

















CloudCanal is a data migration and synchronization tool that helps enterprises build high-quality data channels quickly. It is available in SaaS and private deployment modes. The development team, consisting of core members from big enterprises, has built database kernels, large-scale distributed systems, and cloud products. They understand databases, distributed systems, and cloud product business and services.
This topic describes how to use CloudCanal Community Edition v2.2.6.9 to migrate data from a MySQL OceanBase database to a MySQL database.
Applicability
- CloudCanal Community Edition supports migrating data from a MySQL OceanBase database to a MySQL database as of version 2.2.3.0. For more information, see 2.2.3.0.
- CloudCanal supports OceanBase Database V3.2.3.0 and earlier as the source database.
Prerequisites
You have installed and deployed CloudCanal Community Edition. For more information, see Get started (Linux/MacOS).
You have installed and deployed OceanBase Binlog Service. For more information, see Create a Binlog cluster.
Procedure
- Add a data source.
- Create a task.
- View the task.
Add data sources
Log in to the CloudCanal console.

Go to the data source management page and click Add Data Source.

On the Add Data Source page, specify the data source information.
Deployment Type: indicates whether the data source is a Self-managed database or an Alibaba Cloud database.
- Alibaba Cloud: the database instance that you have purchased on Alibaba Cloud.
- Self-managed database: the database instance that you have deployed.
Database Type: the type of the data source.
Two data sources, OceanBase and MySQL, are added:
Choose OceanBase from the self-managed database option to add the OceanBase database instance that you have deployed.
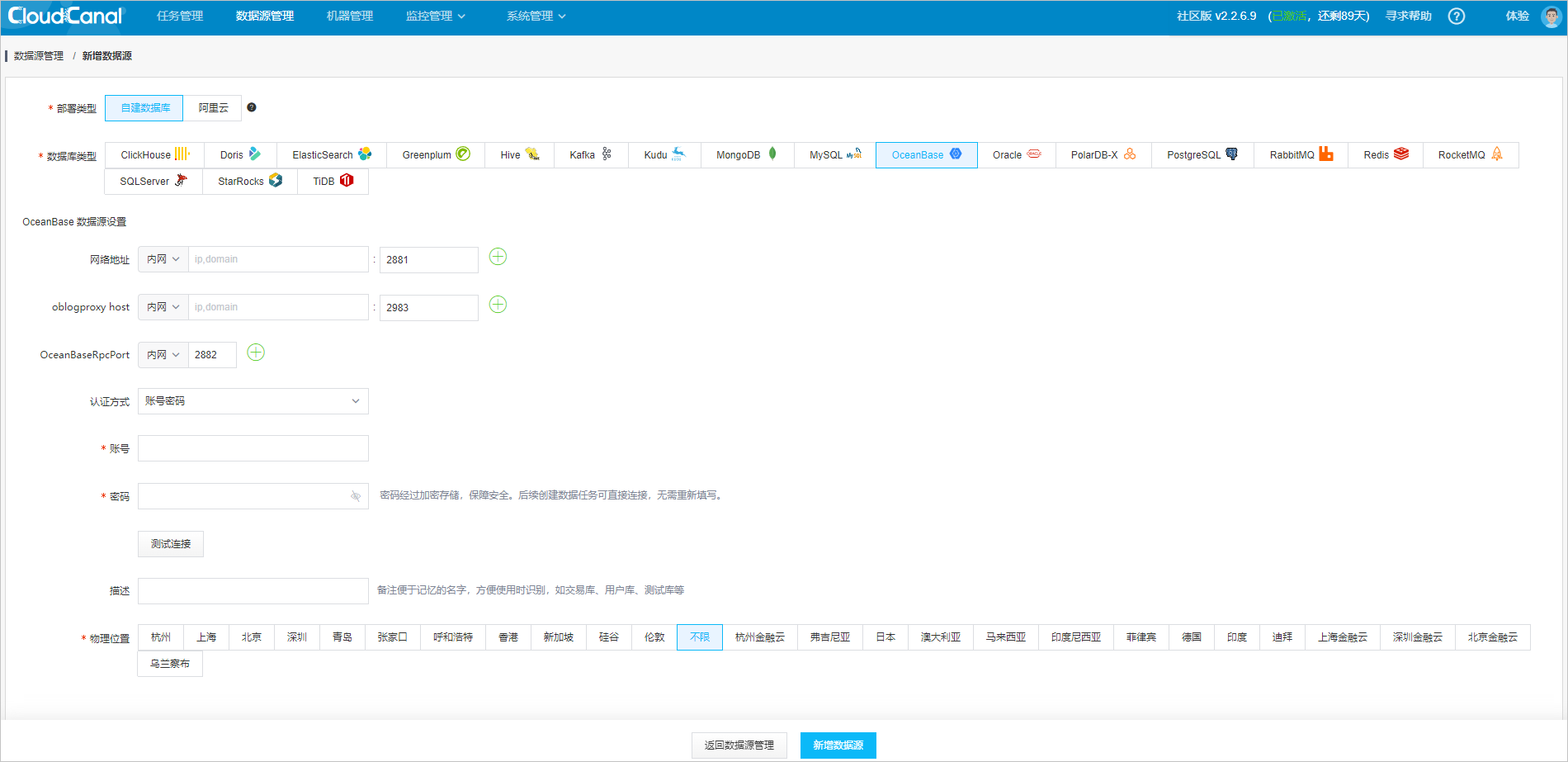
Configure the OceanBase data source:
- Network Address: the IP address for connecting to OceanBase Database, which can be a direct connection or an ODP connection.
- oblogproxy host: the IP address of the OceanBase Binlog service. If you use OceanBase Database as the source for incremental synchronization, this parameter is required. If you use OceanBase Database as the target, this parameter can be left empty. For more information about the OceanBase Binlog service, see OceanBase Binlog service.
- OceanBaseRpcPort: the OceanBase RPC port. The default value is 2882.
- Authentication: the authentication mode. It can be No Password, With Password, or Username/Password. The default value is Username/Password.
- Username: the username for connecting to OceanBase Database. In direct connection, the username format is username@tenant name; in ODP connection, the username format is username@tenant name#cluster name.
- Password: the password corresponding to the username.
- Description: the description of the data source. This parameter is optional. It is used to remark a name for easy identification when used, such as trade database, user database, test database.
