

















OceanBase Developer Center (ODC) allows you to create a table on a GUI. This topic describes how to create a table in the ODC console.
Background information
Logical tables
ODC V4.3.2 and later versions support configuring multiple (or single) physical databases into a logical database and configuring logical tables to query and manage complex and large-scale sharding databases and tables. For more details, please refer to Logical Database Management.
Note
If you do not have logical database permissions, you can apply for database permission through the Projects/Ticket.
Expressions of logical tables
| Rule Type | Rule Name | Example |
| Simple rules | Create tables whose names contain numbers that increment in numerical order | db.test_[0-7]: creates eight tables whose names contain numbers that increment in numerical order. |
| Create tables whose names contain numbers that have the same number of digits and increment in numerical order |
|
|
| Create tables whose names contain numbers that increment in numerical order with a specified step | db.test_[0-8:2]: creates five tables named db.test_0, db.test_2, db.test_4, db.test_6, and db.test_8. The step is 2. |
|
| Create tables whose names contain numbers that have the same number of digits and increment in numerical order with a specified step | db.test_[00-07:3]: creates three tables named db.test_00, db.test_03, and db.test_06. The step is 3. |
|
| Create tables whose names contain incrementing numbers in the middle part | db.test_[00-31]_t: creates tables whose names contain numbers from 00 to 31 in the middle part. |
|
| Multi-level rules | Create tables whose names contain numbers that represent months and dates | db.test_[01-12]_[01-31]: creates tables whose names contain numbers that represent the first to 31st days in 12 months. The total number of the tables to be created is 12 × 31. |
| Create tables whose names contain numbers that represent months and dates incrementing with specified steps | db.test_[01-12:2]_[01-31:2]: creates tables whose names contain numbers that represent odd dates in odd months. The total number of tables to be created is 6 × 16. |
|
| Rules for databases and tables | Create tables that have the same name | db_[00-31].test: creates tables named test in databases numbered from 00 to 31. |
| Create tables and evenly distribute the tables to specified databases | db_[00-31].test[0000-1023]: creates 1,024 tables and evenly distributes the tables to databases numbered from 00 to 31. |
|
| Enumeration rules | Create tables based on a simple enumeration | db.test_[1,3,6,8,9]: creates five tables in the specified database. |
| Create tables based on a complex enumeration | Use multiple expressions to create tables and evenly distribute the tables to specified databases. Examples:db.test_[1,3,6,8,9],db.test_[2,4,5,7,10] |
|
| Enumeration rules for databases | Create the same tables in specified databases | db_[00-31].test_[[00-31]]: creates tables named test_[00-31] in each of the databases numbered from 00 to 31. |
| Create tables based on enumeration rules in specified databases | db_01.test_[1,2,4,6,7],db_02.test_[2,3,5,7,9],db_03.test_[1,4,6,7,9]creates five tables with specified names in the three databases. |
|
| Create different number of tables in different databases | db_01.test_[1-7],db_02.test_[10-15]: creates seven tables in database db_01 and six tables in database db_02. |
Steps to Create a Table

The procedure comprises seven steps:
Specify the basic information.
Set columns.
Set indexes.
Set constraints.
Set partitioning rules.
Verify the SQL statement.
Complete the table creation.
The example in this topic describes how to create a table named employee in the ODC console. The table contains the emp_no, birthdate, name, and gender columns.
Note
The data used in this topic are examples. You can replace them with actual data as needed.
Procedure
Step 1: Specify the basic information
Log on to the ODC console and click the name of the desired connection to go to the corresponding connection management page. You can click Table in the left-side navigation pane to view tables. To create a table, click the plus sign (+) in the upper-right corner of the table list or click Create in the top navigation bar.
In the Basic Info section, set the Table Name and Description parameters.
Note
- In MySQL mode, you also need to set the Default Character Set and Default Collation parameters.
- After you specify the basic information and go to the "Set columns" step, the basic information is submitted.
- Only OceanBase V4.3.0 and later versions support configuring columnar storage.
Step 2: Set columns
Note
In ODC V4.2.3 and later, you can create a table that contains columns of spatial data types in OceanBase Database in MySQL mode or MySQL Database.
The following figure and table show the information that you need to specify when you add a column.
