

















This topic describes how to use OceanBase Migration Service (OMS) to migrate data from a PostgreSQL database to a MySQL tenant of OceanBase Database, which can be a physical data source or an ApsaraDB for OceanBase data source.
Background
You can create a data migration project in the OMS console to seamlessly migrate the existing business data and incremental data from a PostgreSQL database to a MySQL tenant of OceanBase Database through schema migration, full migration, and incremental synchronization.
The PostgreSQL database supports the following modes: primary database only, standby database only, and primary/standby databases. The following table describes the data migration operations supported by each mode.
Mode |
Supported operation |
|---|---|
| Primary database only | Schema migration, full migration, incremental synchronization, full verification, and reverse incremental migration |
| Standby database only | Schema migration, full migration, and full verification |
| Primary/Standby databases | Primary database: incremental synchronization and reverse incremental migration Standby database: schema migration, full migration, and full verification |
Prerequisites
You have created a corresponding schema in the destination MySQL tenant of the OceanBase database.
You have created dedicated database users in the source PostgreSQL database and the destination MySQL tenant of OceanBase Database for data migration and granted the corresponding privileges to the users. For more information, see Create a database user.
Limitations
Limitations on the source database
Do not perform DDL operations that modify database or table schemas during schema migration or full data migration. Otherwise, the data migration project may be interrupted.
At present, PostgreSQL 10.x and 12.x are supported.
OMS allows you to migrate tables with primary keys and tables with NOT NULL unique keys from a PostgreSQL database to a MySQL tenant of OceanBase Database.
When you use OMS to migrate data from a PostgreSQL database to a MySQL tenant of OceanBase Database, DDL synchronization is not supported.
OMS does not support triggers in the destination database.
When you migrate partitioned tables from a PostgreSQL database, take note of the following limits:
The parent table and child table must have the same schema.
The parent table and child table must have the same primary key columns, NOT NULL unique key columns, and partitioning key columns, or the primary key columns or NOT NULL unique key columns must include the partitioning key columns.
The primary keys or NOT NULL unique keys must be unique in the parent table.
OMS does not support the migration of tables in declarative partitioning in the PostgreSQL database.
REPLICA IDENTITYmust be set to FULL for all parent tables and child tables to be migrated from the PostgreSQL database.If
REPLICA IDENTITYis not set to FULL, the operation to update or delete the business data may fail.If you use a wildcard to specify the migration objects, the PostgreSQL database must subscribe to all tables in the selected database, including the selected tables, unselected tables, and new tables.
REPLICA IDENTITYmust be set to FULL for all parent tables, otherwise the operation to update or delete the business data may fail.
OMS does not support the migration of unlogged tables and temporary tables in the PostgreSQL database.
Data source identifiers and user accounts must be globally unique in OMS.
OMS supports the migration of only objects whose database name, table name, and column name are ASCII-encoded and do not contain special characters. The special characters are spaces, line breaks, and the following characters:
. | " ' ` ( ) = ; / & \.
Considerations
If a source table does not have a primary key or all columns of the table have a NOT NULL unique key, duplicate data may exist during migration to the destination.
In a reverse incremental migration scenario, if data migration is performed in full-column matching mode for UPDATE and DELETE operations, the following issues may occur:
Poor performance
Due to the absence of primary key indexes, each UPDATE or DELETE operation is performed after a full-table scan.
Data inconsistency
The LIMIT syntax is not supported for UPDATE and DELETE operations in PostgreSQL databases. Therefore, if multiple data records are matched in full-column matching mode, the data at the source may be more than that at the destination after UPDATE or DELETE operations. Assume that the t1 table without a primary key has two columns c1 and c2. Two data records where c1 = 1 and c2 = 2 exist at the source. When you delete only one data record from the source based on the
where c1 = 1 and c2 = 2condition, the two data records that match the condition at the destination will be deleted accordingly, causing data inconsistency between the source and the destination.
The data transmission service supports reverse incremental migration of tsvector fields from OceanBase Database to an ApsaraDB RDS for PostgreSQL instance. The tsvector fields must be written to OceanBase Database in the supported formats. Here is an example:
Data written to OceanBase Database in the 'a b c' format will be converted into the "'a' 'b' 'c'" format in the ApsaraDB RDS for PostgreSQL instance.
