

















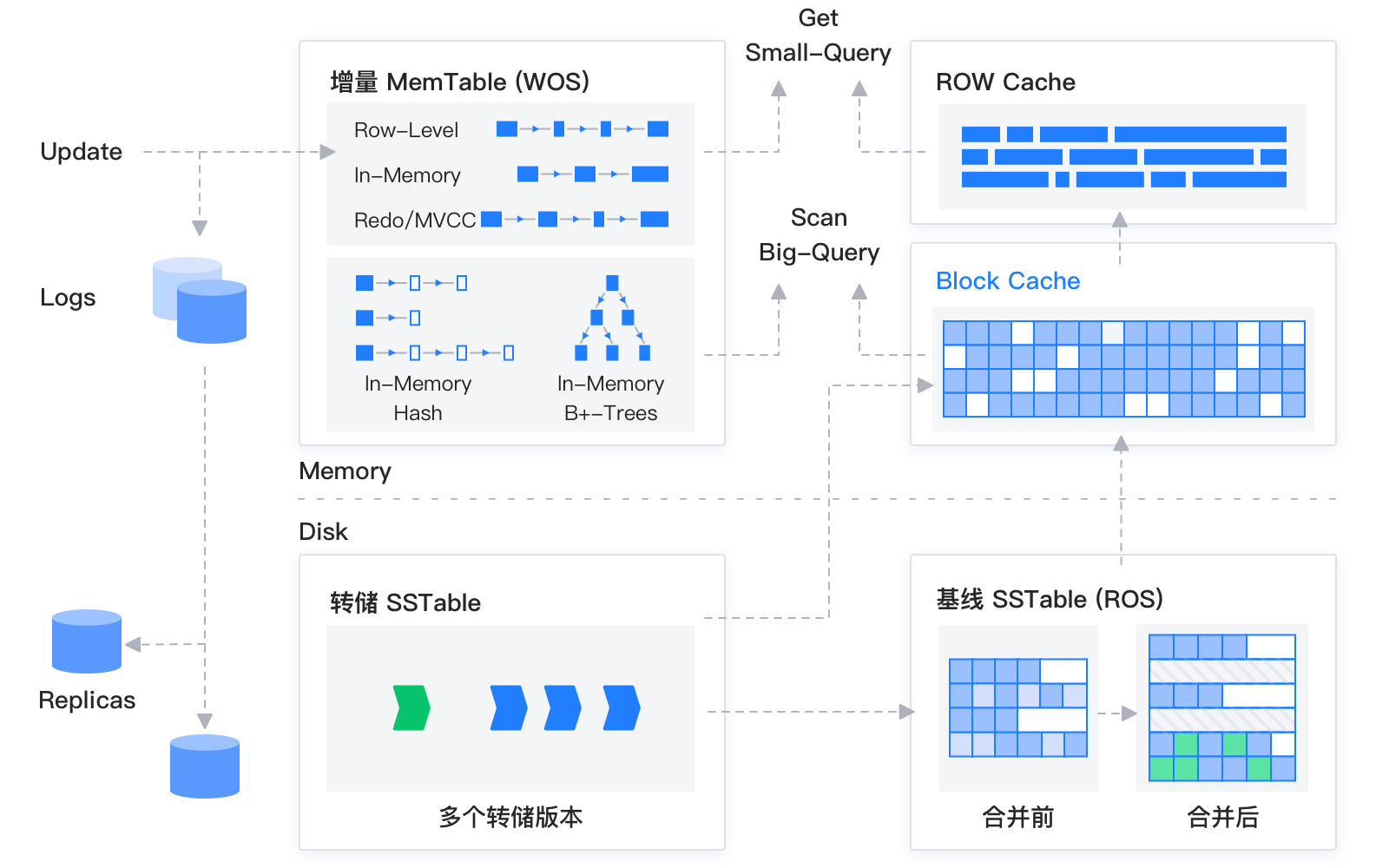
The storage engine of OceanBase Database is built on the LSM-tree architecture, which stores data as static baseline data in SSTables and dynamic incremental data in MemTables. SSTables are read-only and stored on disk, whereas MemTables support read and write operations and store in memory. During an insert, update, or delete operation, data is written to a MemTable. When the MemTable reaches a specified size, the data in the MemTable is flushed to the disk to become an SSTable. During a query, the storage engine queries the SSTable and MemTable, merges the query results, and returns the merged results to the SQL layer. In addition, the storage engine maintains a block cache and a row cache in memory to avoid random reads to baseline data.
