

















OceanBase Database adopts a shared-nothing architecture with multiple replicas to ensure zero single point of failure and system continuity. OceanBase Database supports high availability and disaster recovery (HA/DR) at the IDC (single IDC deployment of OceanBase clusters), region (multi IDC deployment of OceanBase clusters in the same region), and geo-region (multi-region deployment of OceanBase clusters) levels. You can deploy OceanBase clusters in one IDC, deploy OceanBase clusters across two IDCs in the same region, deploy OceanBase clusters across three IDCs in two regions, or deploy OceanBase clusters across five IDCs in three regions. You can also deploy the arbitration service to reduce costs.
Deployment solutions
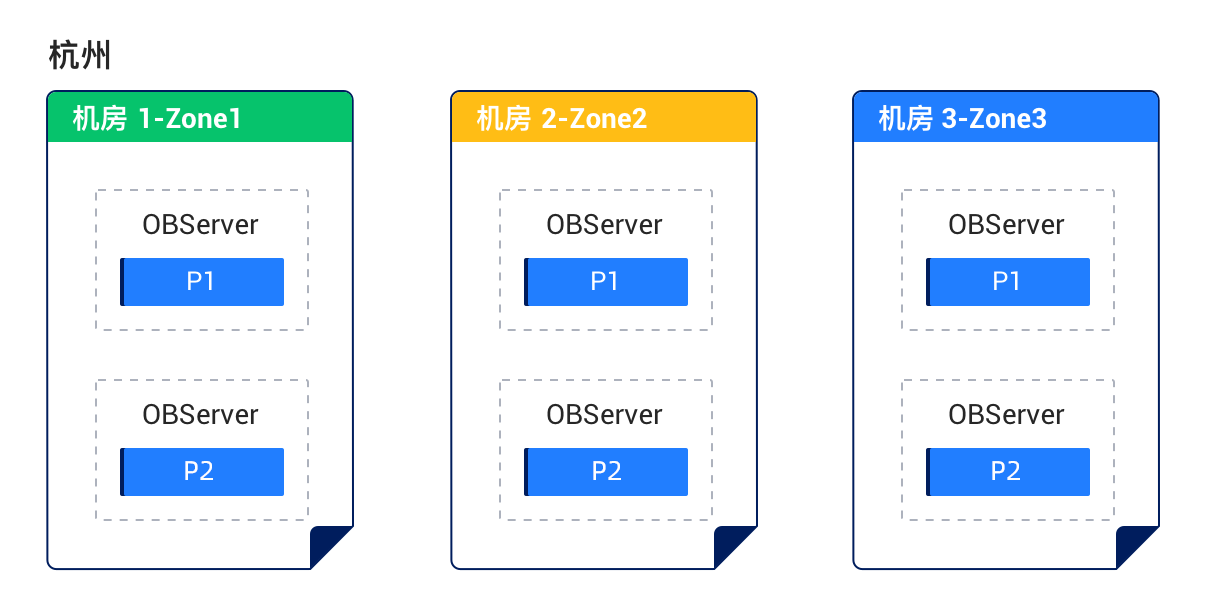
Solution 1: Deploy three replicas across three IDCs in one region
Characteristics:
- The three IDCs form one cluster (each IDC is a zone). The network latency between IDCs ranges from 0.5 to 2 ms.
- After a disaster in one IDC, the remaining two replicas can still ensure the majority and continue to synchronize redo logs to meet the RPO=0 requirement.
- The solution cannot protect against disasters at the region level.