Data written to OceanBase Database in the 'a:1 b:2 c:3' format will be converted into the "'a':1 'b':2 'c':3" format in the ApsaraDB RDS for PostgreSQL instance.
Data written to OceanBase Database in a non-tsvector format such as "'a':cccc" cannot be migrated to the ApsaraDB RDS for PostgreSQL instance. For more information about the supported formats, see the 8.11. Text Search Types in PostgreSQL documentation.
In a project for reverse incremental migration from a PostgreSQL database to a MySQL tenant of OceanBase Database of a version earlier than V3.2.x, if the source table is a multi-partition table with a global unique index and you update the values of the partitioning key of the table, data may be lost during migration.
If you change the unique index of the destination, you must restart the Incr-Sync component. Otherwise, the data may be inconsistent.
If the clocks between nodes or between the client and the server are out of synchronization, the latency may be inaccurate during incremental synchronization or reverse incremental migration.
For example, if the clock is earlier than the standard time, the latency can be negative. If the clock is later than the standard time, the latency can be positive.
Take note of the following points if you want to perform data merge migration:
We recommend that you configure the mappings between the source and destination databases by specifying matching rules.
We recommend that you manually create schemas at the destination. If you use OMS to create schemas, skip failed objects in the schema migration step.
A difference between the source and destination table schemas may result in data consistency. Some known scenarios are described as follows:
When you manually create a table schema at the destination, if the data types of any columns are not supported by OMS, implicit data type conversion may occur at the destination, which causes inconsistent column types between the source and destination.
If the length of a column at the destination is shorter than that at the source, the data of this column may be automatically truncated, which causes data inconsistency between the source and destination.
If you select only Incremental Synchronization when you create a data migration project, OMS requires that the local incremental logs in the source database be retained for more than 48 hours.
If you select Full Data Migration and Incremental Synchronization when you create a data migration project, OMS requires that the local incremental logs in the source database be retained for at least 7 days. Otherwise, the data migration project will fail or the data in the source and destination databases will be inconsistent because OMS cannot obtain incremental logs.
Data type mappings
PostgreSQL database |
MySQL tenant of OceanBase Database |
|---|---|
| bigint | BIGINT |
| bigserial | BIGINT |
| bit [(n)] | BIT |
| boolean | TINYINT(1) |
| box | POLYGON |
| bytea | LONGBLOB |
| character [(n)] | CHAR LONGTEXT |
| character varying [(n)] | VARCHAR MEDIUMTEXT LONGTEXT |
| cidr | VARCHAR(43) |
| circle | POLYGON |
| date | DATE |
| double precision | DOUBLE |
| inet | VARCHAR(43) |
| interval [fields] [(p)] | TIME |
| json | LONGTEXT JSON |
| jsonb | LONGTEXT JSON |
| line | LINESTRING |
| lseg | LINESTRING |
| macaddr | VARCHAR(17) |
| money | DECIMAL(19,2) |
| numeric [(p, s)] | DECIMAL |
| path | LINESTRING |
| real | FLOAT |
| smallint | SMALLINT |
| smallserial | SMALLINT |
| serial | INT |
| text | LONGTEXT |
| time [(p)] [without time zone] | TIME |
| time [(p)] with time zone | TIME |
| timestamp [(p)] [without time zone] | DATETIME |
| timestamp [(p)] with time zone | DATETIME |
| tsquery | LONGTEXT |
| tsvector | LONGTEXT |
| uuid | VARCHAR(36) |
| xml | LONGTEXT |
| point | POINT |
| linestring | LINESTRING |
| polygon | POLYGON |
| multipoint | MULTIPOINT |
| multilinestring | MULTILINESTRING |
| multipolygon | MULTIPOLYGON |
| geometrycollection | GEOMETRYCOLLECTION |
| triangle | POLYGON |
| tin | MULTIPOLYGON |
Procedure
Create a data migration project.

Log on to the OMS console.
In the left-side navigation pane, click Data Migration.
On the Data Migration page, click Create Migration Project in the upper-right corner.
On the Select Source and Destination page, configure the parameters.