When the incremental data in memory reaches a specified size, the incremental data and baseline data are merged and the incremental data is written to the disk. In addition, the system automatically performs a major compaction every evening.
The storage engine of OceanBase Database is a baseline plus incremental storage engine that combines the advantages of the LSM-tree architecture and traditional relational database storage engines.
Traditional databases divide data into many pages, and OceanBase database also draws on the concept of traditional databases, splitting data files into macro blocks with a basic granularity of 2MB. Each macro block is further divided into multiple variable-length micro blocks. During merging, data is reused based on the granularity of macro blocks, and macro blocks containing no updated data are not reopened for reading. This approach minimizes write amplification during the merge process as much as possible, significantly reducing the merge cost compared to traditional LSM-Tree architecture databases.
OceanBase Database is designed to store baseline data and incremental data. Each query needs to read both the baseline data and incremental data. To optimize single-row operations, OceanBase Database implements row caching in addition to block caching. The row cache can significantly speed up single-row queries. For "empty queries" that do not return any rows, a bloom filter is constructed and cached. Most operations in OLTP business are small queries. OceanBase Database avoids the overhead of parsing entire data blocks and achieves performance comparable to that of memory databases. In addition, baseline data is read-only and stored continuously. Therefore, OceanBase Database can use more aggressive compression algorithms to achieve a higher compression ratio without compromising query performance. This significantly reduces costs.
By integrating the advantages of classical databases and the LSM-tree architecture, OceanBase Database provides a more general relational database storage engine and has the following characteristics:
Low costs. Leveraging the fact that data written based on the LSM-tree architecture is not updated, OceanBase Database uses self-developed hybrid row-column encoding and general compression algorithms to achieve a higher storage compression ratio compared with traditional databases.
Ease of use. Unlike other databases that use the LSM-tree architecture, OceanBase Database ensures the performance of large or long transactions by allowing transactions in progress to be written to the disk, and helps users find the optimal balance between performance and space by using multi-level minor and major compactions.
High performance. The storage engine accelerates point queries using multiple caches to ensure ultra-low response latency. For range scans, the storage engine leverages data encoding features to push query filter conditions to the encoding layer and provides native vectorized support.
High reliability. In addition to end-to-end data verification, the storage engine verifies the correctness of user data by comparing replicas in global major compactions and by comparing the primary and index tables. It also uses background threads to scan data periodically to detect silent errors.
Components of the storage engine
The storage engine of OceanBase Database can be divided into the following components based on their features.
Data storage
Data organization
Like other LSM-tree databases, OceanBase Database stores data in incremental MemTables and static SSTables. MemTables support read and write operations and are stored in memory. SSTables are read-only and stored on disk after they are generated. DML operations such as insert, update, and delete are written to MemTables. When the size of a MemTable reaches the specified threshold, it is flushed to disk to become an SSTable.
In OceanBase Database, SSTables are further divided into mini SSTables, minor SSTables, and major SSTables. MemTables can be flushed to mini SSTables on disk through a minor compaction. When the number of mini SSTables reaches the specified threshold, a minor compaction is initiated to convert the mini SSTables into minor SSTables. Each partition generates a baseline SSTable (a major SSTable) on a daily basis. During a major compaction, all mini SSTables, minor SSTables, and the baseline SSTable of each partition are merged.
Storage structure
In OceanBase Database, each partition's basic storage unit is an SSTable, and the basic storage grain is a macroblock. When the database starts, the data file is divided into macroblocks of 2 MB in size. Each SSTable is actually a collection of macroblocks.
Each macroblock is divided into multiple microblocks. The concept of microblocks is similar to that of pages or blocks in a traditional database. However, microblocks in OceanBase Database are variable-length and can be compressed. The size of microblocks can be specified by using the
block_sizeparameter when the table is created.Microblocks can be stored in encoding or flat format based on the specified storage format. Microblocks stored in encoding format have data that is hybridly stored in row and column modes. For microblocks stored in flat format, all data rows are stored in a flattened manner.
Compression and encoding
OceanBase Database uses compression and encoding to compress data within microblocks based on the compression and encoding mode specified for the table. When encoding is enabled for the table, data in each microblock is encoded by column. Several encoding rules, such as dictionary, run-length, constant, and delta encoding, are supported. After the compression of each column is completed, the columns are further encoded based on rules such as equal value and sub-string encoding. This not only helps to significantly compress the data but also accelerates subsequent queries by extracting features within columns.
