
















A join combines the output from two data sources, such as tables or views, and returns one data source. A join is characterized by multiple tables in the WHERE (non-ANSI) or FROM ... JOIN (ANSI) clause of a SQL statement. Whenever multiple tables exist in the FROM clause, OceanBase Database performs a join.
A join condition defines the relationship between the tables. If the statement does not specify a join condition, then the database performs a Cartesian join, matching every row in one table with every row in the other table.
Join trees
Typically, a join tree is represented as an upside-down tree structure. As shown in the following diagram, T1 is the left table, also known as the driving table, which is usually a dimension table. T2 is the right table, which is usually a fact table. The optimizer generally processes the join from left to right.

The input of a join can be the result from a previous join. If the left data source of each node is the result of another join, and the right data source of each node is a table, then the tree is a left deep join tree, as shown in the following example. Most join trees are left deep joins.
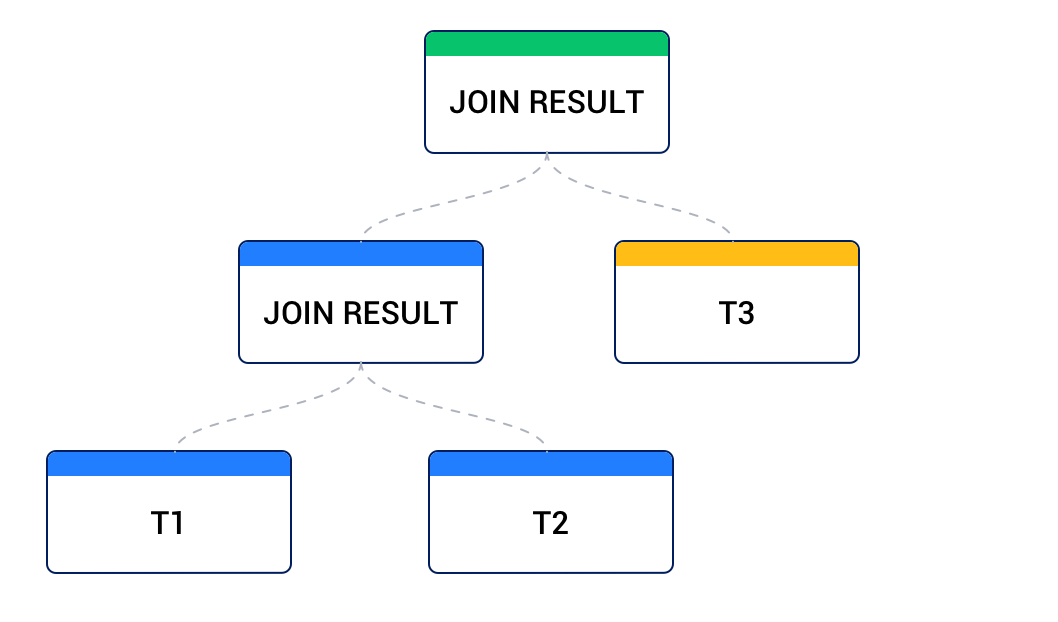
If the right data source of each node is the result of another join, and the left data source of each node is a table, then the tree is a right deep join tree, as shown in the following diagram.
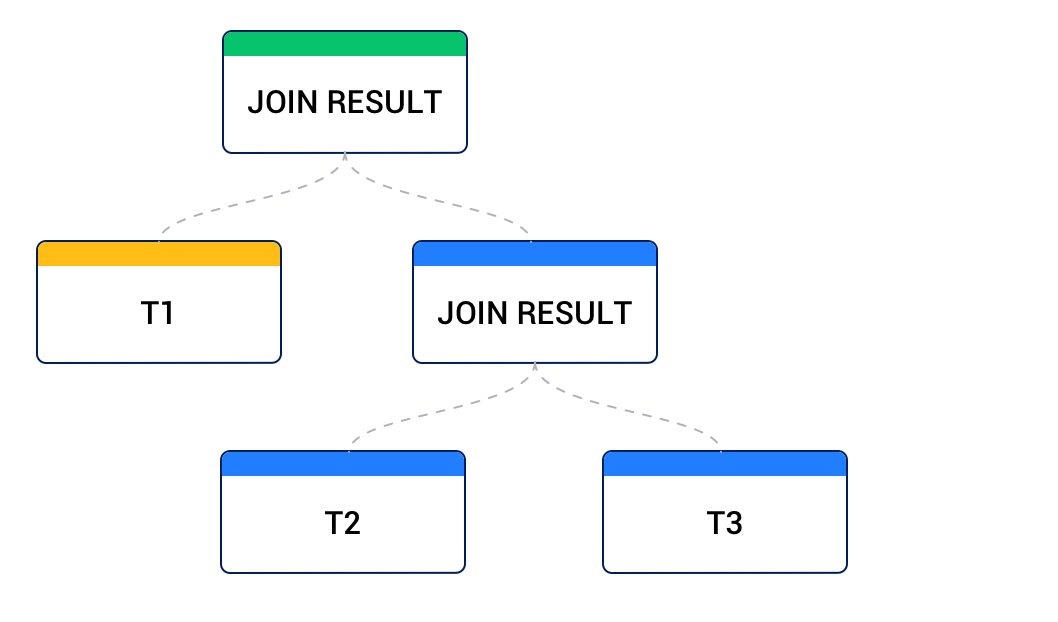
If any node is in a different form from other nodes, then the tree is a bushy join tree, as shown in the following diagram.

