

















OceanBase Database uses multiversion two-phase locking to ensure the correctness of its concurrency control model. The lock mechanism is important for ensuring data concurrency and consistency.
The lock mechanism of OceanBase Database provides locks at the granularity of data behaviors. Modifications of different columns in the same row are mutually exclusive on the same lock. However, modifications of different rows are controlled by different locks and therefore are independent of each other. Similar to other databases that use multi-version two-phase locking, OceanBase Database does not apply locks to reads. This prevents mutual exclusion between reads and writes, which improves the concurrency of read and write transactions. Locks can be stored in rows, memory, or disks. If locks are stored in rows, OceanBase Database does not need to maintain the data structures of a large number of locks in the memory. In addition, OceanBase Database maintains waiting relationships between locks in the memory. Therefore, when a lock is released, other transactions that wait on the lock are woken up.
Notice
The
SELECT ... FOR UPDATEstatement cannot prevent mutual exclusion between reads and writes.During the commit of a transaction, mutual exclusion temporarily occurs between reads and writes to maintain a consistent snapshot of the transaction. This is called lock for read.
Use locks
This section describes how to use row locks in OceanBase Database. The following sample SQL statement shows how to update the information about a product:
Note
The following SQL is for demonstration purposes only and cannot be executed temporarily.
UPDATE GOODS
SET PRICE = ?, AMOUNT = ?
WHERE GOOD_ID = ?
AND LOCATION = ?;
The preceding SQL statement is used to update the price and inventory of a product based on the specified product ID and location. The SQL statement corresponds to an SQL statement in a transaction. Before the transaction ends, the row that contains the product ID and location is locked, and all concurrent updates are blocked and suspended. In this way, concurrent modifications do not cause dirty writes. A lock is implicitly added to the modified data row when you update the data. The lock mechanism of OceanBase Database allows you to control concurrent operations without the need to explicitly specify the lock range.
However, OceanBase Database allows you to explicitly specify the use of the lock. The following SQL statement shows how to query the information about a product in a mutually exclusive manner:
Note
The following SQL is for demonstration purposes only and cannot be executed temporarily.
SELECT PRICE, AMOUNT
FROM GOODS
WHERE GOOD_ID = ?
AND LOCATION = ?
FOR UPDATE;
The preceding SQL statement is used to query the price and inventory of a product based on the specified product ID and location. The SQL statement corresponds to an SQL statement in a transaction. Before the transaction ends, the data row that contains the product ID and location is locked, and all concurrent updates are blocked and suspended. In this way, a lock is explicitly added. This plays an important role in different business scenarios.
Granularity of locks
OceanBase Database supports both table locks and row locks, and row locks are mutually exclusive.
Table locks are primarily used to implement more complex DDL operations. They are intended to prevent concurrent access to the entire database table during the operation to ensure the atomicity and consistency of transactions. Table locks have a larger granularity, therefore they can lock more objects than row locks, but they also reduce concurrency because all other operations attempting to access the table will be blocked until the table lock is released. Table locks are usually used in scenarios where the locking level cannot be finely divided (such as row locks or page locks), or when it is known that the upcoming operations will affect a large part of the data in the table. These locks are typically used for DDL operations, such as creating or modifying the structure of a table.
In terms of transaction processing, when different columns of the same row are updated, different transactions will block each other because OceanBase Database uses row locks, a measure taken to reduce the storage overhead of lock data structures on rows. However, when updating data in different rows, transactions do not interfere with each other, allowing concurrent execution of transactions.
Mutual exclusion of locks
OceanBase Database uses multi-version two-phase locking. When a transaction is used to modify data, the system generates a new version of data instead of modifying the original data. Therefore, you can read data of an earlier version from a consistent snapshot. In this way, OceanBase Database can control concurrent operations without row locks and prevent mutual exclusion between reads and writes. This greatly improves the concurrent level of OceanBase Database. However, the SELECT ... FOR UPDATE statement still adds a row lock during execution and is mutually exclusive with other update statements or SELECT ... FOR UPDATE statements. An update operation, on the other hand, is mutually exclusive with all operations that require a row lock.
