

















This topic describes the backup and recovery and secondary backup features of OceanBase Cloud Platform (OCP).
Backup and recovery
As the core component for the high availability feature of OceanBase Database, the backup and recovery module ensures data security by preventing data loss caused by misoperations and damage to the storage media. If data is lost due to misoperations or damage to the storage media, you can recover the data.
OceanBase Database supports the backup, recovery, and management of data in two types of storage media: Object Storage Service (OSS) and Network File System (NFS).
Physical backup data includes baseline data and log archive data. Therefore, physical backup consists of log archiving and data backup.
Log archiving refers to the automatic backup of log data. OBServers regularly archive log data to the specified backup path without manual triggering.
Data backup refers to the backup of baseline data, and includes full backup and incremental backup:
Full backup refers to the backup of all macroblocks that need to be stored as baseline data.
Incremental backup refers to the backup of macroblocks that are added or modified since the last backup.
OceanBase Database provides tenant-level restoration, allowing you to create a tenant based on the existing data backup. The recovery process consists of restoration and recovery of the system table and user table of the tenant. Restoration returns the baseline data required for recovery to the OBServer of the target tenant. Recovery returns the logs corresponding to the baseline data to the OBServer and then replays the logs.
Physical backup architecture
The following figure shows the physical backup architecture of OceanBase Database.
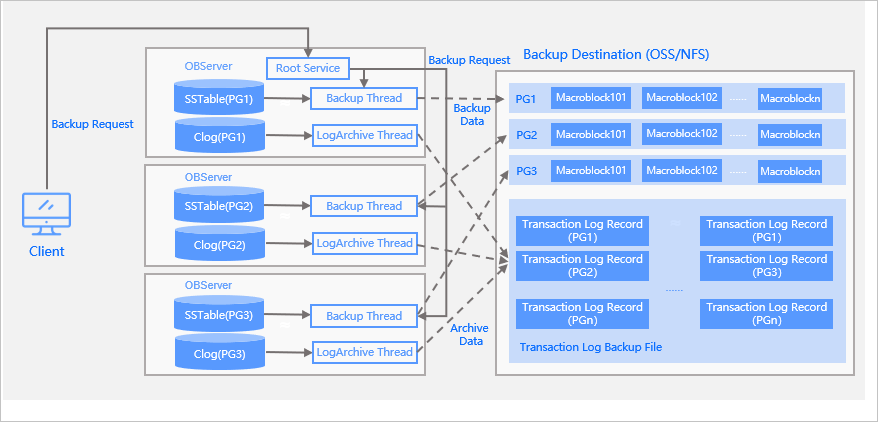
After you log on to the backup cluster by using the system tenant account, you must first run an SQL command to initiate log archiving. You can perform baseline backup only after log archiving is completed.
Log archiving regularly backs up logs to the backup destination. You need to run the alter system archivelog command only once, and log backup will continue in the background. During log archiving, the leader of each partition group (PG) is responsible for regularly archiving the logs of the PG to the specified path of the backup medium. The Root Service (RS) is responsible for regularly counting the log archiving progress and updating it to the internal table.
Data backup is user-triggered. Generally, full backup is triggered on each Saturday, and incremental backup is triggered on Tuesday and Thursday each week. When you initiate a data backup request, the request is first forwarded to the node running Root Service. Root Service generates a data backup task based on the current tenant and the PGs of the tenant. The backup task is then distributed to OBServers for parallel execution. The OBServers back up the metadata and macroblocks of the PGs to the specified backup directories, and the macroblocks are managed by PG.
OceanBase Database allows you to use OSS or NFS as the backup destination. Directory structure at the backup destination and the file types under each directory:
backup/ # The root directory of backups.
└── ob1 # cluster_name
└── 1 # cluster_id
└── incarnation_1 # The incarnation ID.
├── 1001 # The tenant ID.
│ ├── clog # The root directory of CLOGs.
│ │ ├── 1 # The CLOG backup round ID.
│ │ │ ├── data # The data directory of logs.