How the optimizer optimizes joins
When multiple tables exist in the FROM clause, the optimizer must determine which join operation is most efficient for each pair. The optimizer must make the decisions shown in the following table.
Operation |
Description |
|---|---|
| Base table path | For each base table, the optimizer must select the best scan mode. For example, the optimizer might choose between a primary table scan or an index scan. |
| Join methods | To join two data sources, the optimizer must decide which join method to use. The available methods are nested loop join, merge join, and hash join. Each join method has specific situations in which it is more suitable than the others. The optimizer must select the optimal one based on statistics. |
| Join types | The optimizer supports the following join types: inner join, left join, right join, full join, left semi join, right semi join, left anti join, right anti join, and connect by join. Joins of the last five types are generated after basic joins are rewritten by the optimizer, and cannot be specified in SQL syntax. |
| Join order | To execute a statement that joins more than two tables, the optimizer needs to decide the optimal join order. For example, for FROM T1, T2, T3, the possible join orders are T1 JOIN T2 JOIN T3, T1 JOIN T3 JOIN T2, and so on. The optimizer needs to select the join order with the best execution performance. |
How the optimizer chooses execution plans for joins
When determining the join order and method, the goal of the optimizer is to reduce the number of rows as early as possible so it performs less work throughout the execution of the SQL statement. The optimizer generates a set of execution plans, according to possible join orders, join methods, and available access paths. The optimizer then estimates the cost of each plan and chooses the one with the lowest cost.
The optimizer estimates the cost of a query plan by calculating the I/O, network, and CPU overheads. Different data distribution methods have different network overheads. Different functions and expressions also have different CPU overheads. The optimizer uses these metrics to determine the total cost of a query plan. These metrics can be affected by many initialization parameters and session settings, such as PARALLEL, ENABLE_ROWSETS, and system statistics, during compilation.
For example, the optimizer estimates the cost in the following ways:
- The cost of a nested loop join depends on the cost of reading each selected row of the outer table and each of its matching rows of the inner table into memory. The optimizer estimates the cost using statistics on the inner table.
- The cost of a merge join largely depends on the cost of reading all the sources into memory and sorting them.
- The cost of a hash join largely depends on the cost of building a hash table on one input side to the join and using the rows from the other side of the join to probe it.