

















The log service is a basic component of a relational database service. The importance of the log service in OceanBase Database is reflected in the following aspects:
Persists the content in the MemTable mutator and the transaction status information after transactions are committed, to support the atomicity and durability of transactions.
Generates trans_version values and synchronizes them to all followers, including read-only replicas, to support the isolation of transactions.
Uses the Paxos protocol to synchronously transfer logs to the majority of replicas, to provide support for data redundancy and HA, and thereby supports various types of replicas, such as read-only replicas and log replicas.
Maintains authoritative member group and leader information, which is used by various modules of OceanBase Database. Provides an underlying mechanism for complex strategies of RootService, such as load balancing and rotating major compaction.
Provides external data services to offer incremental data to external tools such as OceanBase Migration Service (OMS) and incremental backup.
Challenges to the log service of OceanBase Database
Compared with the log modules of traditional relational database services, the log service of OceanBase Database faces the following challenges:
The Multi-Paxos protocol is required to replace the traditional primary/standby synchronization mechanism. This achieves system high availability (HA) and data reliability. Global deployment must be supported, and the network latency among replicas reaches dozens or even hundreds of milliseconds.
As a distributed database service, OceanBase Database performs data synchronization based on partitions. A single OBServer must support at least ten thousand partitions to implement efficient reads and writes of log data. In addition, batch operations must be realized to accelerate executions for a feature.
The log service must maintain status information such as the member list and leader, and must provide efficient support for the rich features of a distributed system.
Overall structure
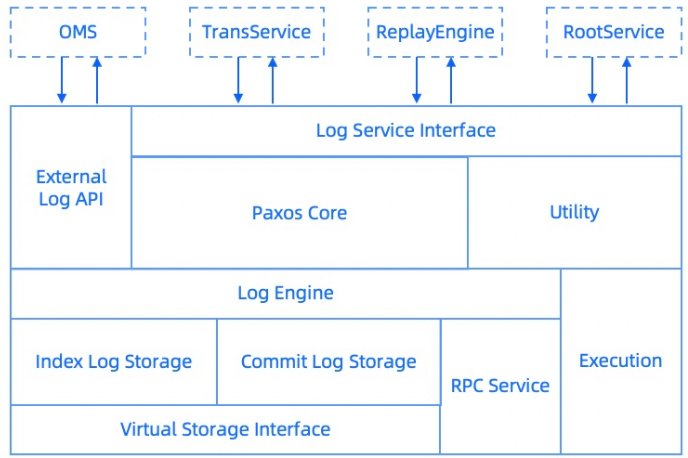
Paxos Core
Paxos Core is the core of the log service. The log service implements the standard Multi-Paxos protocols to ensure that all committed data can be recovered if no permanent fault occurs on the majority of replicas.
Paxos Core implements the unordered committing of logs, ensures that transactions are mutually independent, supports remote deployment, and prevents the fault of a single network link from affecting the response time of all subsequent transactions.
To ensure the correctness of Multi-Paxos, the log service provides checksum verification at the following levels:
Checksum verification for a single log.
Checksum verification for an entire block after a group commit.
Checksum verification for remote procedure call (RPC) packets.
Verification for cumulative log_id checksums. When a log is being synchronized, the correctness of all logs before the current partition is checked based on checksums.
The correctness of the log service is ensured based on correct and efficient protocol implementation, non-stop running of switchover test cases, and impeccable checksum verification.
Member group management
The log service maintains the member group information of each partition. The member group information of a partition contains the member list of the current Paxos group and the quorum information.
The following features are supported in member group management:
add_member and remove_member: adds and removes members. For migration operations initiated by load balancers and data synchronization to replicas caused by breakdowns, the member group of the relevant partition needs to be modified by using this feature.
modify_quorum: modifies the quorum of a Paxos group. For locality change, such as from 3F to 5F, or regional fault-based downgrade, such as from 5F to 3F, the quorum of the relevant Paxos group needs to be modified by using this feature.
For these features, specific interfaces are provided to perform operations on multiple partitions at a time. This significantly improves the operation execution efficiency.
For example, based on the batch_modify_quorum interface, the amount of time required for the 5F-to-3F downgrade for ten thousand partitions of a single server is reduced from 20 minutes to 20 seconds. This remarkably optimizes the disaster recovery performance and reduces the response time of the system in fault scenarios.
Re-election with a leader
Built based on the log-structured merge-tree (LSM tree) structure, OceanBase Database needs to periodically compact the data in the MemTables to the SSTable through minor or major compactions. Such operations require a lot of CPU resources. To maintain normal service requests during major compactions and accelerate major compactions, OceanBase Database adopts the rotating major compaction mode. In this mode, the leader is switched to another replica in the same region before a major compaction.
The log service provides support for each re-election with a leader. A re-election with a leader is performed in two steps:
RootService queries the valid candidates of each partition for the re-election.
RootService determines the new leader, delivers orders, and executes the re-election request based on information about the candidate list, region, and primary zone.
Fault recovery
OceanBase Database may encounter different types of faults such as disk faults, network faults, and server breakdowns during actual operation. A highly available distributed database system must be capable of coping with different faults and ensuring a recovery point objective (RPO) of 0 and a short recovery time objective (RTO). The following list describes the roles of the log service in different fault scenarios:
The minority of nodes except the leader are down. In this case, the log service synchronizes logs to the majority of nodes based on the Paxos protocol. The availability is not affected, and both RPO and RTO are 0.
The minority of nodes, including the leader, are down. In this case, the log service implements a re-election without a leader and the Paxos recovery process to ensure that after the period specified by lease_time elapses, a new leader can be elected within a short period to provide services. This process involves no data loss and ensures an RPO of 0 and an RTO of less than 30s.
The minority of nodes except the leader encounter network partitioning. In this case, the log service synchronizes logs to the majority of nodes based on the Paxos protocol. The availability is not affected, and both RPO and RTO are 0.
The minority of nodes including the leader encounter network partitioning. In this case, the log service implements a re-election without a leader and the Paxos recovery process to ensure that after the period specified by lease_time elapses, a new leader can be elected within a short period to provide services. No data loss is involved, and an RPO of 0 and an RTO of less than 30s are ensured.
The majority of nodes are down. In this case, services are interrupted, and the log service restarts the failed nodes to recover the replicas.
The entire cluster is down. In this case, services are interrupted, and the log service restarts the failed nodes to recover the replicas.
The actual service fault scenarios include but are not limited to the preceding downtime or network partitioning scenarios. OceanBase Database can automatically detect various disk faults, such as hang-up or slow writes, and switch over the read traffic of the leader and follower replicas within 1 minute, to ensure timely service recovery.
Read-only replicas, cascaded synchronization, and replica type conversion
The log service ensures a positive correlation between log_id and trans_version values and a keepalive interval of 100 milliseconds. This supports weak consistency reads of the standby cluster and read-only replicas.
Read-only replicas are not members of the Paxos group. OceanBase Database uses the locality-based adaptive cascade algorithm to automatically build upstream and downstream relationships for read-only replicas, so as to implement automatic data synchronization.
The log service supports log replicas except for read-only replicas and the conversion among the three supported replica types. Log replicas adopt special log recycling strategies.