Deployment diagram:
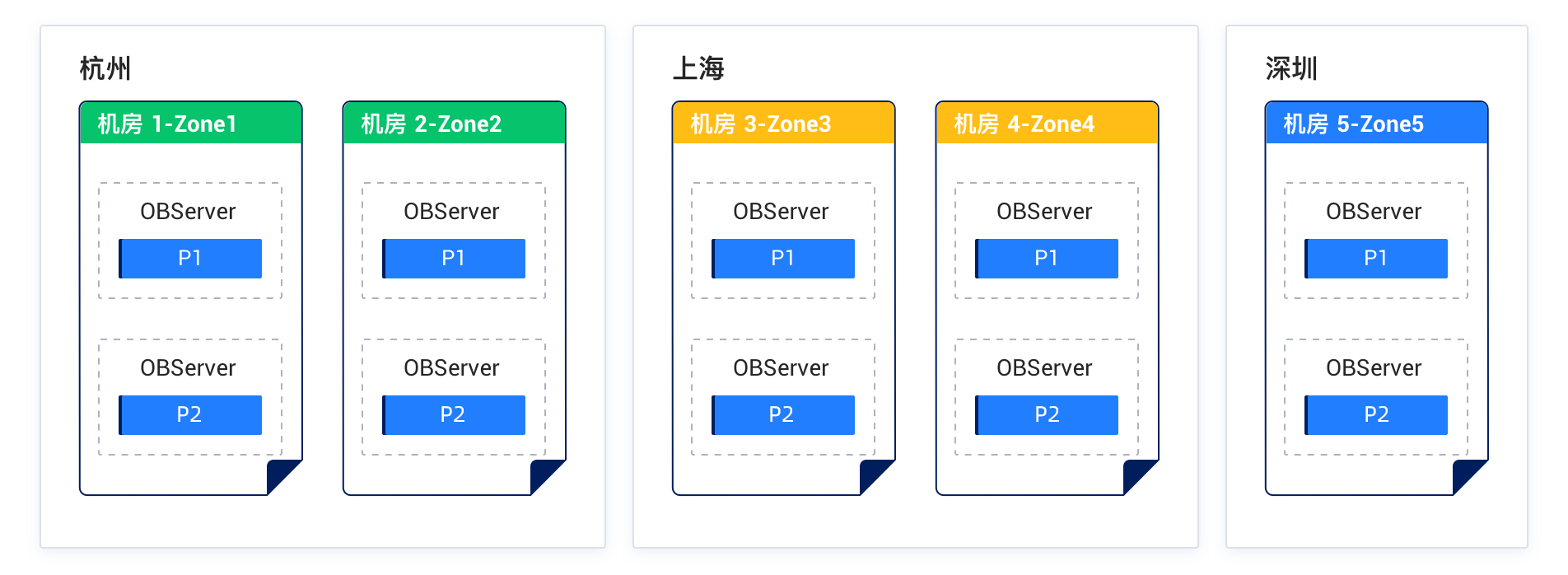
Solution 2: Deploy five replicas across three IDCs in two regions
Characteristics:
- The five replicas across three IDCs in two regions form one cluster.
- After the failure of any IDC or region, the remaining replicas can still ensure the majority and synchronize redo logs to the remaining replicas to meet the RPO=0 requirement.
- More than three replicas are required to ensure the majority. Therefore, to reduce the network latency of synchronizing redo logs, IDCs in the same region should be located as close as possible.
Deployment diagram:
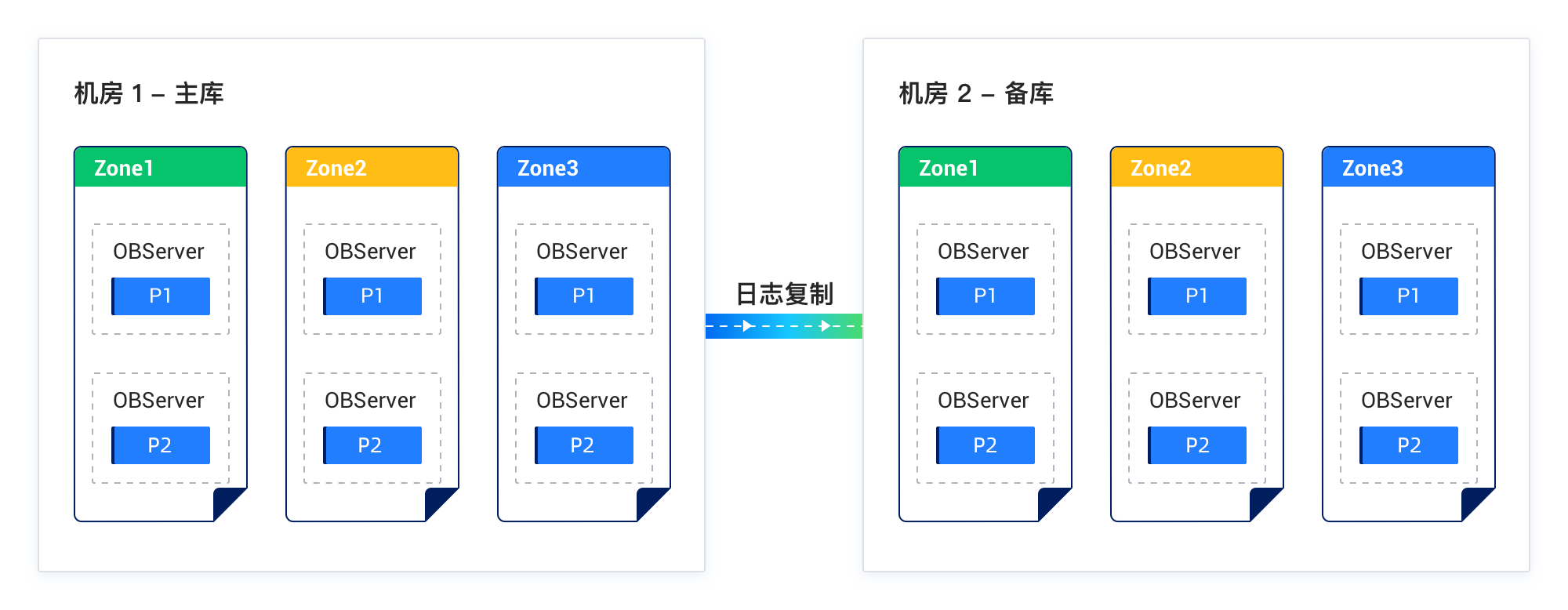
Solution 3: Deploy two OceanBase clusters in "primary/standby" configuration across two IDCs in one region
Characteristics:
- An OceanBase cluster is deployed in each IDC. The IDCs are located in different zones. Each cluster has its own Paxos group to ensure multi-replica consistency.
