

















OceanBase Database adopts a shared-nothing distributed cluster architecture, where all nodes are equal. Each node has its own SQL engine, storage engine, and transaction engine, and runs on a cluster of ordinary PC servers. This architecture offers high scalability, high availability, high performance, cost-effectiveness, and strong compatibility with mainstream databases. For more information, see Deployment architectures.
OceanBase Database uses commodity server hardware and relies on local storage. In a distributed deployment, the servers are also equal and do not require special hardware. The distributed processing in OceanBase Database uses the shared-nothing architecture. The SQL execution engine within a database supports distributed execution.
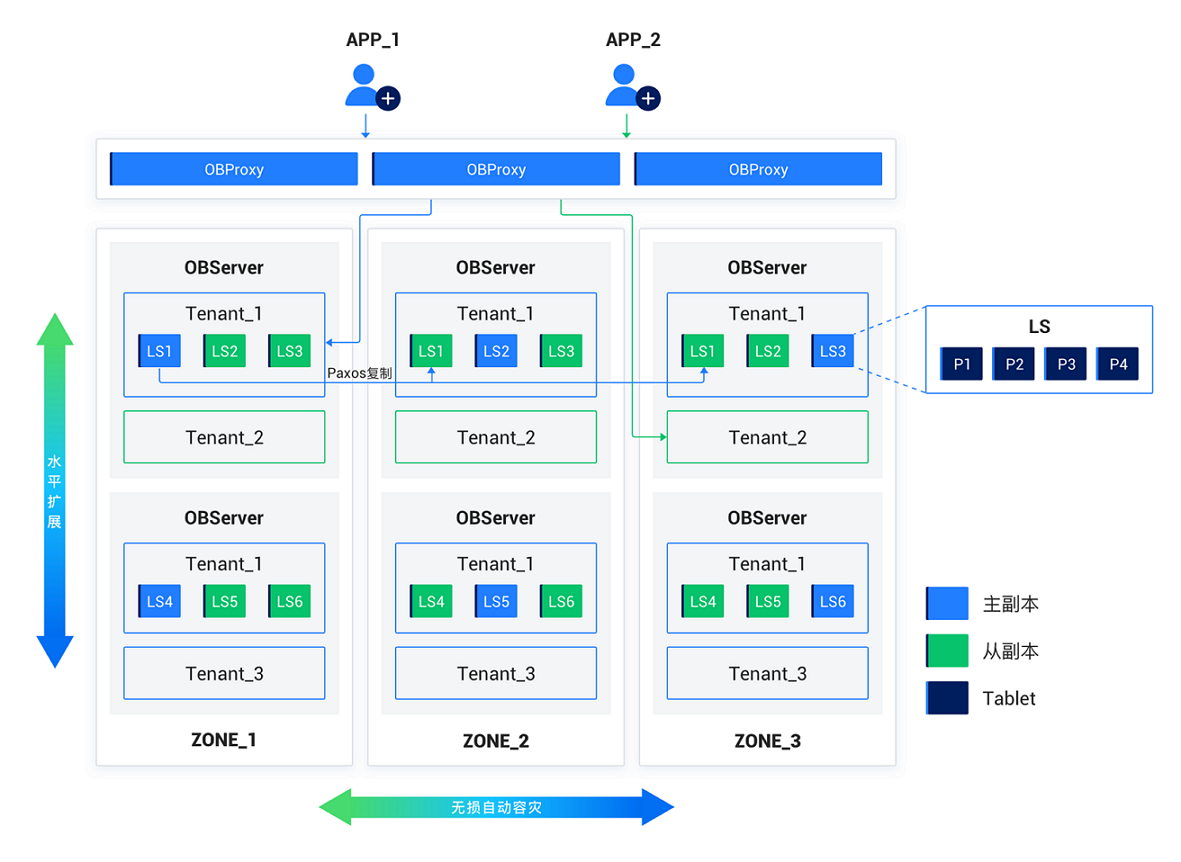
OceanBase Database runs an observer process on each server as the runtime instance of the database. The observer process stores data and transaction redo logs in local files.
When you deploy an OceanBase cluster, you must configure availability zones (Zones). Each zone consists of multiple servers. A zone is a logical concept that represents a group of nodes that share hardware availability within the cluster. Its meaning varies depending on the deployment mode. For example, in a scenario where the cluster is deployed in one IDC, nodes in a zone may belong to the same rack or the same switch. If the cluster is deployed across IDCs, each zone can correspond to one IDC.
The distributed cluster stores multiple replicas of your data for disaster recovery and pressure relief. A zone stores only one replica of data for the same tenant. Multiple zones can store multiple replicas of the same data. Paxos is used to ensure data consistency among replicas.
OceanBase Database has the multi-tenant feature built in. Each tenant is an independent database instance. You can set the distributed deployment mode of a tenant at the tenant level.
The components that collaborate to run an instance of OceanBase Database from the underlying layer to the upper layer are the multi-tenant layer, storage layer, replication layer, load balancing layer, transaction layer, SQL layer, and access layer.