Choose MySQL from the self-managed database option to add the MySQL database instance that you have deployed.
Configure the MySQL data source:
- Network Address: the IP address of the MySQL database.
- Authentication: the authentication mode. It can be No Password, With Password, or Username/Password. The default value is Username/Password.
- Username: the username for connecting to the MySQL database.
- Password: the password corresponding to the username.
- Description: the description of the data source. This parameter is optional. It is used to remark a name for easy identification when used, such as trade database, user database, test database.

View the added data sources.

Create a task
After the data source is added, perform full data migration, incremental synchronization, or schema migration by following these steps.
Go to the Task Management page and click Create Task.

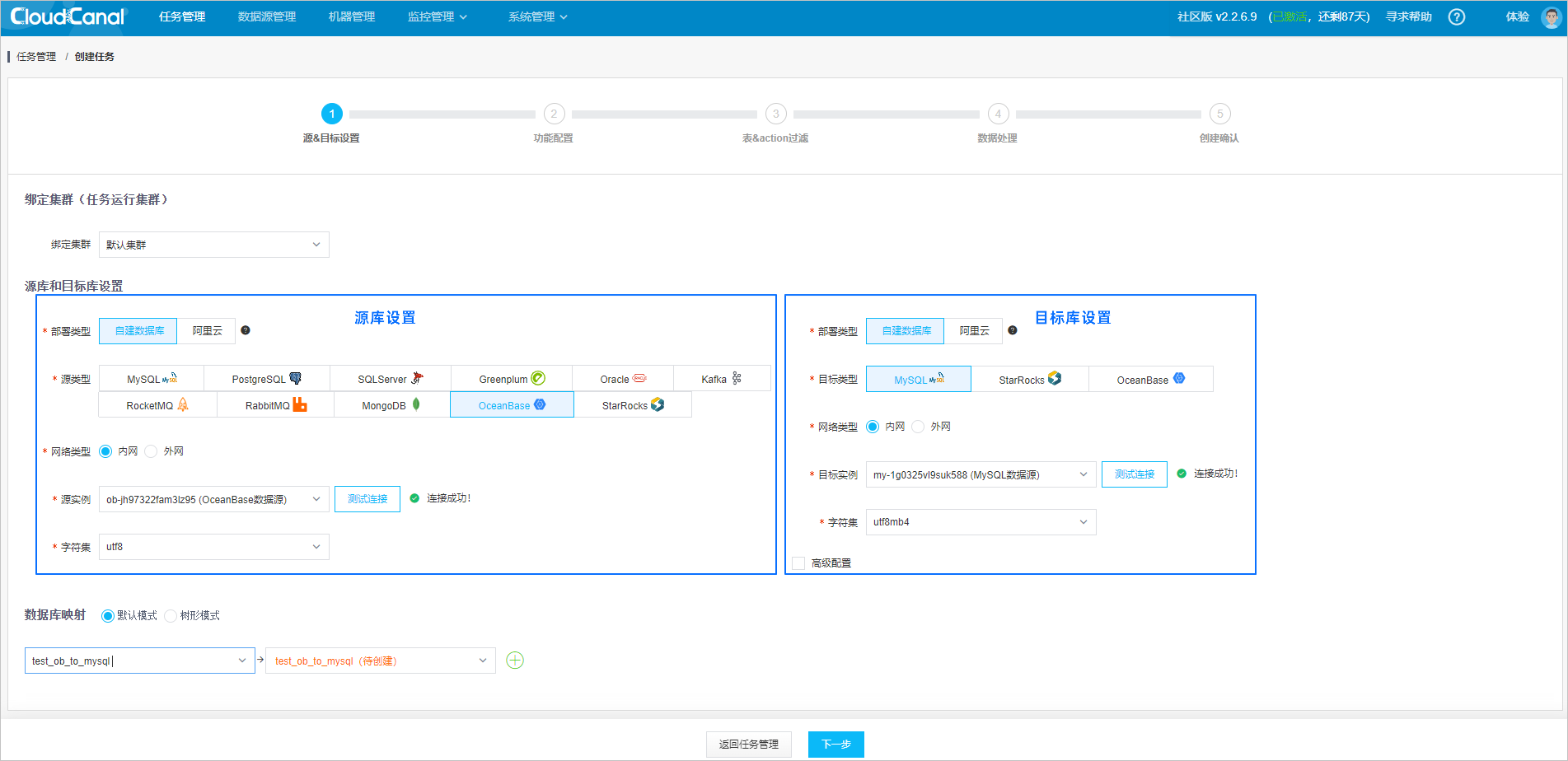
Configure the source and target databases.
Select Task Run Cluster. The task will be scheduled to run on a server in the cluster. After the Community Edition is deployed, a default run cluster will be provided.
Select OceanBase as the source database and MySQL as the target database, and click Test Connection.
Select the databases for migration, synchronization, or verification and configure the database mappings.
Click Next.
