

















What is high availability of a system?
The high availability of an IT system refers to its capacity to provide services without interruptions. It represents the degree of availability of the system. High availability is the contribution of various phases in system design, engineering practices, and product functionality to ensure service continuity. The key to ensure high availability is to eliminate single point of failure (SPOF) and provide emergency recovery capability in the case of SPOF or a system failure. Enterprise-level applications usually demand high system availability to ensure service continuity. In other words, when a failure or disaster occurs, the recovery time objective (RTO) must be as short as possible and the recovery point objective (RPO) must be close to 0. High availability is a factor that must be considered in the design of a distributed system. OceanBase Database is a native distributed database that can provide consistent and highly available data services. The transaction consistency and storage persistence of OceanBase Database ensure that the same data and state can be recovered after the OBServer node exits and restarts. In addition, the backup and restore and primary/standby solutions further ensure the high availability of OceanBase Database.
Which capabilities of OceanBase Database ensure the high availability of data services?
Product capability and solution |
Failure scenario |
Principle |
|---|---|---|
| Distributed election | The minority of replicas in an OceanBase cluster fail due to various causes.
|
The election module of OceanBase Database ensures that a unique leader is elected to provide data services. Clogs are synchronized and persisted for the majority of replicas by using the Paxos protocol. When the minority of replicas in the Paxos group fail, the clogs on the majority of replicas can comprise a complete set of clogs to avoid data losses caused by hardware faults, thereby ensuring data reliability. When the minority of replicas in an OceanBase cluster fail, the system availability and database performance are not affected if the failed replica is not the leader. If the leader is contained in the minority of failed replicas, the OceanBase cluster will elect a unique new leader from the remaining replicas to provide data services. If the zones of OBServer nodes are distributed in different IDCs and regions, high availability can be ensured across IDCs or regions based on the distributed election of the OceanBase cluster and clog synchronization of the Paxos group. |
| Clogs and storage engine |
|
The storage engine of the OceanBase cluster stores the baseline data in SSTables and the incremental data in MemTables. In OceanBase Database, clogs are the redo logs of data. When a data modification request is initiated, the request will be forwarded to the OBServer node where the leader resides. This OBServer node updates the data modification request to the MemTable. After the transaction is committed, the leader updates the local clog and writes the clog to the followers by using the Paxos protocol. After the log is successfully written to the disks of the majority of replicas, the data is successfully modified. A response is returned to the client. The followers will replay the clog to the local MemTable to provide weak-consistency read services. When the size of the MemTable reaches the specified threshold, a freeze and a minor compaction are triggered to persist the data in the MemTable to an SSTable. At this time, the clog replay timestamp advances. This is similar to creating a checkpoint. When an OBServer node is restarted, it can restore the source data and update the latest data from the SSTable. Then, the OBServer node obtains the clog replay timestamp from the partition metadata and starts replaying clogs to the MemTable. After that, the OceanBase cluster can restore the persisted data on the disk to the state before the failure. This ensures data integrity. When an OceanBase cluster is restarted upon a failure (such as a software exit, abnormal restart, power failure, or hardware fault) or as scheduled for maintenance, the logs and data in the store directory on OBServer nodes in the cluster are restored to the memory and the observer process is restored to the state before the failure. If the OceanBase cluster needs to be restarted because the majority of replicas in the cluster fail, data services are interrupted. After the majority of replicas are restarted, data can be restored to the state before the failure. Optimization measures are taken for the scenario where the majority of replicas are restarted upon a failure. The speed of restoring data to the MemTable is increased so that data services are resumed quickly. If the entire cluster is restarted, the latest clogs on the disk must be replayed to the MemTable to provide data services. When the data services of the OceanBase cluster resume, the data is restored to the state before the restart. |
| Backup and restore | When data is corrupted, an OBServer node fails, or the OceanBase cluster fails, the OceanBase cluster can restore from the backup baseline data and clogs. | When data is corrupted, an OBServer node fails, or the OceanBase cluster fails, the OceanBase cluster can restore from the backup baseline data and clogs. |
| Primary/Standby solution | IDC-level fault recovery or region-level disaster recovery:
|
The OceanBase cluster also supports the conventional primary/standby architecture. The multi-replica mechanism of OceanBase clusters provides rich disaster recovery capabilities. When a failure at the server, IDC, or region level occurs, an automatic failover is performed with no data loss. This achieves an RPO of 0. If the primary cluster becomes unavailable when a majority of replicas fail, the standby cluster takes over the services and provides lossless failover (RPO = 0) and lossy failover (RPO > 0). These two disaster recovery capabilities can minimize service downtime. OceanBase Database allows you to create, maintain, manage, and monitor one or more standby clusters. A standby cluster accommodates a hot backup for the production cluster, namely the primary cluster. The administrator can allocate intensive read-only business operations to standby clusters to improve system performance and resource utilization. |
What will happen if the minority of replicas in an OceanBase cluster fail? How long will it take for the replicas to restore?