ParameterDescriptionMigration Project Name We recommend that you set it to a combination of digits and letters. It must not contain any spaces and cannot exceed 64 characters in length. Tag (Optional) Click the field and select a target tag from the drop-down list. You can also click Manage Tags to create, modify, and delete tags. For more information, see Use tags to manage data migration projects. Source If you have created a PostgreSQL data source, select it from the drop-down list. If not, click New Data Source in the drop-down list and create one in the dialog box that appears on the right. For more information, see Create a PostgreSQL data source.
You can select a PostgreSQL data source in primary database only mode or primary/standby databases mode. This topic describes how to create a data migration project with a PostgreSQL data source in primary/standby databases mode.Destination If you have created a MySQL tenant of OceanBase Database data source, which can be a physical data source or an ApsaraDB for OceanBase data source, select it from the drop-down list. If not, click New Data Source in the drop-down list and create one in the dialog box that appears on the right. For more information about the parameters, see Create a physical OceanBase data source or Create a public cloud OceanBase data source. Click Next. In the dialog box that appears, click OK.
Note that this project supports only tables and views with a primary key or a non-null unique index and those without are automatically filtered out.
On the Select Migration Type page, configure the parameters.
Options for Migration Type are Schema Migration, Full Data Migration, Incremental Synchronization, Full Verification, and Reverse Increment.
Migration typeLimitationsSchema migration When a schema migration task starts, OMS migrates the definitions of data objects, such as tables, indexes, constraints, comments, and views, from the source database to the destination database. Temporary tables are automatically filtered out. Full migration When a full migration task starts, OMS migrates the existing data from tables in the source database to the corresponding tables in the destination database. If you select Full Migration, we recommend that you use the ANALYZEstatement to collect the statistics of the PostgreSQL database before data migration.Incremental synchronization When an incremental synchronization task starts, OMS synchronizes changed data in the source database to the corresponding tables in the destination database. Data changes are data addition, modification, and deletion.
Options for DML Synchronization in the Incremental Synchronization section includeInsert,Delete, andUpdate. For more information, see DML filtering.
OMS Community Edition automatically creates publications and slots for incremental synchronization from a PostgreSQL database. However, you need to monitor the usage of the disk for storing archive files. By default, OMS instructs the database to update theconfirmed_flush_lsnvalue of a slot every 10 minutes. The interval can be customized. By default, archive files need to be retained for 48 hours. Therefore, OMS instructs the database to clean up only archived logs that have been retained for more than 48 hours. The retention period can be customized.
If the archive logs cannot be cleared during the migration because slots exist, you need to destroy the data migration project and then clear the archive logs.Full verification After the full data migration and incremental data synchronization are completed, OMS automatically initiates a full data verification task to verify the data tables in the source and destination databases. - If you select Full Verification, we recommend that you collect the statistics of the PostgreSQL database and the MySQL tenant of OceanBase Database before full verification. For more information about how to collect statistics of a MySQL tenant of OceanBase Database, see Manually collect statistics.
- If you have selected Incremental Synchronization but did not select all DML statements in the DML Synchronization section, OMS does not support full verification.
- OMS supports full data verification only for tables with a primary key or a non-null unique key.
Reverse incremental migration When a reverse incremental migration task starts, OMS migrates the data changed in the destination database after the business switchover back to the source database in real time. You cannot select Reverse Increment in the following cases: - Data merge migration that involves multiple tables is enabled.
- Multiple source schemas map to the same destination schema.
(Optional) Click Next.
If you have selected Reverse Increment but the related parameters are not configured for the destination MySQL tenant of OceanBase Database, the More About Data Sources dialog box appears, prompting you to configure related parameters. For more information about the parameters, see Create a physical OceanBase data source or Create a public cloud OceanBase data source.
After you configure the parameters, click Test Connection. After the test succeeds, click OK.