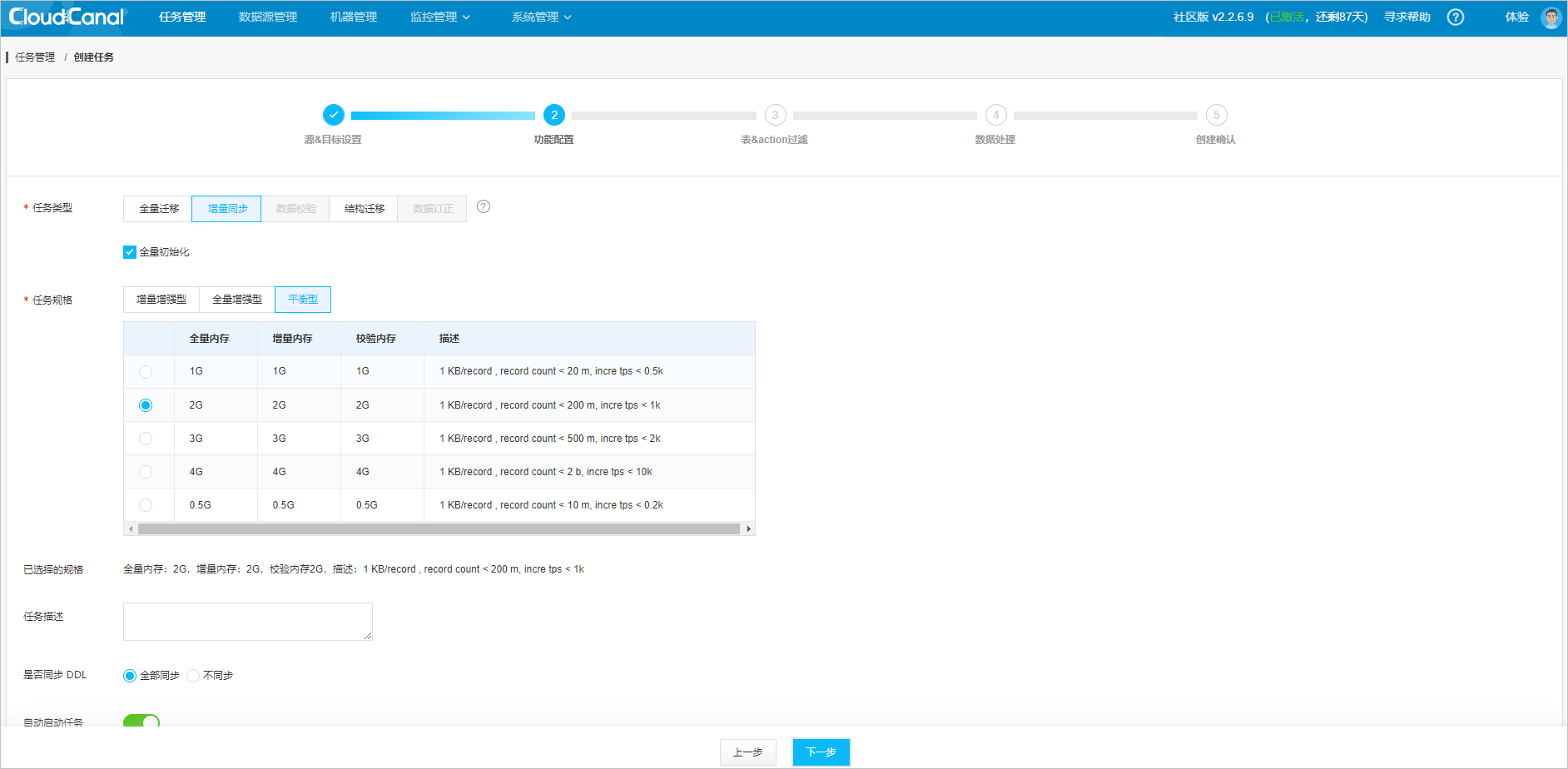
Configure the task.
Select the Incremental Synchronization feature. The system will first perform full synchronization by querying tables, and then perform incremental synchronization by consuming binlog.
The task types and their features are as follows:
- Full migration: Primarily for data migration and suitable for full data relocation and short-term incremental synchronization.
- Incremental synchronization: The default option. It includes full initialization by default. Primarily for data synchronization and suitable for long-term incremental synchronization.
- Data verification: Verifies the accuracy of data migration by comparing the data in the source and target databases. It can verify the data accuracy one time or multiple times at scheduled intervals. The Community Edition does not support this feature.
- Schema migration: Automatically creates corresponding databases and tables based on the selected databases and tables.
- Data correction: Verifies the data in the source and target databases. Automatically covers inconsistent data with the data in the source database. The Community Edition does not support this feature.
The default task specification is sufficient for most scenarios. You can modify the task specification if needed.
After the configuration is completed, click Next.