The Paxos protocol ensures that a unique leader is elected to provide data services only when the majority of replicas in the OceanBase cluster reach a consensus. If the leader fails, a new leader can be elected from the remaining followers to take over the service as long as the majority of them reaches a consensus. The old leader cannot be elected as it is apparently not a member of the majority. When the leader fails, the time taken by the followers to detect the failure and elect a new leader determines the RTO.
The election model of OceanBase Database is a clock-dependent election solution. The multiple full-featured replicas (and log-only replicas) in the same partition perform pre-voting, voting, and vote counting and broadcasting within an election cycle to determine the unique leader. After a leader is elected, each replica signs a lease to affirm the leader. Before the lease expires, the leader will constantly initiate a re-election to renew its lease and will succeed in general cases. If the leader fails to renew its lease, after the lease expires, an election without a leader is periodically initiated to ensure the high availability of replicas. In an OceanBase cluster with three full-featured replicas, when one replica fails due to a fault or removal of an OBServer node, the election module of OceanBase Database ensures that if the original leader succeeds in the re-election, it can continue to provide data services; if the original leader fails the re-election, an election without a leader is initiated and a new leader is elected and takes over the services within 30s.
In OceanBase Database, clogs are synchronized and persisted for the majority of replicas by using the Paxos protocol. When the minority of replicas in the Paxos group fail, the remaining majority of replicas have the latest clogs to avoid data losses caused by hardware faults, thereby ensuring data reliability.
How is split brain avoided in elections in OceanBase Database?
In a high availability solution, if two replicas fail to learn the status of each other due to network issues and each of them considers itself as the leader to provide data services, a typical split-brain issue occurs. This will cause system disorder and data corruption. OceanBase Database uses the Paxos protocol to ensure data reliability and leader uniqueness. Specifically, a leader is elected only when the majority of replicas reach a consensus. If the leader fails, a new leader can be elected from the remaining followers to take over the service as long as the majority of them reaches a consensus. The old leader cannot be elected as it is apparently not a member of the majority.
The distributed election mechanism of OceanBase Database has obvious advantages in terms of high availability. This mechanism ensures that only one leader exists at any time. This completely avoids the split-brain issue. As split-brain is no longer a concern, followers can automatically trigger the election of a new leader to replace the current leader that fails. The process is performed without user intervention. This thoroughly resolves the issue and significantly shortens the RTO by using automatic re-election. The RTO is affected by another important factor. When the leader fails, the time taken by the followers to detect the failure and elect a new leader determines the RTO.
When the majority of replicas in an OceanBase cluster fail, can the OceanBase cluster continue providing services?
When the majority of replicas in an OceanBase cluster fail, the corresponding partitions cannot provide data services. To ensure high data availability, you must consider and optimize the interval between consecutive faults of the two replicas that are not related to each other when you design and maintain the overall system architecture. This aims to ensure that the mean time to failure (MTTF) is far shorter than the mean time to repair (MTTR) to ensure the high availability of data services. When the majority of replicas in an OceanBase cluster fail, promptly take emergency measures to quickly recover the cluster provided that the information and logs required for troubleshooting are retained.