│ │ │ └── index # The index directory of logs.
│ │ └── tenant_clog_backup_info # The log backup metadata, which is recorded by round ID.
│ └── data # The root directory of data.
│ ├── backup_set_1 # The full backup directory.
│ │ ├── backup_1 # The first differential backup directory, which contains full metadata.
│ │ ├── backup_2 # The second differential backup directory, which also contains full metadata.
│ │ ├── backup_set_info # The information about multiple differential backups in the backup_set directory.
│ │ └── data # The macroblock data directory, which contains all full and differential macroblocks.
│ └── tenant_data_backup_info # The information about all data backups of the tenant.
├── clog_info # The log backup enabling information of servers.
│ └── 1_xxx.xxx.xxx.xxx_12533 # The log backup enabling information of a specific server.
├── cluster_clog_backup_info # The cluster-level log backup information.
├── cluster_data_backup_info # The cluster-level data backup information.
├── tenant_info # The tenant information.
└── tenant_name_info # The mapping between tenant names and IDs.
Physical recovery architecture
The following figure shows the physical restoration architecture of OceanBase Database.
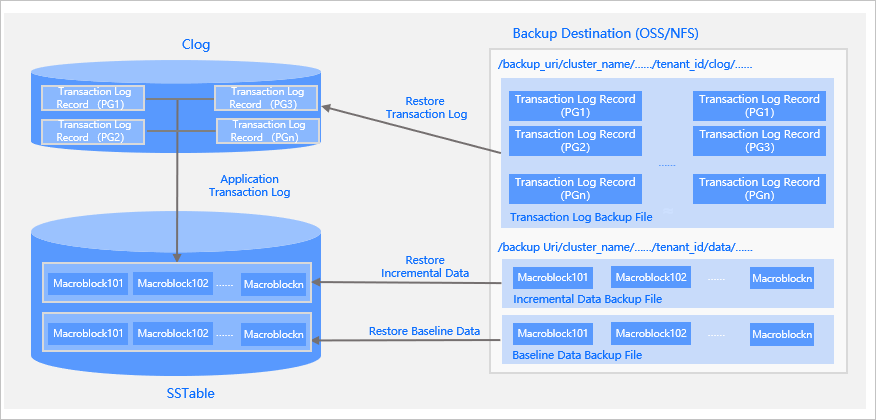
To start physical restoration, perform the following two steps:
In the target cluster, run the
CREATE RESOURCE POOLcommand to create a resource pool for tenant restoration.Run the
ALTER SYSTEM RESTORE TENANTcommand to schedule a tenant restoration task.
The following procedure is the internal procedure of the RESTORE TENANT command for backup restoration:
Create the tenant for restoration
Restore the system table data of the tenant
Restore system table logs of the tenant
Restore the metadata of the tenant
Restore the user table data of the tenant
Restore user table logs of the tenant
Outstanding works of restoration
For a single PG, the recovery starts by copying the metadata and macroblock data of the PG to the specified OBServer to build a PG with only baseline data. By then, the data is recovered to the time point of backup. After that, the logs of the PG are copied to the specified OBServer and put back into the MemTable of the PG. This process may trigger a minor compaction if the size of logs is large.
Secondary backup
In a secondary backup task, the full backup of an OceanBase cluster is backed up again. The backup files in the secondary backup are stored at a location that is different from the storage location of the first backup. The full backup data includes baseline data and log archive data.
The purpose of secondary backup is to reduce the storage pressure of regular backup. After the regular backup data stored on the server is periodically archived to the storage directory of the secondary backup, the regular backup files can be cleared early to release storage space.
In addition, the OceanBase cluster can be recovered from the secondary backup files. When the files of regular backups are inaccessible due to exceptions of the server on which they are stored, the secondary backup also guarantees the recovery of the OceanBase cluster.
For more information about enabling and configuring the secondary backup, see Create a cluster-level backup strategy and Create a tenant-level backup strategy. For more information about viewing the secondary backup tasks, see Backup and recovery overview.