- Data is synchronized between clusters through redo logs. This setup is similar to the conventional "primary/standby" replication mode in which data is asynchronously synchronized from the primary database to the standby database.
Deployment diagram:
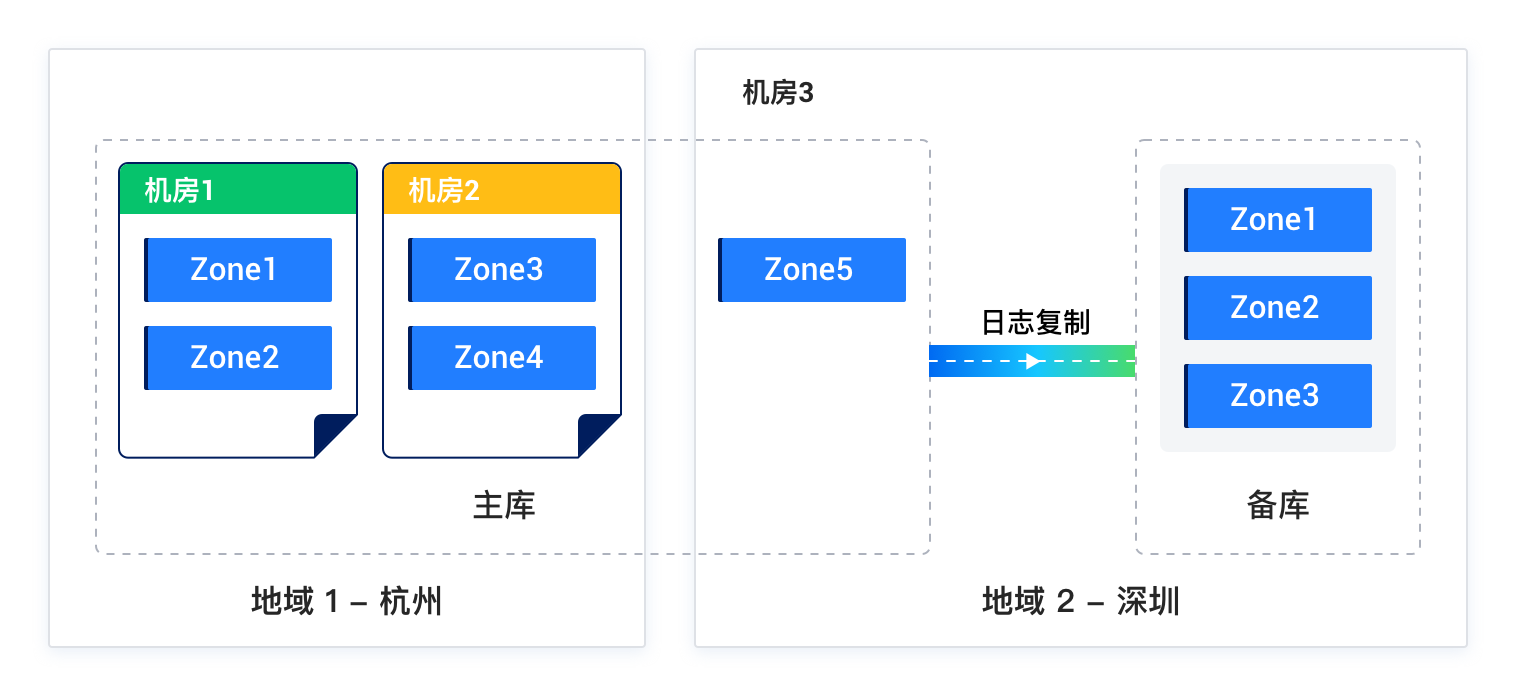
Solution 4: Deploy three IDCs in "primary/standby" configuration across two regions
Characteristics:
- The IDCs in the primary region and the standby region form one cluster. A disaster in the IDCs of the primary region can result in the loss of at most two replicas. The remaining three replicas can still ensure the majority.
- The standby region builds an independent three-replica cluster as a standby database. The primary database asynchronously synchronizes data to the standby database.