After compression and encoding, OceanBase Database allows you to use a general lossless compression algorithm specified by you to compress the microblock data, further improving the compression ratio.
Minor and major compactions
Minor compaction
A minor compaction, which is also known as a mini compaction, is triggered when the memory usage of the MemTables exceeds the specified threshold. This process involves flushing the data in the MemTables to mini SSTables on disk to release the memory space. As user data is written, the number of mini SSTables increases. When the number of mini SSTables reaches the specified threshold, the system automatically initiates a minor compaction in the background. Multiple mini SSTables are merged into one or more minor SSTables during a minor compaction.
Major compaction
A major compaction, also known as a daily major compaction in OceanBase Database, differs from that in other LSM-tree databases. As the name suggests, the major compaction was originally designed to be initiated for the entire cluster at around 2 AM every day. During a major compaction, a global snapshot is taken. Then, a major compaction is performed on all partitions based on the snapshot data. This generates SSTables for all data in the tenant based on the same snapshot. This mechanism helps users regularly integrate incremental data and improve read performance. In addition, the unified snapshot provides a natural data verification point. OceanBase Database can perform multi-dimensional physical data verification of multi-replica data and primary/foreign table indexes based on the global consistent checkpoint.
Queries and writes
Insert
In OceanBase Database, all data tables can be seen as index cluster tables. Even a heap table without a primary key, OceanBase Database maintains a hidden primary key for it. Therefore, when you insert data, OceanBase Database needs to check whether the data with the same primary key already exists in the MemTable before writing the new user data. To speed up the performance of repeated primary key queries, OceanBase Database schedules the construction of a Bloom filter for each SSTable asynchronously based on the background thread and different macroblock-level repletion frequencies.
Update
As an LSM-tree database, OceanBase Database inserts a new row of data for each update. Unlike clogs, data updates in MemTables include only the new values of the updated columns and the primary key of the updated row. Therefore, an updated row does not necessarily contain all columns of the table. During ongoing background compactions, incremental updates are merged to accelerate user queries.
Delete
Similar to updates, deletions are also performed by writing a deletion row that contains the primary key of the deleted row and marking the row for deletion through the row header. The mark indicates that the data is deleted. A large number of deletions are not friendly to an LSM-tree database, because after all data in a specific data range is deleted, the database still needs to iterate all deleted-marked rows in the data range to perform data compaction and then determine the deletion status. To address this issue, OceanBase Database has inherent range deletion marking logic. Additionally, you can explicitly specify a table mode to enable efficient minor and major compactions, accelerating the deletion process and improving query efficiency.
Query
When you query a specific row of data, OceanBase Database needs to traverse MemTables and SSTables from new to old versions to find the data with the specified primary key and return the data by fusing the data from each table. During data access, caches are used to accelerate data access. In a large query, the SQL layer pushes down filter conditions to the storage layer and uses data characteristics for quick filtering. Additionally, vectorized batch calculations and result returns are supported in batch processing scenarios.
Multi-level cache
To improve performance, OceanBase Database supports a multi-level cache system. It provides a block cache for microblocks, a row cache for each SSTable, a fuse row cache for query results, and a Bloom filter cache for insert check. All caches in the same tenant share the memory space. When the write speed of MemTables is too fast, memory can be dynamically occupied from the caches for write use.
Data verification
As a financial-grade relational database, OceanBase Database prioritizes data quality and security. Data verification is performed on every part of the data persistence layer of the data chain, and the inherent advantage of multi-replica storage is used to add inter-replica data verification, ensuring the overall data consistency.
Logical verification
In a common deployment mode, each user table in OceanBase Database has multiple replicas. During daily major compactions in a tenant, all replicas generate baseline data based on a global unified snapshot version. Replicas then compare the checksums of the data to verify consistency. Based on the user table replicas, the checksums of the index columns are also compared to ensure that the data returned to users is correct and error-free.
Physical verification
For data storage, OceanBase Database records the checksums of corresponding primary keys at the minimum I/O granularity, namely, microblocks, for data verification. The checksums of macroblocks, SSTables, and partitions are also recorded. Each time data is read, the data is verified based on the checksums. To prevent issues caused by underlying storage hardware, the data in macroblocks is verified after the data is written and immediately re-verified. Each server also has a scheduled data scan thread to verify the overall data to identify and resolve silent disk errors in advance.