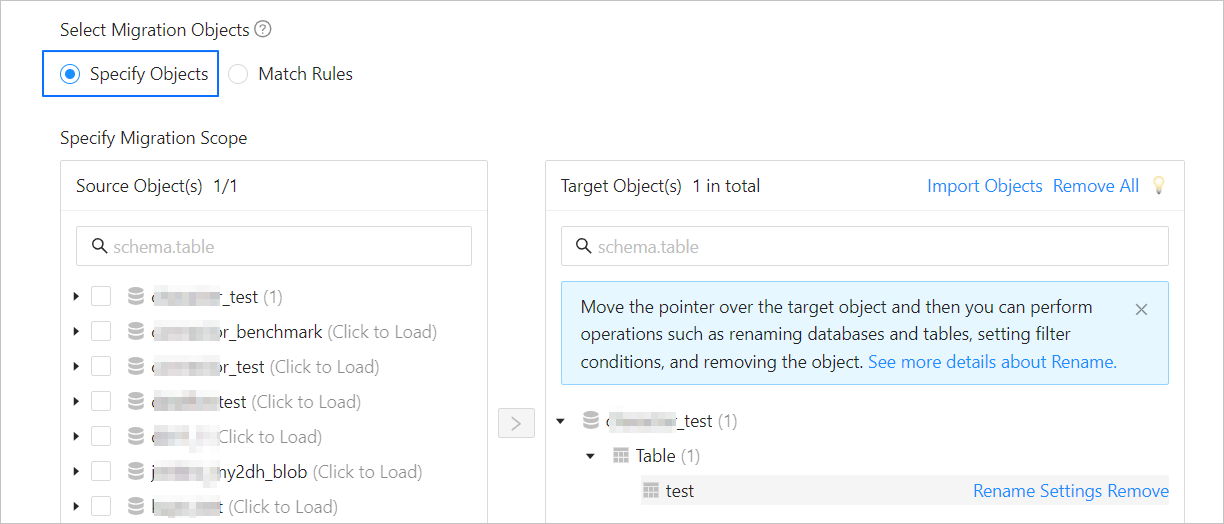
Click Next. On the Select Migration Objects page, specify the migration objects and migration scope.
You can select Specify Objects or Match Rules to specify the migration objects.
Select Specify Objects. Then select the objects to be migrated on the left and click > to add them to the list on the right. You can select tables and views of one or more databases as the migration objects.
Notice
The names of tables to be migrated, as well as the names of columns in the tables, must not contain Chinese characters.
If the database or table name contains a double dollar sign ($$), you cannot create the migration project.
OMS automatically filters out unsupported tables.
OMS also allows you to import objects from text, rename objects, set row filters, view column information, and remove a single object or all objects to be migrated.
 OperationDescription
OperationDescriptionImport objects - In the list on the right of the Specify Migration Scope section, click Import Objects in the upper-right corner.
- In the dialog box that appears, click OK.
Notice
This operation will overwrite previous selections. Proceed with caution. - In the Import Objects dialog box, import the objects to be migrated.
You can import CSV files to rename databases/tables and set row filtering conditions. For more information, see Download and import the settings of migration objects. - Click Validate.
- After the validation succeeds, click OK.
Rename objects OMS allows you to rename the migration objects. For more information, see Rename a migration or synchronization object. Configure settings OMS allows you to use the WHEREclause to filter rows. For more information, see Use SQL conditions to filter data.
You can also view column information of the migration object in the View Column section.Remove one or all objects During data mapping, OMS allows you to remove one or more selected objects to be migrated or synchronized to the destination. - To remove a single migration object:
In the list on the right of the Specify Migration Scope section, move the pointer over the target object, and click Remove. - To remove all migration objects:
In the list on the right of the Specify Migration Scope section, click Remove All in the upper-right corner. In the dialog box that appears, click OK.
Select Match Rules. For more information, see Configure matching rules for migration objects.
Click Next. On the Migration Options page, configure the parameters.
Full migration
The following parameters are displayed only if you have selected Full Data Migration on the Select Migration Type page.