- If the primary region encounters a disaster, the standby region can take over the business.
Deployment diagram:
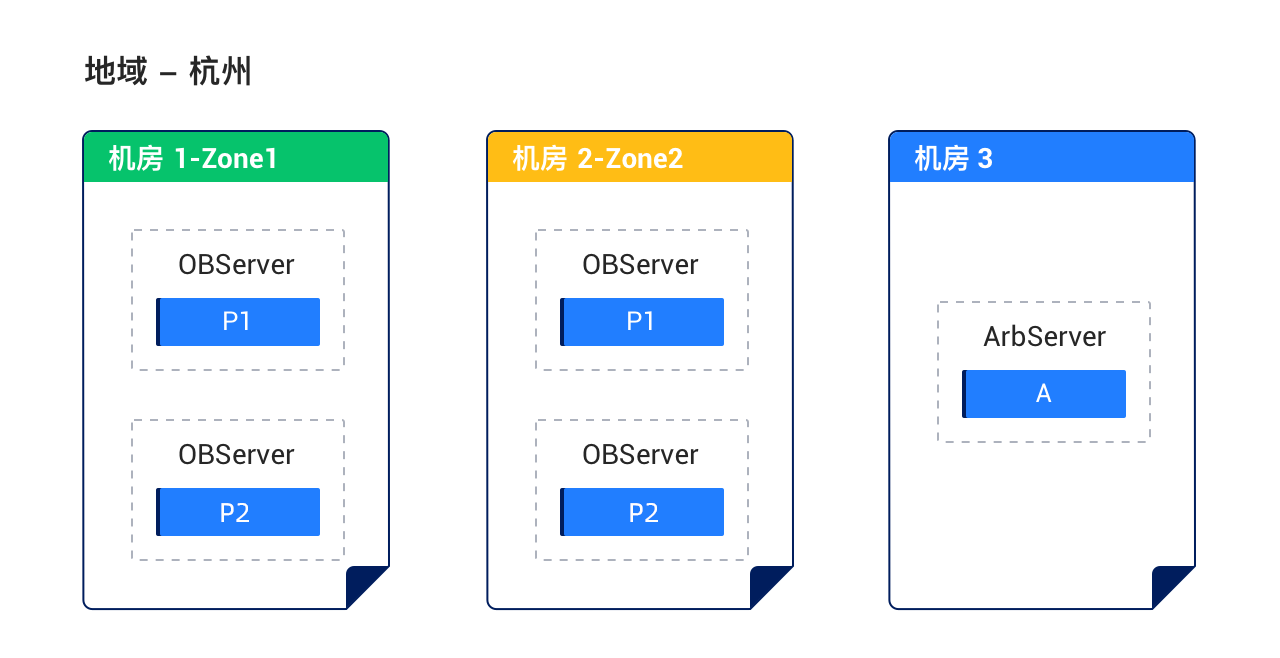
Solution 5: Deploy the arbitration service across three IDCs in one region
Characteristics:
- The three IDCs form one cluster. The network latency between IDCs ranges from 0.5 to 2 ms. Two IDCs each host a full-featured replica and are deployed as two zones. The arbitration service is deployed in the third IDC to reduce costs (without synchronizing logs).
- After a disaster in one IDC, the replicas in the remaining IDCs can compete for the majority through arbitration to ensure the RPO=0 requirement.
- The solution cannot protect against disasters at the region level.
For more information about the arbitration service, see Overview.
Deployment diagram:
Solution 6: Deploy the arbitration service across five IDCs in three regions
Characteristics:
- The five IDCs across three regions are deployed as one cluster. IDCs 1 and 2 are located close to each other and host full-featured replicas. IDC3 hosts the arbitration service to reduce costs (without synchronizing logs).
- After the failure of any IDC, the remaining full-featured replicas can still ensure the majority (3/4) to meet the RPO=0 requirement.
- After the failures of any two IDCs or regions, the arbitration service can help restore the business through arbitration degradation (downgrading the two failed replicas to learner status). The RPO can still be guaranteed.
- More than three replicas are required to ensure the majority. Therefore, to reduce the network latency of synchronizing redo logs, IDCs 1 and 2 should be located as close as possible.
Deployment diagram:

Solution 7: Deploy the arbitration service across two IDCs in one region
Characteristics:
- The primary region has two IDCs, each of which contains two zones for deploying full-featured replicas.
- The standby region has one IDC for deploying the arbitration service, which can reduce deployment costs and cross-region bandwidth overheads.
- If an IDC in the primary region fails, at most two replicas are lost. In this case, the remaining replicas might not form a majority (2/4). The arbitration service can trigger a downgrade and restore services. This solution ensures RPO=0.
- A disaster in the primary region cannot be addressed, but a disaster in the standby region does not have any impact.
The deployment diagram is as follows: