

















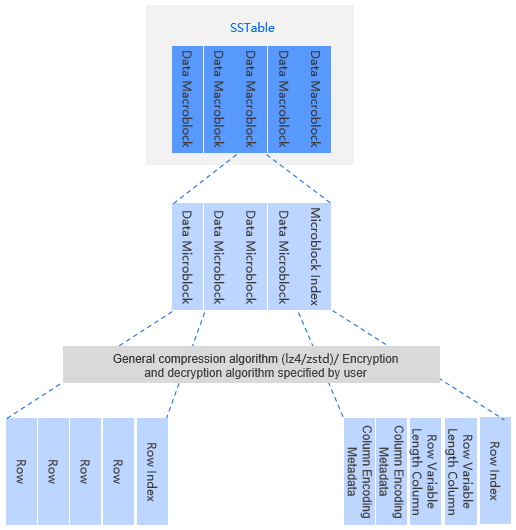
In OceanBase Database, an SSTable is a basic unit that is used to manage data in each partition of a user table. If the size of a MemTable reaches a specific threshold, OceanBase Database freezes the MemTable and compacts data in the MemTable to the disk. The structure obtained after the minor compaction is called an SSTable or a minor SSTable. When a global compaction occurs in a cluster, a major compaction is performed on minor SSTables of all user table partitions based on the compaction snapshot to generate a major SSTable. All SSTables are constructed in similar ways. Each SSTable consists of metadata and a series of macroblocks. Each macroblock can be divided into multiple microblocks. Rows in a microblock are organized in the flat or encoding format based on user table modes.
Macroblock
OceanBase Database splits the disk into several fixed-length data blocks of 2 MB. These blocks are called macroblocks. A macroblock is the basic unit of write I/O operations. Each SSTable comprises several macroblocks. The size of fixed-length macroblocks cannot be changed. Minor compactions, major compactions, and data replication and migration are all performed at the granularity of macroblocks.
Microblock
Data in a macroblock is grouped into multiple variable-length data blocks of 16 KB. These blocks are called microblocks. A microblock contains several rows and is the smallest unit of read I/O operations. Each microblock is compressed based on a specified compression algorithm during construction. Therefore, a macroblock actually stores compressed microblocks. When a microblock is read from the disk, it is decompressed in the background, and decompressed data is stored in the data block cache. You can specify the size of each microblock by using the following statement when you create a table. By default, a microblock is 16 KB in size. The size of each microblock cannot exceed that of a macroblock.
ALTER TABLE mytest SET block_size = 131072;Generally, a longer microblock length means a higher data compression ratio and higher I/O read costs. A shorter microblock length means a lower data compression ratio and lower random I/O read costs. Each microblock can be constructed in the flat or encoding format based on user table modes. Only microblocks of baseline data can be organized in the encoding format. By default, microblocks of all minor compaction data are organized in the flat format.