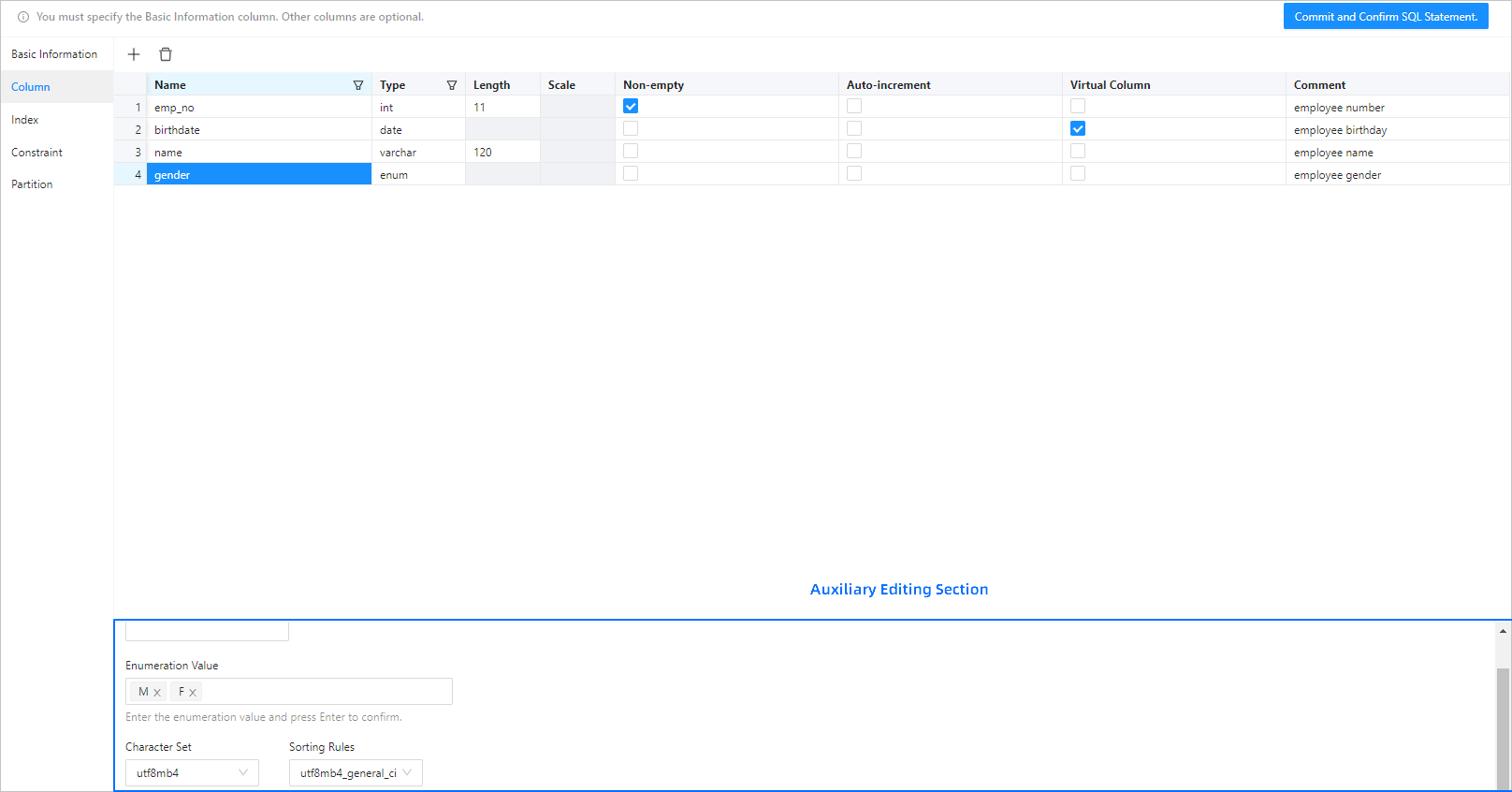
Parameter |
Description |
|---|---|
| Name | The name of the column. |
| Type | The data type of the column. For more information about data types, see OceanBase Database Developer Guide. |
| Length | The length of the data type. |
| Scale | The number of decimal places of the data type. |
| Non-empty | Specifies whether the value of the column is required. |
| Auto-increment | Specifies whether the column is an auto-increment column. This parameter is valid in MySQL mode.