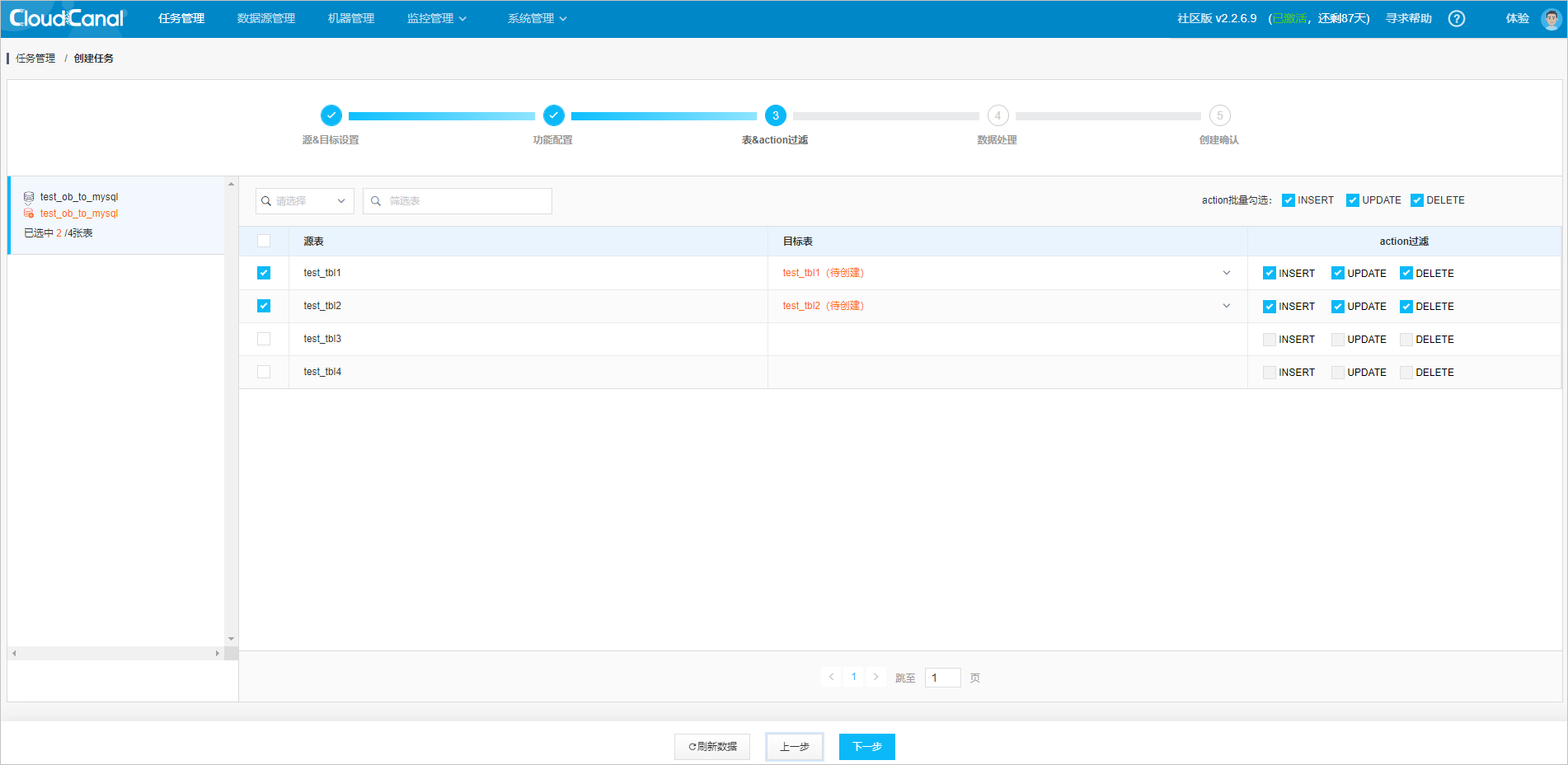
Filter tables and actions.
Select the tables to synchronize. To ensure consistency between the
UPDATEandDELETEoperations in the target database and those in the source database, the source database table must have a primary key or unique constraint.After the configuration is completed, click Next.