Multi-tenant layer
To simplify the management of multiple business databases in large-scale deployments and reduce resource costs, OceanBase Database offers the unique multi-tenant feature. In an OceanBase cluster, you can create many isolated "instances" of databases, which are called tenants. From the perspective of applications, each tenant is a separate database. In addition, each tenant can be configured in MySQL- or Oracle-compatible mode. After your application is connected to a MySQL-compatible tenant, you can create users and databases in the tenant. The user experience is similar to that with a standalone MySQL database. In the same way, after your application is connected to an Oracle-compatible tenant, you can create schemas and manage roles in the tenant. The user experience is similar to that with a standalone Oracle database. After a new cluster is initialized, a tenant named sys is created. The sys tenant is a MySQL-compatible tenant that stores the metadata of the cluster.
To isolate the resources of different tenants, each observer process can have multiple virtual containers belonging to different tenants. These containers are called resource units (UNIT). The resource units of each tenant across multiple nodes form a resource pool. The resource units include CPU and memory resources.
Storage layer
The storage layer provides data storage and access on a table or partition basis. Each partition corresponds to a tablet (shard), and user-defined non-partitioned tables correspond to a tablet as well.
The internal structure of a tablet is a multi-layer storage architecture. It consists of four layers: MemTable, L0-level mini SSTable, L1-level minor SSTable, and major SSTable. DML operations, such as insert, update, and delete, write data to the MemTable first. When the MemTable reaches a specified size, the data in the MemTable is flushed to the disk to become an L0-level mini SSTable. When the number of L0-level mini SSTables reaches the threshold, multiple L0-level mini SSTables are merged into an L1-level minor SSTable. During off-peak hours of a day, the system merges all MemTables, L0-level mini SSTables, and L1-level minor SSTables into a major SSTable.
Each SSTable consists of several fixed-size macroblocks of 2 MB each. Each macroblock contains multiple variable-size microblocks.
The microblocks of a major SSTable are encoded during the merge. The data in the microblocks is encoded by column, and encoding techniques such as dictionary, run-length, constant, and difference values are supported. After each column is compressed, the columns are further encoded by using techniques such as equal value and substring encoding. This encoding can significantly reduce the size of data and accelerate future queries by refining columnar features.
After encoding compression, the data can be compressed again by using a specified general compression algorithm to further improve the compression ratio.
Replication layer
The replication layer uses log streams (LS, Log Stream) to synchronize the status among replicas. Each tablet corresponds to a specific log stream, and multiple tablets can correspond to one log stream. The redo logs generated by DML operations written to tablets are persisted in the corresponding log streams. Multiple replicas of a log stream are distributed across different availability zones, and a consensus algorithm is maintained among the replicas. One of the replicas is elected as the leader, and the other replicas serve as followers. DML operations and strong-consistency queries are performed only on the leader.
Usually, each tenant has only one leader on each server, but can have multiple followers. The total number of log streams of a tenant depends on the configurations of the primary zone and locality.
Log streams use an improved Paxos protocol to persist redo logs on the local server and send the redo logs over the network to followers. After each follower persists the redo logs, it responds to the leader. The leader confirms that the redo logs are persisted successfully upon receiving responses from a majority of followers. A follower keeps replaying the redo logs in real time to ensure consistency with the leader.
The leader of a log stream becomes the primary replica after it is elected. A normally working primary replica continuously extends its lease period through elections within the lease period. The primary replica performs only primary tasks when the lease is valid. The lease mechanism ensures the robustness of exception handling in the database.
The replication layer can automatically respond to server failures to ensure the continuous availability of database services. If less than half of the followers of a log stream are on the failed servers, namely, more than half of the replicas are still working, the database services are not affected. If the server where the leader is located encounters a problem, its lease cannot be extended. After the lease expires, other followers will elect a new leader and grant a new lease to the new leader. Then, the database services can be restored.
Balancing layer
When you create a table or a partition, the system selects appropriate log streams to create a tablet based on the balancing principle. When the attributes of the tenant change, new machine resources are added, or tablets are unevenly distributed across machines after a long period of use, the balancing layer will balance data and services across servers by splitting and merging log streams and moving log stream replicas during the process.
When the tenant expands and obtains more server resources, the balancing layer splits the existing log streams within the tenant and selects an appropriate number of tablets to split into new log streams. Then, the new log streams are migrated to the new servers to make full use of the expanded resources. When the tenant contracts and some servers are to be released, the balancing layer migrates the log streams on the servers to be released to other servers and merges them with other servers' log streams to reduce the resource usage of the servers.
With the long-term use of the database, users continuously create or delete tables and write more data. Even if the number of server resources remains unchanged, the original balance may be destroyed. A common scenario is that after you delete a batch of tables, the tablets on the servers where the tables are originally aggregated are fewer. The tablets on other servers can be evenly distributed to these servers. The balancing layer regularly generates balancing plans, splits log streams into temporary log streams carrying the tablets to be moved, and migrates the temporary log streams to the destination servers where they are merged with the existing log streams on the destination servers to achieve the purpose of balancing.