Notice
|
| Virtual Column | Specifies whether to set the column as a virtual column.
Notice
|
| Default Value/Expression | The default value or expression of the column. |
| Comment | The additional information about the column. |
The following table describes operations that you can perform on the column setting page.
Operation |
Description |
|---|---|
| Toolbar operations | You can add or delete columns by using the top toolbar of the page. |
| Click a row ID |
|
| Right-click a row | You can right-click a row to select it, and then select Copy or Move Down from the context menu that appears. |
Note
- After you copy a row, you can paste the row by using the Command + V or Ctrl + V shortcut keys.
- The auxiliary editing section at the bottom of the page displays additional information about the selected column.
- The basic information and column settings are required. The settings in other configuration steps are optional. After you specify the basic information and column settings, you can submit the settings and confirm the SQL statement to create the table.
Step 3: Set indexes
If a table contains a large amount of data, you can use indexes to accelerate data queries. An index is a data structure that pre-sorts the values of one or more columns in a table. By using indexes, you can directly locate records that meet the conditions.
The following figure and table show the information that you need to specify when you set an index.

Parameter |
Description |
|---|---|
| Index Name | The name of the index. |
| Range | The default value is GLOBAL. Valid values: GLOBAL and LOCAL. |
| Method | The default value is BTREE, which is applicable to a global index. Valid values: Empty, BTREE, and HASH.
|
| Index Type | The default value is NORMAL. Valid values: NORMAL, UNIQUE, and FULLTEXT.
|
| Columns | The columns to be indexed. Pay attention to the order of the indexed columns. |
| Invisible | Specifies whether the index is invisible. |
The index setting page provides the following icons.
Icon |
Description |
|---|---|
| Create | Click this icon to create an index. |
| Delete | Click this icon to delete the selected index. |
Step 4: Set constraints
Constraints are used to specify data rules for a table. A data operation that violates the constraints is terminated.

ODC supports the following four types of table constraints:
PRIMARY KEY constraint: defines a primary key to uniquely identify each row of data in the table. A PRIMARY KEY constraint can be a field or a group of fields. You can set only one PRIMARY KEY constraint for a table, and you cannot modify the PRIMARY KEY constraint after you configure the constraint.
UNIQUE constraint: ensures that the data in a field or a group of fields is unique in the table. You can set multiple UNIQUE constraints in one table.
FOREIGN KEY constraint: associates one or more columns in two tables. A FOREIGN KEY constraint is used to maintain the data consistency and integrity between associated tables. After you complete the setting of FOREIGN KEY constraints, you cannot create new constraints or modify existing constraints.
CHECK constraints: checks the data in the database based on the configured check rules when you edit the data. Data modification is allowed only after the check is passed.
OceanBase Database supports different constraints in MySQL and Oracle modes, and different constraints require different information. Therefore, you need to specify the required information based on the constraint you selected and the requirements on the page.
Parameter |
Description |
|---|---|
| Constraint Name | The name of the constraint. |
| Column Information | The field or a group of fields specified as the constraint. |
| Associated Schema | The schema where the associated table is located when Foreign Key Constraint is used. The associated table is the parent table. This field is valid only in Oracle mode. |
| Associated Database | The database where the associated table is located when Foreign Key Constraint is used. The associated table is the parent table. This field is valid only in MySQL mode. |
| Associated Table | The associated table when Foreign Key Constraint is used. The associated table is the parent table. |
| Associated Field | The associated field when Foreign Key Constraint is used. The associated field is in the parent table. |
| Delete | Specifies the action to be performed on the current table when the data in the associated table is deleted. The current table is the child table, and the associated table is the parent table. The following four types of action are supported: CASCADE, NO ACTION, RESTRICT, and SET NULL. The actions supported in MySQL mode are different from those in Oracle mode.
|
| Update | Specifies the action to be performed on the current table when the data in the associated table is updated. The current table is the child table, and the associated table is the parent table. The following four types of action are supported: CASCADE, NO ACTION, RESTRICT, and SET NULL. The actions supported in MySQL mode are different from those in Oracle mode.
NoticeAt present, OceanBase Database does not support SET NULL. |
| Check Condition | Specifies the check rules for data verification when Check Constraint is enabled. |
The constraint setting page provides the following icons.
Icon |
Description |
|---|---|
| Create | Click this icon to create a constraint. |
| Delete | Click this icon to delete the selected constraint. |
Step 5: Set partitioning rules
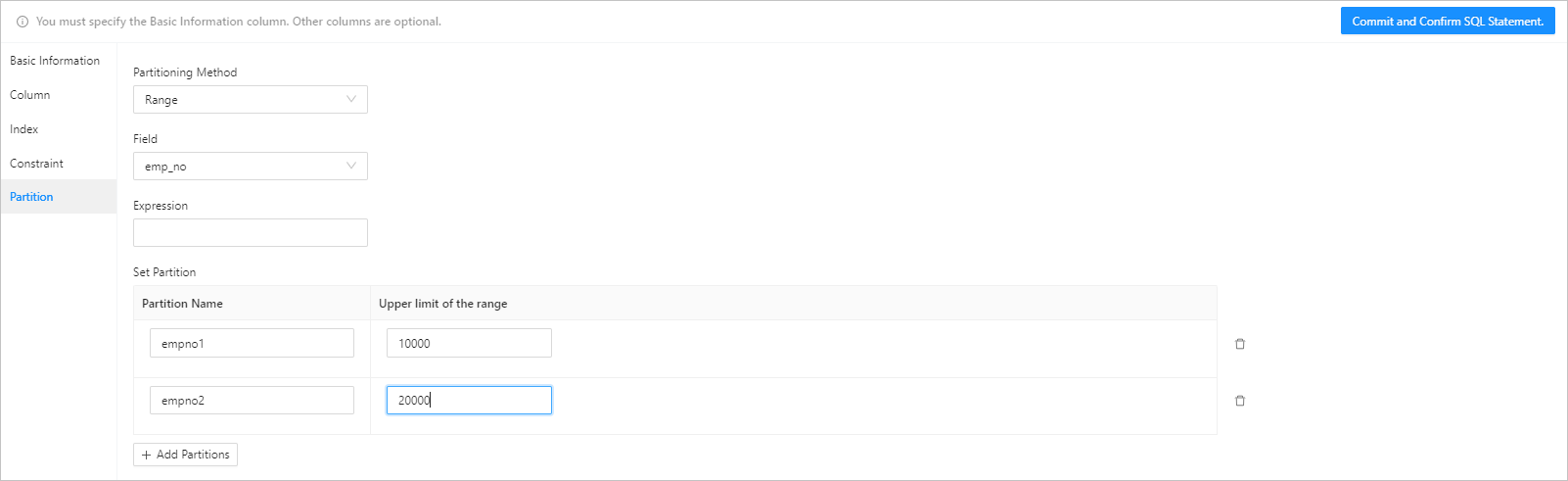
You can partition a table that contains a large amount of data. After a table is partitioned, data in the table is stored in multiple tablespaces. The database does not scan the entire table for a query.
In MySQL mode, OceanBase Database supports the following partitioning methods: KEY, HASH, RANGE, RANGE COLUMNS, LIST, and LIST COLUMNS.
In Oracle mode, OceanBase Database supports the following three partitioning methods: List, Range, and Hash.
The definition of a partition in MySQL mode is different from that in Oracle mode. So, the values of the following fields vary in different modes. You need to specify the following fields based on the selected partitioning method.
ParameterDescriptionPartitioning Method Specifies the partitioning method. The partitioning methods supported in MySQL mode are different from those in Oracle mode. - RANGE partitioning: Multiple rows with column values in an ordered, continuous, and non-overlapping range are assigned to a partition.
- LIST partitioning: A table is partitioned based on the enumeration values.
- HASH partitioning: A table is partitioned based on a given number of partitions. For a table that stores data without a clear pattern or range, you can use hash partitioning to randomly distribute values of the partition column to different partitions based on the HASH algorithm.
- KEY partitioning: This partitioning method is similar to HASH partitioning. The difference is that KEY partitioning supports computation of only one or more columns, and the MySQL server provides its own hash function. At least one INT type column is required for Key partitioning.
Field The column that is used as the partitioning key. Expression Partitions are divided based on the return value of the expression. The partition expression is not supported in Oracle mode. Partition Based on the value specified for Partitioning Method, you may need to specify information such as Partition Name, Partition Quantity, Upper Limit, and Value Enumeration. You can add multiple partitions and drag selected fields to adjust their order.
Step 6: Confirm the SQL statement
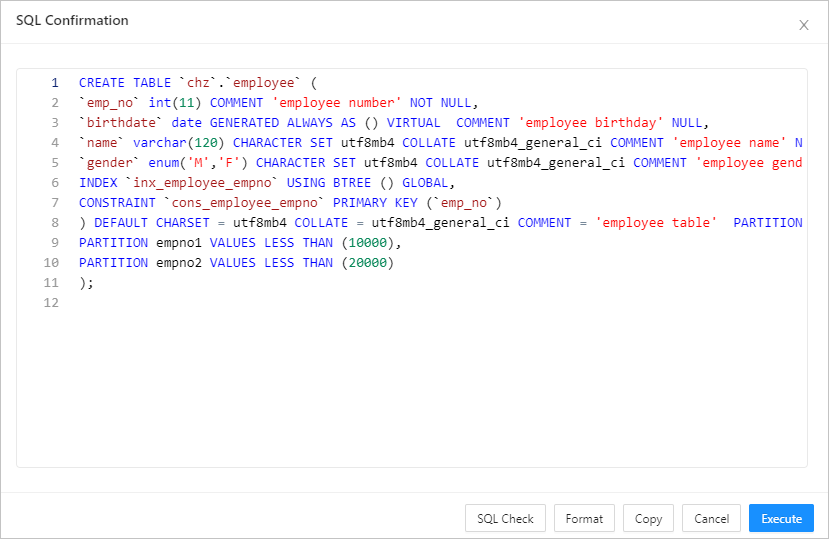
After you click Execute, you can view the statement on the SQL confirmation page. You can check and format the statement.
The syntax is as follows:
CREATE TABLE table_name (column_name column_type, column_name column_type,.......);
The following table describes the fields in the syntax.
Field |
Description |
|---|---|
| CREATE TABLE | The keyword that indicates the creation of a table with a specified name. You must have the permission to create tables. |
| table_name | The name of the table. The table name must conform to the identifier naming rules. |
| column_name column_type | The name and data type of each column in the table. Separate the tuples of multiple columns with commas (,). |
Step 7: Complete the table creation
Click Execute. After the table is created, the employee table appears in the table list in the left-side navigation pane.

Note
You can click the More icon next to a table name in the table list in the left-side navigation pane, and select View Table Schema, View Table Data, Import, Export, Download, Mock Data, Open SQL Window, Copy, Delete, or Refresh from the context menu to manage or operate the table. For more information, see Manage table data.
You can use the SELECT statement to query data in the new table.
The syntax is as follows:
SELECT
column_name,
column_name
FROM
table_name [WHERE Clause] [LIMIT N] [ OFFSET M]
The following table describes the fields in the syntax.
Field |
Description |
|---|---|
| SELECT | The keyword that indicates the name of the statement. You can use the SELECT statement to read one or more records. |
| column_name | The name of the column to be queried. You can use an asterisk (*) in the format of * to query all columns |
| WHERE | The keyword of the condition clause. |
| LIMIT | The number of records to be returned. |
| OFFSET | The data offset from which the SELECT statement starts to query. The default offset is 0. |
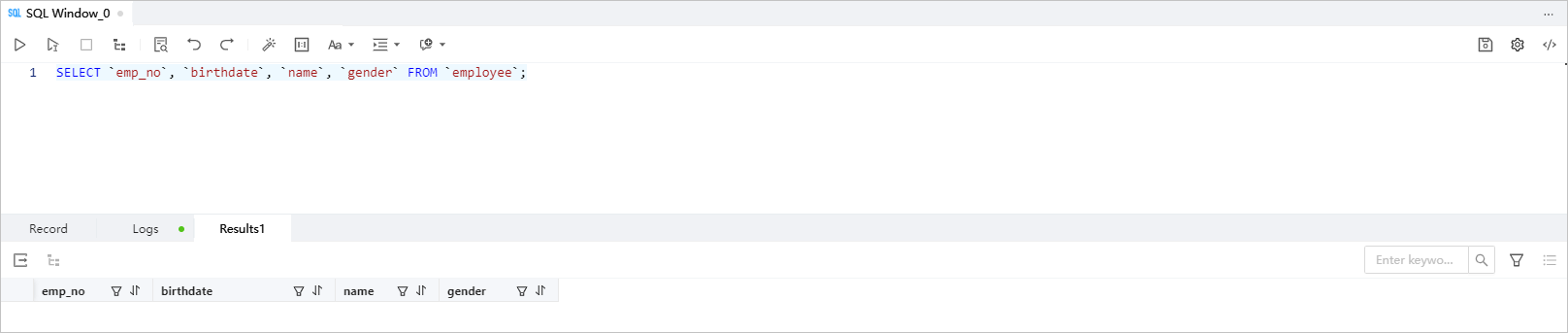
Here is an example:
SELECT `emp_no`, `birthdate`, `name`, `gender` FROM `employee`;
Step 1: Specify the basic information
Log on to the ODC console and click the name of the desired connection to go to the corresponding connection management page. You can click Table in the left-side navigation pane to view tables. To create a table, click the plus sign (+) in the upper-right corner of the table list or click Create in the top navigation bar.
In the Basic Info section, set the Table Name and Description parameters.
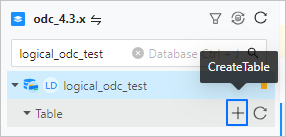
Note
- In MySQL mode, you also need to set the Default Character Set and Default Collation parameters.
- After you specify the basic information and go to the "Set columns" step, the basic information is submitted.
- Only OceanBase V4.3.0 and later versions support configuring columnar storage.
Step 2: Set columns
Note
In ODC V4.2.3 and later, you can create a table that contains columns of spatial data types in OceanBase Database in MySQL mode or MySQL Database.
The following figure and table show the information that you need to specify when you add a column.
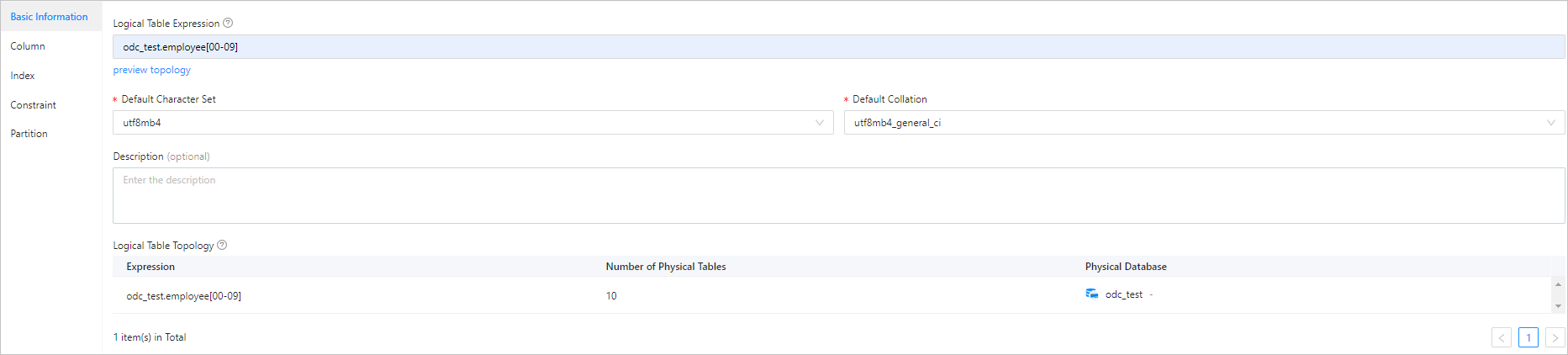
Parameter |
Description |
|---|---|
| Name | The name of the column. |
| Type | The data type of the column. For more information about data types, see OceanBase Database Developer Guide. |
| Length | The length of the data type. |
| Scale | The number of decimal places of the data type. |
| Non-empty | Specifies whether the value of the column is required. |
| Auto-increment | Specifies whether the column is an auto-increment column. This parameter is valid in MySQL mode.
Notice
|
| Virtual Column | Specifies whether to set the column as a virtual column.
Notice
|
| Default Value/Expression | The default value or expression of the column. |
| Comment | The additional information about the column. |
The following table describes operations that you can perform on the column setting page.
Operation |
Description |
|---|---|
| Toolbar operations | You can add or delete columns by using the top toolbar of the page. |
| Click a row ID |
|
| Right-click a row | You can right-click a row to select it, and then select Copy or Move Down from the context menu that appears. |
Note
- After you copy a row, you can paste the row by using the Command + V or Ctrl + V shortcut keys.
- The auxiliary editing section at the bottom of the page displays additional information about the selected column.
- The basic information and column settings are required. The settings in other configuration steps are optional. After you specify the basic information and column settings, you can submit the settings and confirm the SQL statement to create the table.
Step 3: Set indexes
If a table contains a large amount of data, you can use indexes to accelerate data queries. An index is a data structure that pre-sorts the values of one or more columns in a table. By using indexes, you can directly locate records that meet the conditions.
The following figure and table show the information that you need to specify when you set an index.
Parameter |
Description |
|---|---|
| Index Name | The name of the index. |
| Range | The default value is GLOBAL. Valid values: GLOBAL and LOCAL. |
| Method | The default value is BTREE, which is applicable to a global index. Valid values: Empty, BTREE, and HASH.
|
| Index Type | The default value is NORMAL. Valid values: NORMAL, UNIQUE, and FULLTEXT.
|
| Columns | The columns to be indexed. Pay attention to the order of the indexed columns. |
| Invisible | Specifies whether the index is invisible. |
The index setting page provides the following icons.
Icon |
Description |
|---|---|
| Create | Click this icon to create an index. |
| Delete | Click this icon to delete the selected index. |
Step 4: Set constraints
Constraints are used to specify data rules for a table. A data operation that violates the constraints is terminated.

ODC supports the following four types of table constraints:
PRIMARY KEY constraint: defines a primary key to uniquely identify each row of data in the table. A PRIMARY KEY constraint can be a field or a group of fields. You can set only one PRIMARY KEY constraint for a table, and you cannot modify the PRIMARY KEY constraint after you configure the constraint.
UNIQUE constraint: ensures that the data in a field or a group of fields is unique in the table. You can set multiple UNIQUE constraints in one table.
FOREIGN KEY constraint: associates one or more columns in two tables. A FOREIGN KEY constraint is used to maintain the data consistency and integrity between associated tables. After you complete the setting of FOREIGN KEY constraints, you cannot create new constraints or modify existing constraints.
CHECK constraints: checks the data in the database based on the configured check rules when you edit the data. Data modification is allowed only after the check is passed.
OceanBase Database supports different constraints in MySQL and Oracle modes, and different constraints require different information. Therefore, you need to specify the required information based on the constraint you selected and the requirements on the page.
Parameter |
Description |
|---|---|
| Constraint Name | The name of the constraint. |
| Column Information | The field or a group of fields specified as the constraint. |
| Associated Schema | The schema where the associated table is located when Foreign Key Constraint is used. The associated table is the parent table. This field is valid only in Oracle mode. |
| Associated Database | The database where the associated table is located when Foreign Key Constraint is used. The associated table is the parent table. This field is valid only in MySQL mode. |
| Associated Table | The associated table when Foreign Key Constraint is used. The associated table is the parent table. |
| Associated Field | The associated field when Foreign Key Constraint is used. The associated field is in the parent table. |
| Delete | Specifies the action to be performed on the current table when the data in the associated table is deleted. The current table is the child table, and the associated table is the parent table. The following four types of action are supported: CASCADE, NO ACTION, RESTRICT, and SET NULL. The actions supported in MySQL mode are different from those in Oracle mode.
|
| Update | Specifies the action to be performed on the current table when the data in the associated table is updated. The current table is the child table, and the associated table is the parent table. The following four types of action are supported: CASCADE, NO ACTION, RESTRICT, and SET NULL. The actions supported in MySQL mode are different from those in Oracle mode.
NoticeAt present, OceanBase Database does not support SET NULL. |
| Check Condition | Specifies the check rules for data verification when Check Constraint is enabled. |
The constraint setting page provides the following icons.