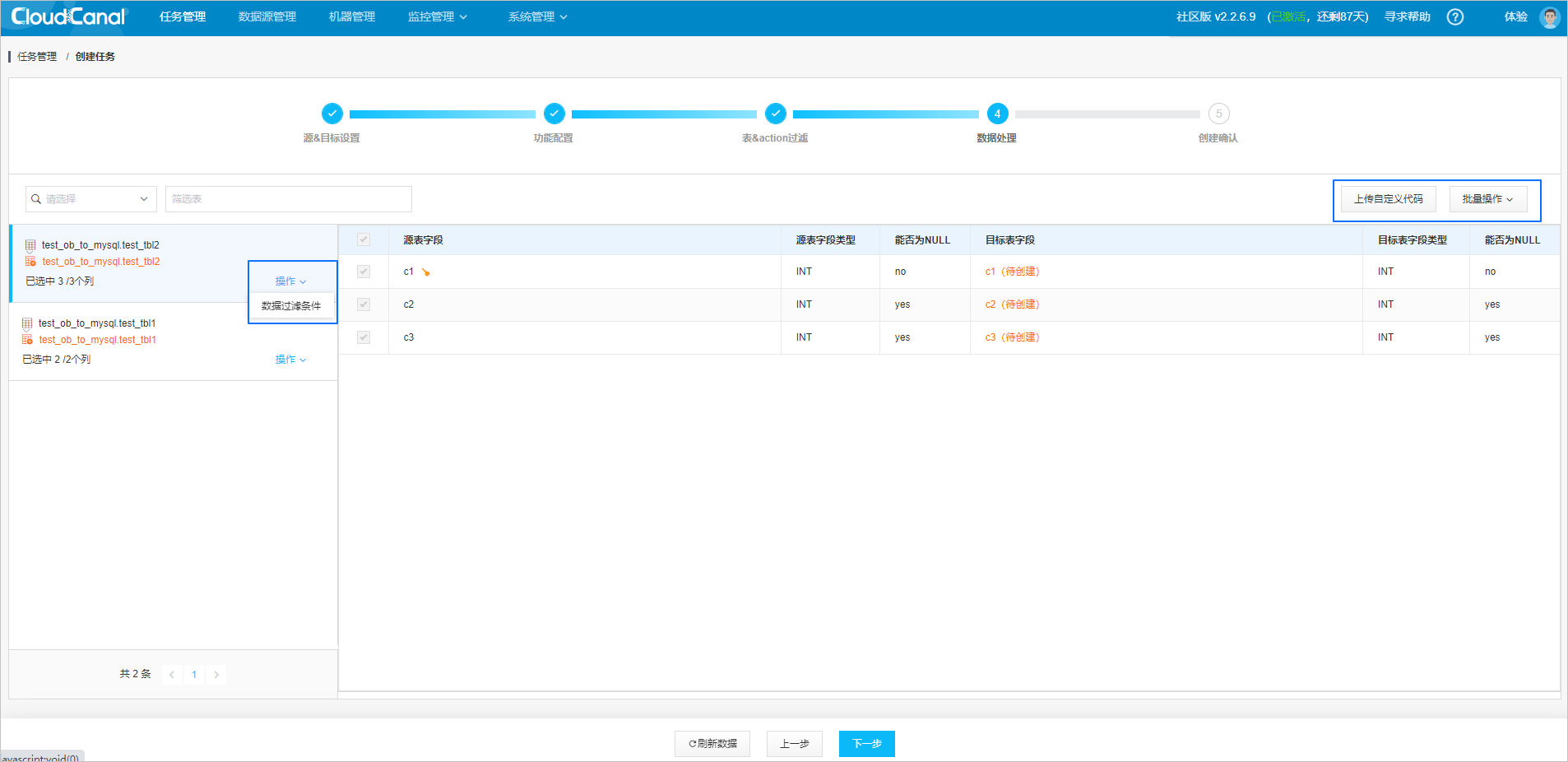
Process data.
You can add data filtering conditions, upload custom code, and perform batch operations.
- Data filtering conditions: Add data filtering conditions on the left side of the data processing page in the Actions column of the corresponding table.
- Upload custom code: Custom code allows you to process data rows in real time using Java. After you upload the code to CloudCanal, the code will take effect on all full and incremental synchronization tasks. Then the data will be sent to the destination data source.
- Batch operations: You can add data filtering conditions in batches and trim columns in batches.
After the configuration is completed, click Next.
