

















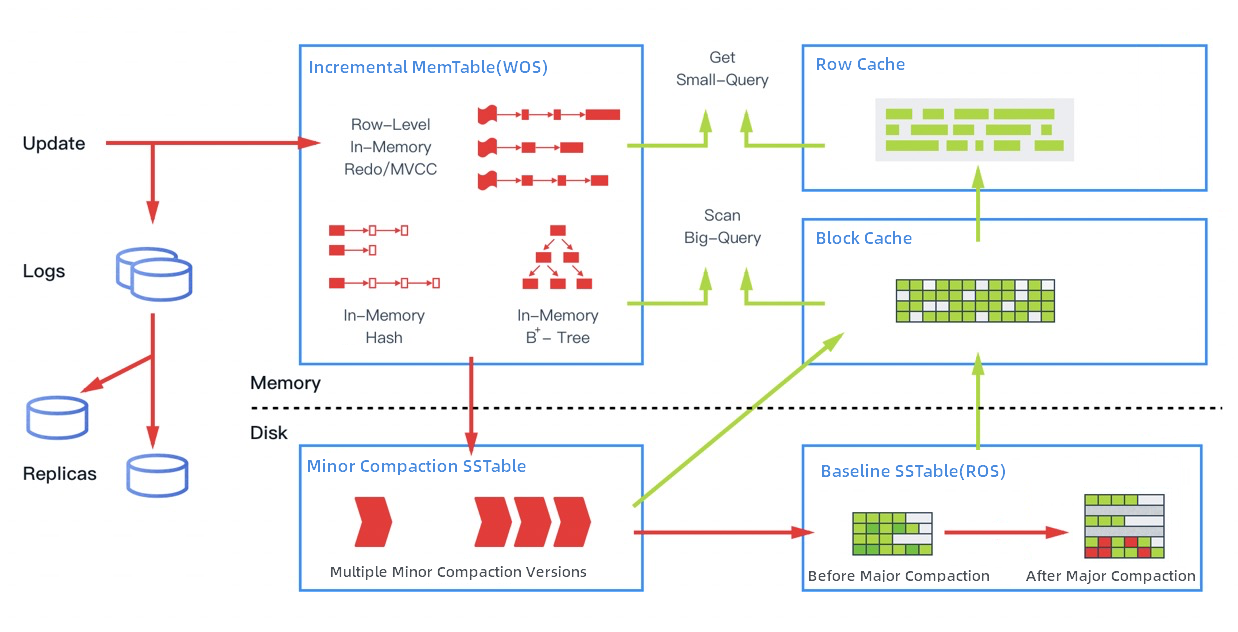
The storage engine of OceanBase Database is based on the LSM-tree architecture. Data is divided into static baseline data (stored in the SSTable) and dynamic incremental data (stored in the MemTable). The SSTable is read-only and stored on the disk. After an SSTable is generated, it will not be modified. MemTable can be read and written and is stored in the memory. DML operations data in the database, such as inserts, updates, and deletes, is first written into the MemTable. After the size of the MemTable reaches the specified threshold, its data is compacted with the baseline data and stored in the SSTable on the disk. After OceanBase Database receives a user query, it queries both the SSTable and the MemTable, merges the query results, and then returns the results to the SQL layer. OceanBase implements both block cache and row cache in the memory to avoid random read of the baseline data.
When the incremental data in a MemTable reaches a specified size, the incremental data is compacted with the baseline data and then persisted to the disk. The system performs a daily major compaction during idle hours every night.
Different from conventional relational databases, OceanBase is essentially a storage engine for baseline and incremental data. It also has the benefits of storage engines of some conventional relational databases.
Conventional databases divide data into many pages. OceanBase Database borrows this idea and divides data into many 2 MB macroblocks. OceanBase Database compacts the incremental data with the baseline data at much lower costs than data compaction in LevelDB and RocksDB. In addition, OceanBase Database separates the normal service time and major compaction time through the rotating major compaction mechanism without interfering with normal user requests.
OceanBase Database uses the baseline/incremental data design, which means that some data is baseline data and some is incremental data. In principle, every query reads both the baseline and incremental data. Therefore, OceanBase Database has undergone many optimizations, especially for single-row queries. In addition to the data block cache, OceanBase Database also caches rows. Row cache significantly accelerates single-row queries. OceanBase Database builds Bloom filters to filter queries for rows that do not exist and caches these filters. Most operations of the online transaction processing (OLTP) system are small queries. OceanBase Database optimizes small queries to avoid the overhead of parsing the entire data block as conventional databases do. The performance of OceanBase Database is close to that of an in-memory database. In addition, OceanBase Database can use effective compression algorithms, since the baseline data is read-only and is continuously stored. This ensures a high compression ratio and greatly reduces the cost without affecting the query performance.