Icon |
Description |
|---|---|
| Create | Click this icon to create a constraint. |
| Delete | Click this icon to delete the selected constraint. |
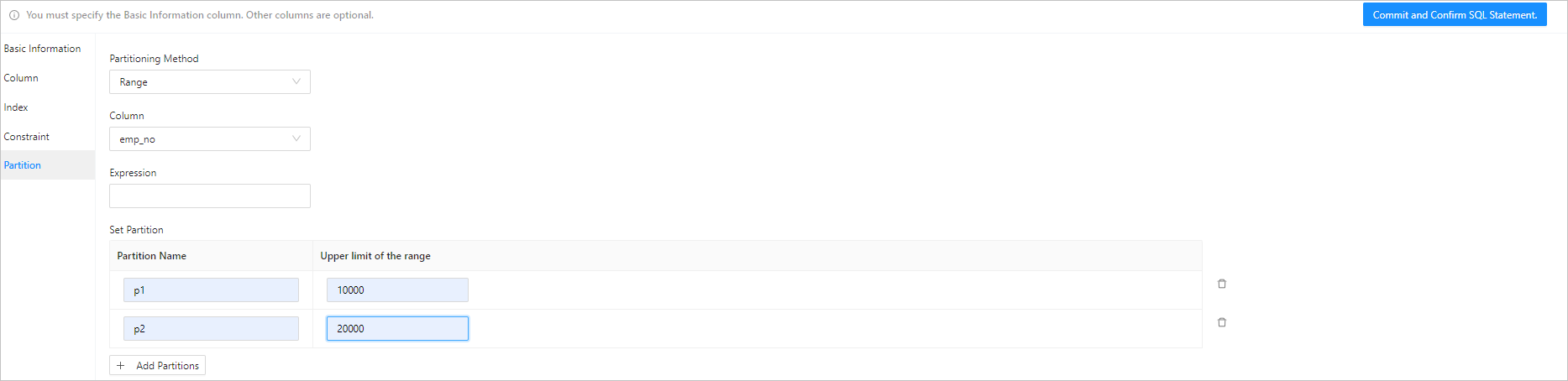
Step 5: Set partitioning rules

You can partition a table that contains a large amount of data. After a table is partitioned, data in the table is stored in multiple tablespaces. The database does not scan the entire table for a query.
In MySQL mode, OceanBase Database supports the following partitioning methods: KEY, HASH, RANGE, RANGE COLUMNS, LIST, and LIST COLUMNS.
In Oracle mode, OceanBase Database supports the following three partitioning methods: List, Range, and Hash.
The definition of a partition in MySQL mode is different from that in Oracle mode. So, the values of the following fields vary in different modes. You need to specify the following fields based on the selected partitioning method.
ParameterDescriptionPartitioning Method Specifies the partitioning method. The partitioning methods supported in MySQL mode are different from those in Oracle mode. - RANGE partitioning: Multiple rows with column values in an ordered, continuous, and non-overlapping range are assigned to a partition.
- LIST partitioning: A table is partitioned based on the enumeration values.
- HASH partitioning: A table is partitioned based on a given number of partitions. For a table that stores data without a clear pattern or range, you can use hash partitioning to randomly distribute values of the partition column to different partitions based on the HASH algorithm.
- KEY partitioning: This partitioning method is similar to HASH partitioning. The difference is that KEY partitioning supports computation of only one or more columns, and the MySQL server provides its own hash function. At least one INT type column is required for Key partitioning.
Field The column that is used as the partitioning key. Expression Partitions are divided based on the return value of the expression. The partition expression is not supported in Oracle mode. Partition Based on the value specified for Partitioning Method, you may need to specify information such as Partition Name, Partition Quantity, Upper Limit, and Value Enumeration. You can add multiple partitions and drag selected fields to adjust their order.
Step 6: Confirm the SQL statement
After you click Execute, you can view the statement on the SQL confirmation page. You can check and format the statement.
The syntax is as follows:
CREATE TABLE table_name (column_name column_type, column_name column_type,.......);
The following table describes the fields in the syntax.
Field |
Description |
|---|---|
| CREATE TABLE | The keyword that indicates the creation of a table with a specified name. You must have the permission to create tables. |
| table_name | The name of the table. The table name must conform to the identifier naming rules. |
| column_name column_type | The name and data type of each column in the table. Separate the tuples of multiple columns with commas (,). |
Step 7: Complete the table creation
Click Execute. After the table is created, the employee table appears in the table list in the left-side navigation pane.