How does the auto re-replication feature work for an OceanBase cluster? Can this feature ensure that when an OBServer node fails the replicas of the corresponding partitions remain complete?
When an observer process is terminated abnormally, if the termination duration is less than server_permanent_offline_time, no action is taken and the number of replicas for some partitions is only 2 (given a three-replica cluster). If the termination duration exceeds server_permanent_offline_time, this OBServer node is permanently removed and the OceanBase cluster will allocate units on other OBServer nodes with sufficient resources in the same zone to keep the required number of replicas. If resources are sufficient, unit migration is initiated.
Does an OceanBase cluster support multi-IDC and multi-region deployment? What are the requirements on the infrastructure? How do I select a deployment solution?
When you build an OceanBase cluster, you can distribute the replicas to multiple IDCs and regions to build a Paxos group across IDCs or regions. The multi-IDC and multi-region architecture provides disaster recovery in the IDC or even region level. Technically, if the infrastructure for the replicas of the OceanBase cluster is good enough and replicas are reasonably distributed, the OceanBase cluster can distribute data on different OBServer nodes to provide data services. Generally, to choose the multi-IDC and multi-region deployment solution, you need to consider the architecture requirements of the business systems and other aspects. The multi-IDC and multi-region deployment solution will bring a drastic increase in the overall system cost in scenarios such as private line deployment across regions. Therefore, you must choose a deployment solution from multiple dimensions such as costs, requirements, product capabilities, and solution feasibility.
Technically, the following deployment solutions support IDC- or regional disaster recovery.
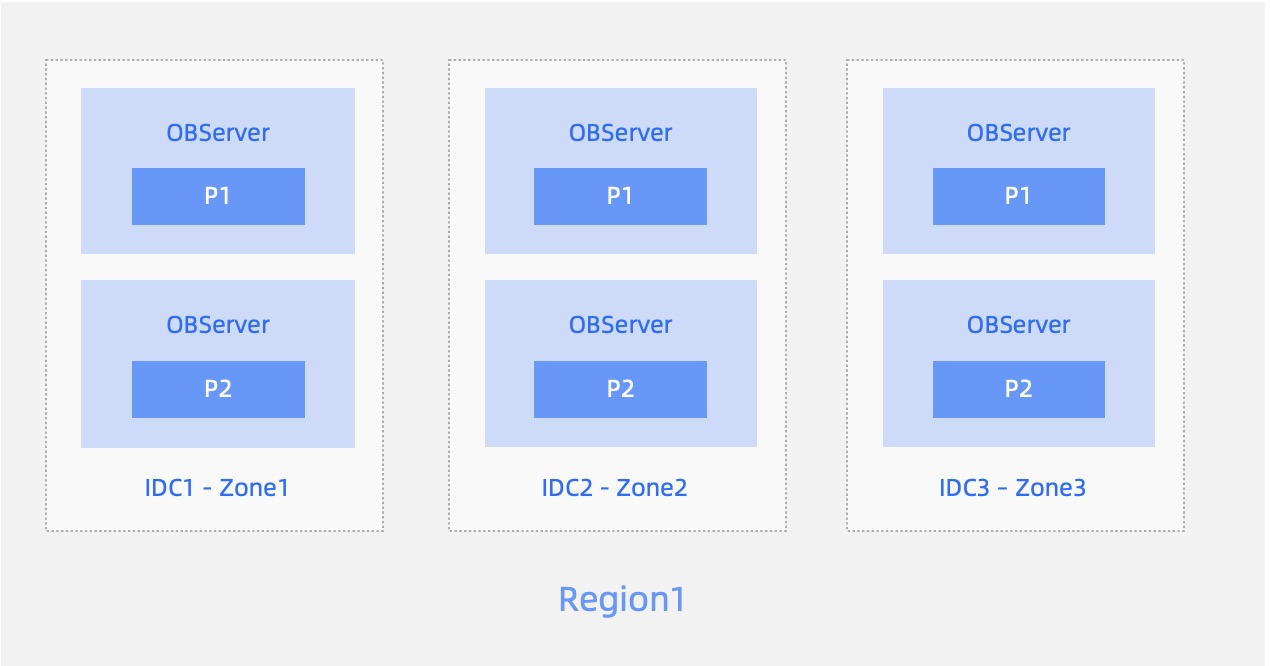
Three replicas in three IDCs of the same region
- Three IDCs in the same region form a cluster with three replicas. Each IDC is a zone, with network latency ranging from 0.5 ms to 2 ms.