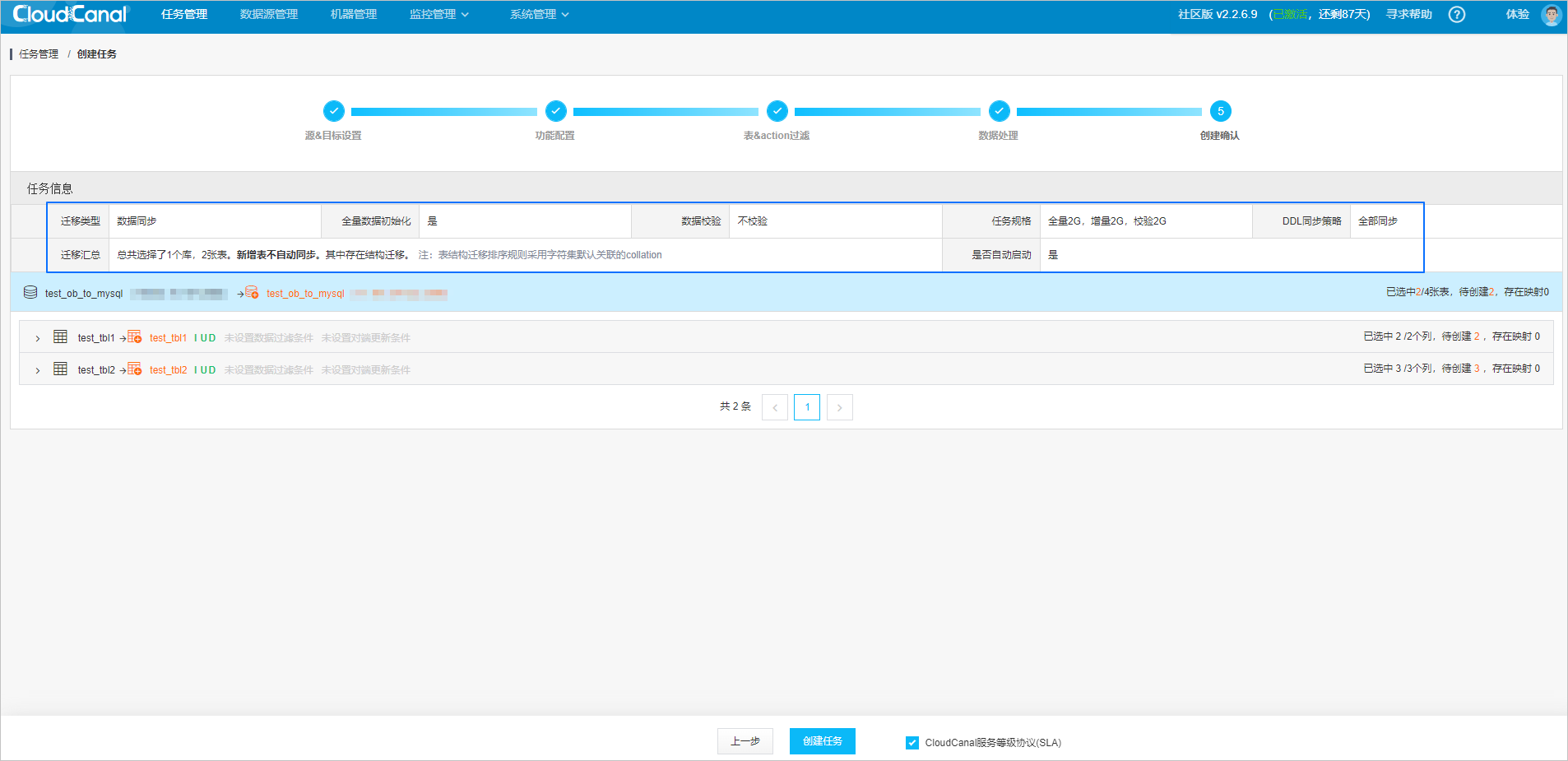
Verify the task configuration.
After you verify that the configuration is correct, click Create Task.
View the task status
After an incremental synchronization task is created, it will default perform Schema Migration, Full Data Migration, and Incremental Synchronization.
Go to the CloudCanal task management console and click Refresh in the upper-right corner to view the real-time status of the task.

References
For more information about CloudCanal, see CloudCanal documentation.