 ParameterDescription
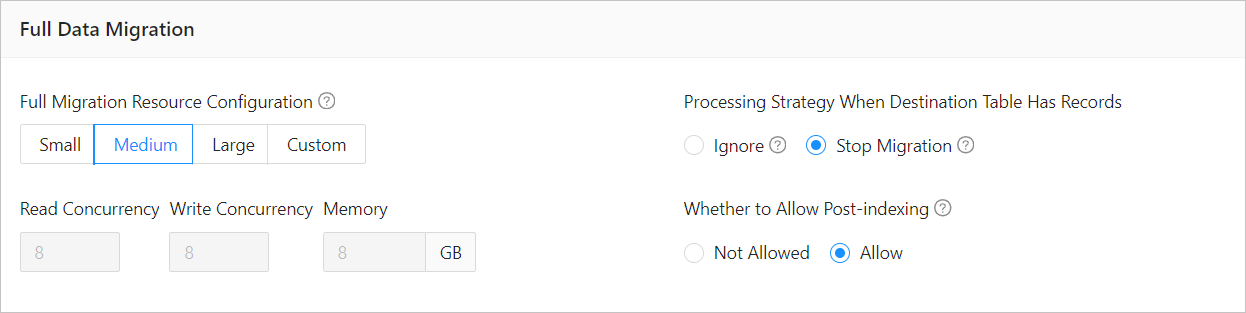
ParameterDescriptionFull Migration Resource Configuration You can select Small, Medium, or Large to use the corresponding default values of Read Concurrency, Write Concurrency, and Memory. You can also customize the resource configurations for full migration. Through resource configuration for the Full-Import component, you can limit the resource consumption of a project in the full migration phase. Notice
In the case of custom configurations, the minimum value is 1, and only integers are supported.
Processing Strategy When Destination Table Has Records Valid values: Ignore and Stop Migration. - If you select Ignore, when the data to be written conflicts with the existing data of a destination table, OMS logs the conflicting data while retaining the existing data.
Notice
If you select Ignore, data is pulled in IN mode for full verification. In this case, the scenario where the destination contains more data than the source cannot be verified, and the verification efficiency will be decreased.
- If you select Stop Migration and a destination table contains records, an error is returned during full migration, indicating that the migration is not allowed. In this case, you must clear the data in the destination table before you can continue with the migration.
Notice
After an error is returned, if you click Resume in the dialog box, OMS ignores this error and continues to migrate data. Proceed with caution.
Whether to Allow Post-indexing Specifies whether to create indexes after the full migration is completed. Post-indexing can shorten the time required for full migration. For more information about the considerations on post-indexing, see the description below. Notice
This feature is supported only if you have selected both Schema Migration and Full Data Migration on the Select Migration Type page.
- Only non-unique key indexes can be created after the migration is completed.
- OceanBase Database V1.x does not support the post-indexing feature.
If post-indexing is allowed, we recommend that you adjust the parameters based on the hardware conditions of your OceanBase database and the current business traffic.
If you use OceanBase Database V4.x, adjust the following parameters of the
systenant and business tenants by using a CLI client.Adjust the parameters of the
systenant// parallel_servers_target specifies the queuing conditions for parallel queries on each server. // To maximize performance, we recommend that you set this parameter to a value greater than, for example, 1.5 times, the number of physical CPU cores. In addition, make sure that the value does not exceed 64, to prevent database kernels from contending for locks. set global parallel_servers_target = 64;Adjust the parameters of a business tenant
// Specify the limit on the file memory buffer size. alter system set _temporary_file_io_area_size = '10' tenant = 'xxx'; // Disable throttling in V4.x. alter system set sys_bkgd_net_percentage = 100;
If you use OceanBase Database V2.x or V3.x, adjust the following parameters of the
systenant by using a CLI client.// parallel_servers_target specifies the queuing conditions for parallel queries on each server. // To maximize performance, we recommend that you set this parameter to a value greater than, for example, 1.5 times, the number of physical CPU cores. In addition, make sure that the value does not exceed 64, to prevent database kernels from contending for locks. set global parallel_servers_target = 64; // data_copy_concurrency specifies the maximum number of concurrent data migration and replication tasks allowed in the system. alter system set data_copy_concurrency = 200;
- If you select Ignore, when the data to be written conflicts with the existing data of a destination table, OMS logs the conflicting data while retaining the existing data.
Incremental synchronization
The following parameters are displayed only if you have selected Incremental Synchronization on the Select Migration Type page.