Storage of locks
OceanBase Database stores locks in rows. This reduces the maintenance overheads of lock data structures in the memory. In the memory, when a transaction obtains a row lock, a transaction label is added to the corresponding row to indicate that the transaction is the row lock holder. When a transaction attempts to obtain the row lock, the transaction checks whether it is the row lock holder based on the transaction label. If no, the transaction waits for the row lock to be released. If yes, the transaction can access the row. After the transaction releases the row lock, the transaction label is removed from the corresponding row. In this case, other transactions can attempt to obtain the row lock.
After data is dumped to an SSTable, the corresponding transaction label is recorded in the data within the macroblock. Other transactions still need to determine whether they are allowed to access the corresponding data based on the transaction label. However, the transaction label in the data within the macroblock cannot be cleared immediately after the transaction releases the row lock because SSTables are immutable. This is what distinguishes the lock mechanism of OceanBase Database from the lock mechanism in the memory. You can still refer to corresponding transaction information based on the transaction label and check whether the transaction has released the row lock.
Release of locks
Like most cases of two-phase locking, locks in OceanBase Database are released when the corresponding transactions end (committed or rolled back), which prevents data inconsistency. In OceanBase Database, transactions can also release row locks at savepoints. When you roll back a transaction to a savepoint, the transaction releases all row locks added at and after the savepoint based on the mechanism described in the Mutual exclusion of the lock section.