Transaction layer
The transaction layer ensures the atomicity of DML operations in a single log stream or multiple log streams and the multiversion isolation between concurrent transactions.
Atomicity
The write-ahead logs in a log stream guarantee the atomicity of transactions modifying multiple tablets. When a transaction modifies multiple log streams, write-ahead logs are generated and persisted in each log stream. The transaction layer ensures the atomicity of transactions through an optimized two-phase commit protocol.
When a transaction that modifies multiple log streams initiates a commit, the transaction selects one of the log streams as the coordinator for the two-phase commit. The coordinator communicates with all log streams modified by the transaction to check whether the write-ahead logs are persisted. After all log streams complete persistence, the transaction is in the commit state. Then, the coordinator drives all log streams to write the commit log of the transaction, indicating the final commit status of the transaction. During log stream replay or database restart, transactions that have been committed determine the status of their log streams based on the commit logs.
In the case of a database restart after a crash, write-ahead logs may be written in the crashed log streams but the commit logs are not written. Each log stream has a list of all transaction logs. Using this information, the system can re-identify the coordinator, restore the state of the coordinator, and proceed with the two-phase commit protocol until the transaction reaches the final commit or abort status.
Isolation
The Global Timestamp Service (GTS) is a service that generates continuous and increasing timestamps for the tenant. It ensures availability through multi-replica deployment. The mechanism is the same as the log stream replica synchronization mechanism described in the preceding Replication layer section.
Each transaction obtains a timestamp from the GTS as the commit version number for the transaction and persists the timestamp in the write-ahead log of the log stream. The data modified in the transaction is marked with the commit version number.
Each statement (for the Read Committed isolation level) or transaction (for the Repeatable Read and Serializable isolation levels) starts by obtaining a timestamp from the GTS as the read version number. When data is read, transactions skip data modified in transactions with higher version numbers and choose the latest data whose version number is smaller than the read version number. This way, unified global data snapshots are provided for all read operations.
SQL layer
The SQL layer converts an SQL request into data access requests for one or more tablets.
SQL components
The execution process of an SQL request is as follows: parser, resolver, transformer, optimizer, code generator, and executor.
The parser is responsible for lexical or syntax parsing. It breaks down the user's SQL statement into individual "tokens" and then parses the entire request based on the predefined syntax rules to generate a syntax tree (Syntax Tree).
The resolver is responsible for semantic parsing. Based on the database metadata, it translates the tokens in SQL requests into corresponding objects (such as databases, tables, columns, and indexes). The data structure generated by this process is called a statement tree.
The transformer is responsible for logical rewriting. Based on internal rules or a cost model, it rewrites an SQL query into an equivalent query in another form and provides the rewritten query to the subsequent optimizer for further optimization.
A transformer works by performing equivalent transformations on the original statement tree. The result is still a statement tree.
The optimizer (optimizer) generates the best execution plan for SQL requests. It takes into account the semantics of SQL requests, data characteristics of objects, and physical distribution of objects to select the access path, join order, join algorithm, and distributed execution plan, ultimately generating the execution plan.
The code generator (codegen) converts execution plans into executable code without making any optimization choices.
The executor (executor) starts the execution process of an SQL statement.
In addition to the standard SQL process, the SQL layer has the Plan Cache feature, which caches historical execution plans in memory. This allows subsequent executions to reuse the plans from the cache, avoiding the need to optimize the queries repeatedly. The Fast-parser module directly parameters a text string by using only lexical analysis, and then returns the parameterized text and constant parameters. This enables SQL to directly hit the Plan Cache, accelerating frequently executed SQL statements.
Multiple plans
Execution plans at the SQL layer are classified into local, remote, and distributed plans. A local plan accesses only data on the local server. A remote plan accesses only data on a remote server. A distributed plan accesses data on more than one server. The execution plan is divided into multiple subplans for execution on multiple servers.
SQL layer parallel execution capability allows an execution plan to be decomposed into multiple parts and executed by multiple execution threads. These parts are scheduled and processed in parallel. This way, the CPU and I/O capabilities of the server can be fully leveraged to shorten the response time of a query. Parallel query technology can be applied to distributed execution plans as well as local execution plans.
Access layer
OceanBase Database Proxy (ODP, also known as OBProxy) is the access layer of OceanBase Database. It forwards user requests to an appropriate OceanBase Database instance for processing.
ODP is an independent process instance deployed separately from an OceanBase database instance. ODP listens to a network port and is compatible with the network protocols of MySQL. This allows applications to directly connect to OceanBase Database using a MySQL driver.
ODP can automatically discover the tenants and data distribution of an OceanBase cluster. For each SQL statement proxied, ODP can identify the data to be accessed by the statement and forward it directly to the OceanBase Database instance where the data is located.
ODP can be deployed on each application server that needs to access the database or on the server where OceanBase Database resides. In the first deployment mode, the application directly connects to ODP deployed on the same server. Then, ODP sends the requests to an appropriate OceanBase Database server. In the second deployment mode, the network load balancing service is used to aggregate multiple ODPs into one service entry address for application access.