 ParameterDescription
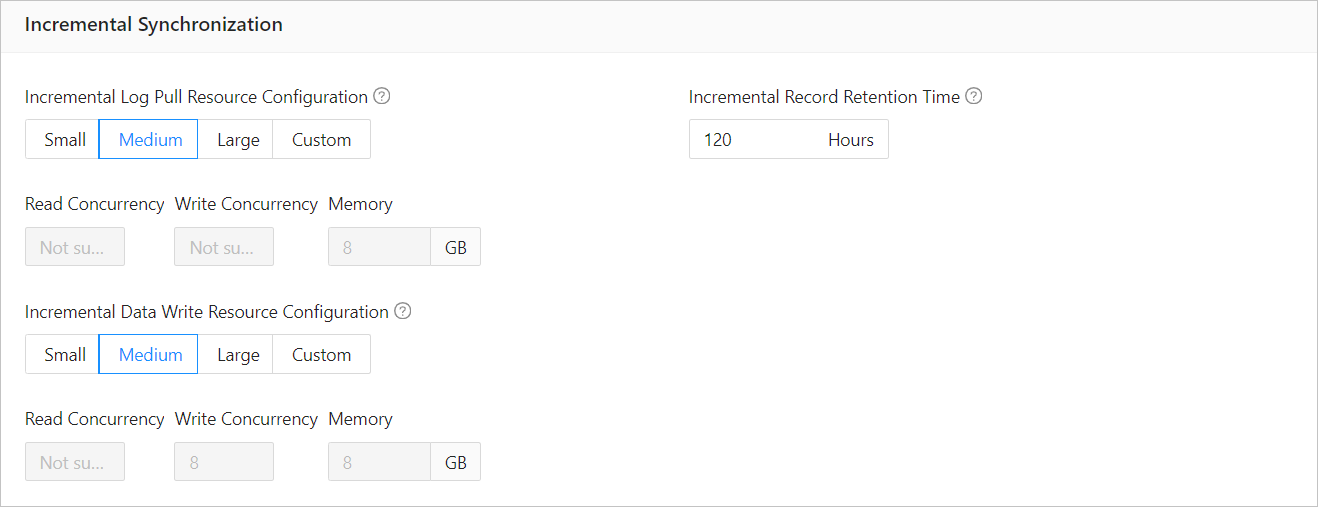
ParameterDescriptionIncremental Log Pull Resource Configuration You can select Small, Medium, or Large to use the corresponding default value of Memory. You can also customize the resource configurations for incremental log pull. Through resource configuration for the Store component, you can limit the resource consumption of a project in log pull in the incremental synchronization phase. Notice
In the case of custom configurations, the minimum value is 1, and only integers are supported.
Incremental Data Write Resource Configuration You can select Small, Medium, or Large to use the corresponding default values of Write Concurrency and Memory. You can also customize the resource configurations for incremental data write. Through resource configuration for the Incr-Sync component, you can limit the resource consumption of a project in data writes in the incremental synchronization phase. Notice
In the case of custom configurations, the minimum value is 1, and only integers are supported.
Incremental Record Retention Time The duration that incremental parsed files are cached in OMS. A longer retention period results in more disk space occupied by the Store component. Incremental Synchronization Start Timestamp - If you have set the migration type to Full Data Migration, this parameter is not displayed.
- If you have selected Incremental Synchronization but not Full Data Migration, specify a point in time after which the data is to be synchronized. The default value is the current system time. For more information, see Set an incremental synchronization timestamp.
Reverse incremental migration
The following parameters are displayed only if you have selected Reverse Increment on the Select Migration Type page. The parameters for reverse incremental migration are consistent with those for incremental synchronization. You can select Reuse Incremental Synchronization Configuration in the upper-right corner.
Full verification
The following parameters are displayed only if you have selected Full Verification on the Select Migration Type page.
 ParameterDescription
ParameterDescriptionFull Verification Resource Configuration You can select Small, Medium, or Large to use the corresponding default values of Read Concurrency and Memory. You can also customize the resource configurations for full verification. Through resource configuration for the Full-Verification component, you can limit the resource consumption of a project in the full verification phase. Notice
In the case of custom configurations, the minimum value is 1, and only integers are supported.