Wake-up of locks
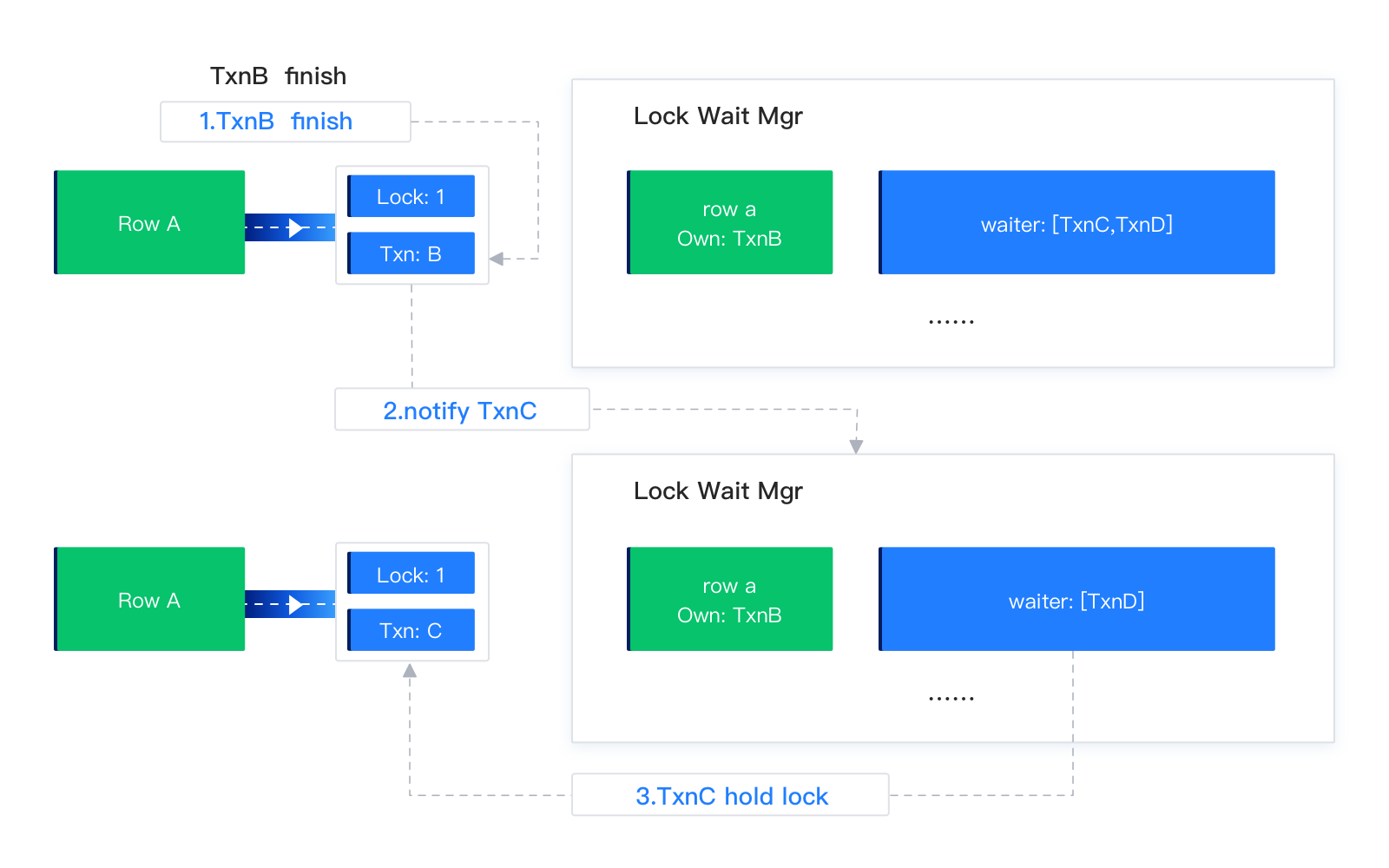
To wake up transactions, OceanBase Database maintains waiting relationships between rows and transactions in the memory when mutual exclusion occurs between transactions. As shown in the following figure, Row A is locked by Transaction B, and Transaction C and Transaction D are waiting for Row A. OceanBase Database maintains the waiting relationship so that Transaction C and Transaction D can be woken up when the row lock is released. After Transaction B releases Row A, Transaction C is woken up. Then, Transaction C wakes up Transaction D.
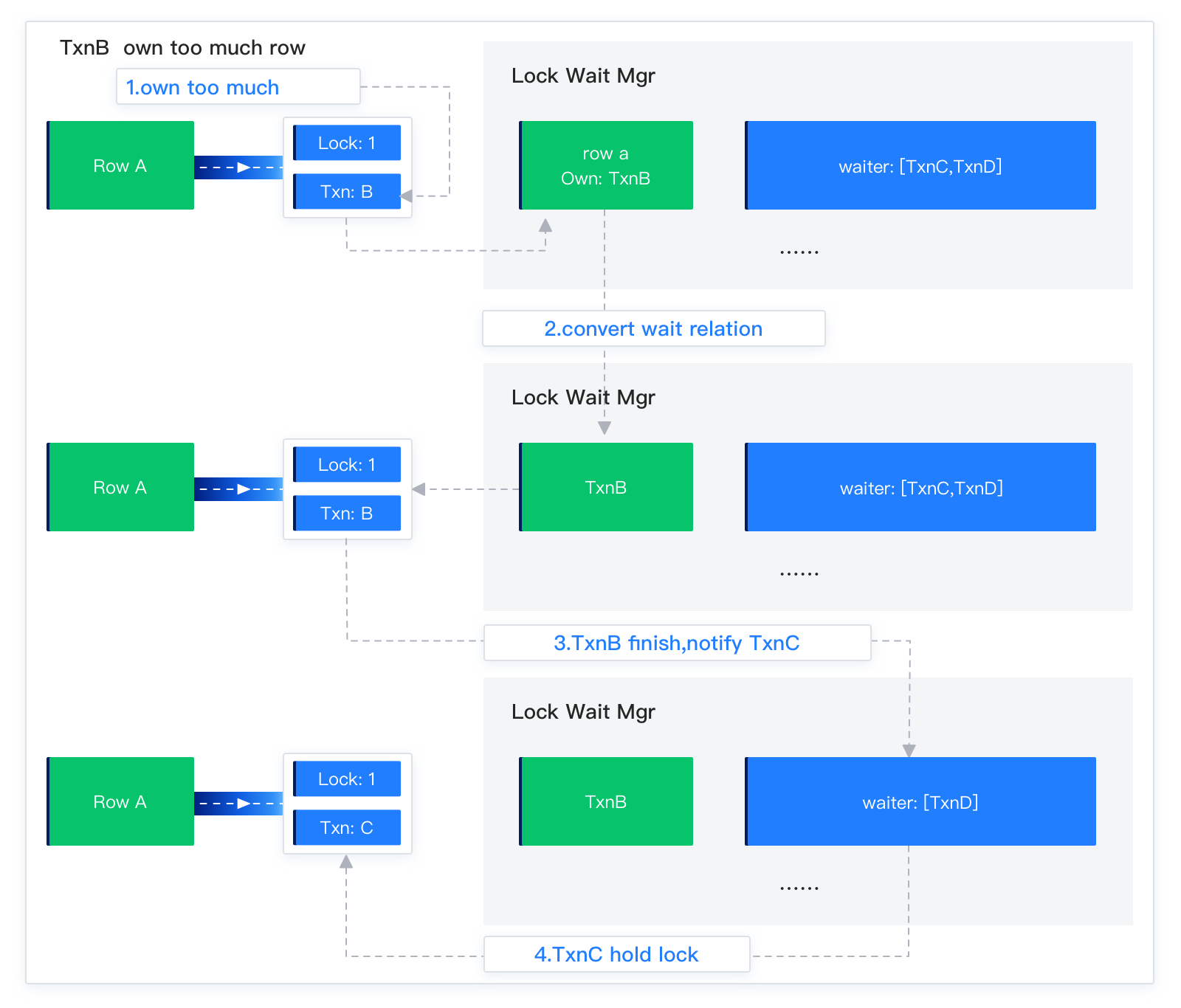
In addition to waiting relationships between rows and transactions, OceanBase Database may maintain waiting relationships between transactions. To reduce memory usage, OceanBase Database can convert waiting relationships between rows and transactions into waiting relationships between transactions. As shown in the following figure, Row A is locked by Transaction B, and Transaction C and Transaction D are waiting for Row A. This waiting relationship is converted into a relationship in which Transaction C and Transaction D wait for Transaction B. After Transaction B ends, both Transaction C and Transaction D are woken up because the lock waiting relationship between rows is unknown.
Deadlocks
The implementation of the lock mechanism results in deadlocks. A deadlock occurs if there is a circular dependency between resources. Assume that both Transaction A and Transaction B attempt to obtain Resource C and Resource D. Transaction A has obtained Resource C and then attempts to obtain Resource D, and Transaction B has obtained Resource D and then attempts to obtain Resource C. This situation is a deadlock. In this case, if no transaction is willing to give up the resource that it has obtained, none of the transactions can end as expected.
