for each SQL query. The SQL execution plan is like an execution tree that consists of multiple operators.
Code Generator
Optimizer is responsible for generating the best execution plans, but OceanBase Database cannot execute these plans before they are converted into executable code by Code Generator.
Executor
After Code Generator generates the code for the execution plan of an SQL query, Executor executes the execution plan of the SQL query. The logic of Executor varies with the types of execution plans. For local execution plans, Executor starts by calling the operator at the top of each execution plan. The operator logic completes the entire execution process and returns the execution result. For remote or distributed plans, Executor divides the execution tree of each plan into multiple schedulable sub-plans and sends these sub-plans to the relevant nodes for execution through remote procedure calls (RPCs).
Plan Cache (cache module for execution plans)
The generation of execution plans is complex and time-consuming. The time consumption cannot be ignored, especially in OLTP scenarios. The SQL execution engine caches the execution plan generated for every unique SQL query in the memory to speed up the SQL query processing. The cached plans can be repeatedly executed in the future, which avoids repeated query optimization.