- When an IDC fails, the remaining two replicas are still in the majority. They can enable redo log synchronization and guarantee an RPO of zero.
- This deployment solution cannot cope with region-wide disasters.
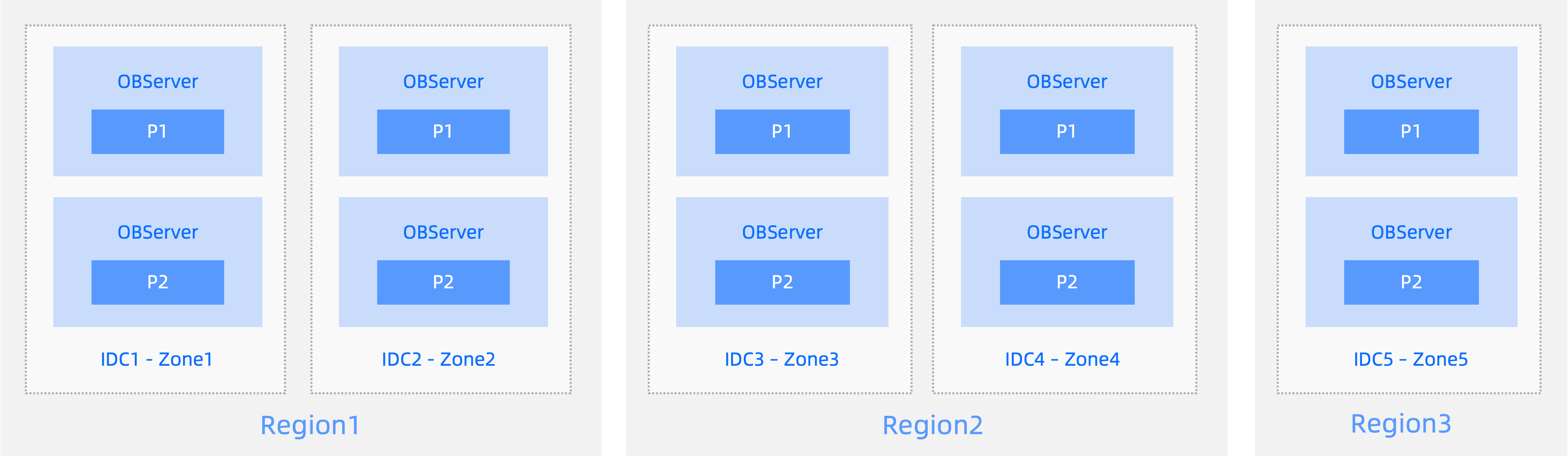
Five replicas in five IDCs across three cities
- Five IDCs across three regions form a cluster with five replicas.
- In the case of an IDC or region-wide failure, the remaining replicas are still in the majority and can guarantee an RPO of zero.
- In this mode, the majority must contain at least three replicas. However, each region has at most two replicas. To reduce the latency for synchronizing redo logs, Region1 and Region2 must be close to each other.
- To reduce costs, you can deploy only log replicas in Region3.
In actual deployment, solutions of two IDCs in the same region and three IDCs across two regions are customized based on customer requirements. The two solutions do address the needs for high system availability in some scenarios but also have weakness in terms of disaster recovery. They may be the choice for transition in initial deployment. The primary/standby architecture may also be used to enhance the disaster recovery capabilities. A deployment solution is worked out based on many factors and aspects. If you have any specific scenarios, contact technical architects of OceanBase Database.