Timeout-based solution to deadlocks
OceanBase Database earlier than V3.2 do not support active deadlock detection. Therefore, OceanBase Database relies on timeout rollback mechanisms to resolve deadlocks in business logic.
OceanBase Database supports the following timeout mechanisms:
Lock timeout mechanism: This mechanism is implemented by using the
ob_trx_lock_timeoutparameter. By default, the parameter specifies the statement timeout period. If the lock waiting time exceeds the lock timeout period, the system rolls back the corresponding statement and returns an error code. In this case, a circular dependency between resources no longer exists and the deadlock is resolved. For example, if a timeout error occurs when Transaction B attempts to obtain Resource C, Transaction A can obtain Resource D after Transaction B ends.Statement timeout mechanism: This mechanism is implemented by using the
ob_query_timeoutparameter. The default value is10, in seconds. If the lock waiting time exceeds the statement timeout period, the system rolls back the corresponding statement and returns an error code. In this case, a circular dependency between resources no longer exists and the deadlock is resolved. For example, if a timeout error occurs when Transaction B attempts to obtain Resource C, Transaction A can obtain Resource D after Transaction B ends.Transaction timeout mechanism: This mechanism is implemented by using the
ob_trx_timeoutparameter. The default value is86400, in seconds. If the transaction waiting time exceeds the transaction timeout period, the system rolls back the corresponding transaction and returns an error code. In this case, a circular dependency between resources no longer exists and the deadlock is resolved. For example, if Transaction B ends due to a timeout, Transaction A can obtain Resource D.