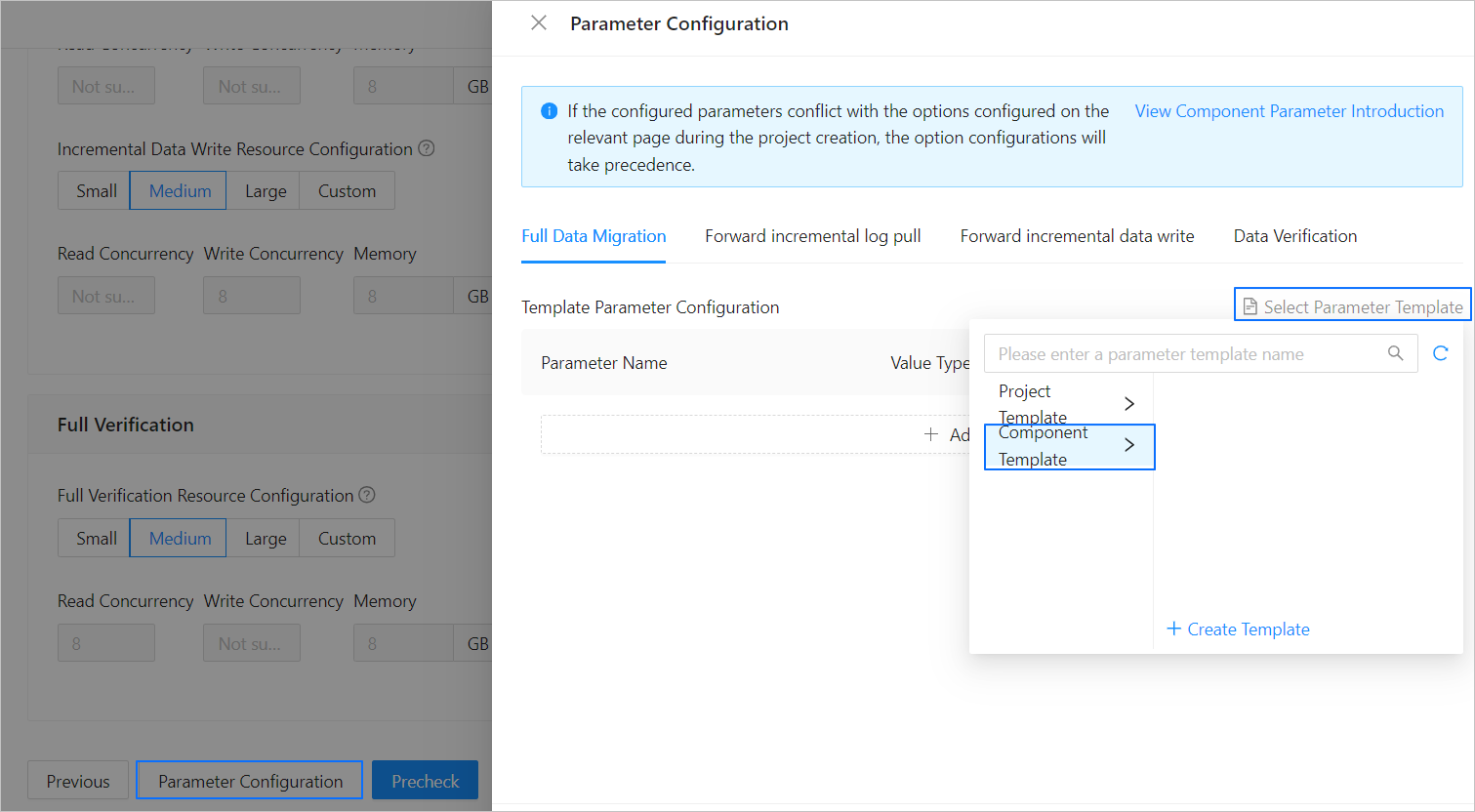
If the parameter settings on the page cannot meet your requirements, you can click Parameter Configuration in the lower part of the page to configure more specific settings. You can also reference an existing project or component template.
Click Precheck to start a precheck on the data migration project.
During the precheck, OMS checks the read and write privileges of the database users and the network connections of the databases. The data migration project can be started only after it passes all check items. You can perform one of the following operations if an error is returned during the precheck:
Identify and troubleshoot the problem and then perform the precheck again.
Click Skip in the Actions column of a failed precheck item. In the dialog box that appears, you can view the prompt for the consequences of the operation and click OK.
Click Start Project. If you do not need to start the project now, click Save to go to the details page of the data migration project. You can start the project later as needed.
OMS allows you to modify the migration objects when the data migration project is running. For more information, see View and modify migration objects. After a data migration project is started, the migration subtasks will be executed based on the selected migration types. For more information, see the "View migration details" section in the View details of a data migration project topic.