Active deadlock detection
OceanBase Database V3.2 and later versions support active deadlock detection, in addition to timeout-based solutions to deadlocks.
OceanBase Database adopts a deadlock detection solution known as lock chain length (LCL) solution, which is a priority-based multi-outdegree distributed deadlock detection solution. The deadlock detection algorithm of OceanBase Database prevents false kills and overkills of transactions.
"Priority-based" means that the LCL deadlock detection solution tends to kill the transaction with the lowest priority among transactions involved in a deadlock to break the deadlock. In deadlock detection, the priorities of transactions are determined by their start times. A transaction that starts later has a lower priority.
"Multi-outdegree" means that each transaction can wait for more than one other transaction.
In distributed deadlock detection, each node that represents a transaction in deadlock detection recognizes only its own dependencies, and deadlocks between nodes can be detected without a global lock manager.
Implementation principle
To improve execution efficiency, a distributed transaction usually needs to access data of multiple partitions and may encounter multiple lock conflicts. In this case, to improve deadlock detection efficiency, a directed edge of a one-way dependency in which one transaction waits for multiple other transactions is described as multi-outdegree.
Common deadlock detection solutions adopt the path-pushing algorithm. This algorithm tends to cause false kills and overkills of transactions in multi-outdegree scenarios. The LCL deadlock detection solution adopts a specially designed edge-chasing algorithm. In the LCL deadlock detection solution, each node maintains two states, which are called a lock chain length value (LCLV) and a label. To prevent overkills of transactions, each node maintains only one label. Labels are compared with each other, and a larger one overwrites a smaller one. In this way, only the node with the largest label in a loop can detect a deadlock, which prevents overkills of transactions.
Deadlock detection based on the edge-chasing algorithm refers to the principle that the label sent by a node can return to the node. However, if you use a single label in a multi-outdegree scenario, the largest label in a deadlock loop may not belong to any node in the loop, and the deadlock cannot be detected. This is called out-of-loop pollution. To resolve this issue, the LCL deadlock detection solution introduces the concept of LCL. Each node maintains an LCLV. LCLVs of nodes in a loop can infinitely increase over time. However, LCLVs of nodes out of the loop and unreachable to nodes in the loop have upper limits. A node can accept a label only from another node with an equal or larger LCLV. This prevents out-of-loop pollution. In addition, the current label on a node is regularly cleared to eliminate out-of-loop pollution that has occurred in the early operation stage of the algorithm. In this way, the algorithm can operate in multi-outdegree scenarios as expected.
Implementation
When Transaction A fails to obtain data because of row lock, Transaction A obtains the ID of Transaction B that holds the row lock while waiting for the row lock to be released. In addition, Transaction A creates a deadlock detection node a (hereinafter referred to as Detector (a)) and records a one-way dependency on Detector (b) of Transaction B for Detector (a).
Each node maintains the following states:
When a detector is created, two labels are generated: a public label and a private label. The detector generates a globally unique label based on its priority (a node with a higher priority has a larger label) and uses it to initialize the two labels. The detector also generates an LCLV that is initially 0.
Each detector maintains a dependency list. The list records network locations of other nodes on which the detector depends.
Every 1.4s on the timeline is counted as an LCL period.
At the beginning of each LCL period, each node resets its public label to a private label.
The first 700 ms of an LCL period is called a lock chain length proliferating (LCLP) period. During this period, each node periodically sends the LCLV of its status to all downstream nodes in the dependency list. After receipt of an LCLV from an upstream node, each node updates its LCLV to max(LCLV, received LCLV + 1).
The last 700 ms of an LCL period is called a lock chain length spreading (LCLS) period. During this period, each node regularly sends the LCLV and public label of its status to all downstream nodes in the dependency list. After receiving an LCLV and a public label from an upstream node, each node updates its public label to min(public label, received public label) and its LCLV to the received LCLV if the received LCLV is no less than the current LCLV of the node.
Deadlock detected: If the public label received by a node is the same as its private label, the node has detected a deadlock.
View
The CDB_OB_DEADLOCK_EVENT_HISTORY view records all historical deadlock events, transactions involved in the deadlock events, and transactions killed in the deadlock events.