

















OceanBase Database is a distributed database management system designed for enterprises. Empowered by an encompassing ecosystem, it can tackle complex business tasks with excellent transactional and analytical processing capabilities.
OceanBase Database has supported the stable and efficient operation of core business systems of customers in various industries, such as banking, insurance, transportation, and telecommunication.
OceanBase Database ranks first in running the TPC-C benchmark with a score of 707 million tpmC and ranks second in running the TPC-H benchmark with a result of 15 million QphH@30,000 GB.
Developed from scratch, OceanBase Database combines the high scalability of a distributed system and the high efficiency of a centralized system into an integrated architecture that supports hybrid transactional and analytical processing (HTAP). The architecture also provides the same level of atomicity, consistency, isolation, and durability (ACID) for transaction processing in both stand-alone and distributed deployment modes. OceanBase Database supports multi-replica synchronization based on the Paxos protocol to guarantee consistency among multiple data replicas and ensures database service availability by quickly performing replica switchover in the case of hardware failures. In addition, OceanBase Database is compatible with MySQL syntaxes. You can conveniently migrate your business systems from a MySQL database to an OceanBase database. Encoding-based compression algorithms are used to significantly reduce the required storage space.
Architecture
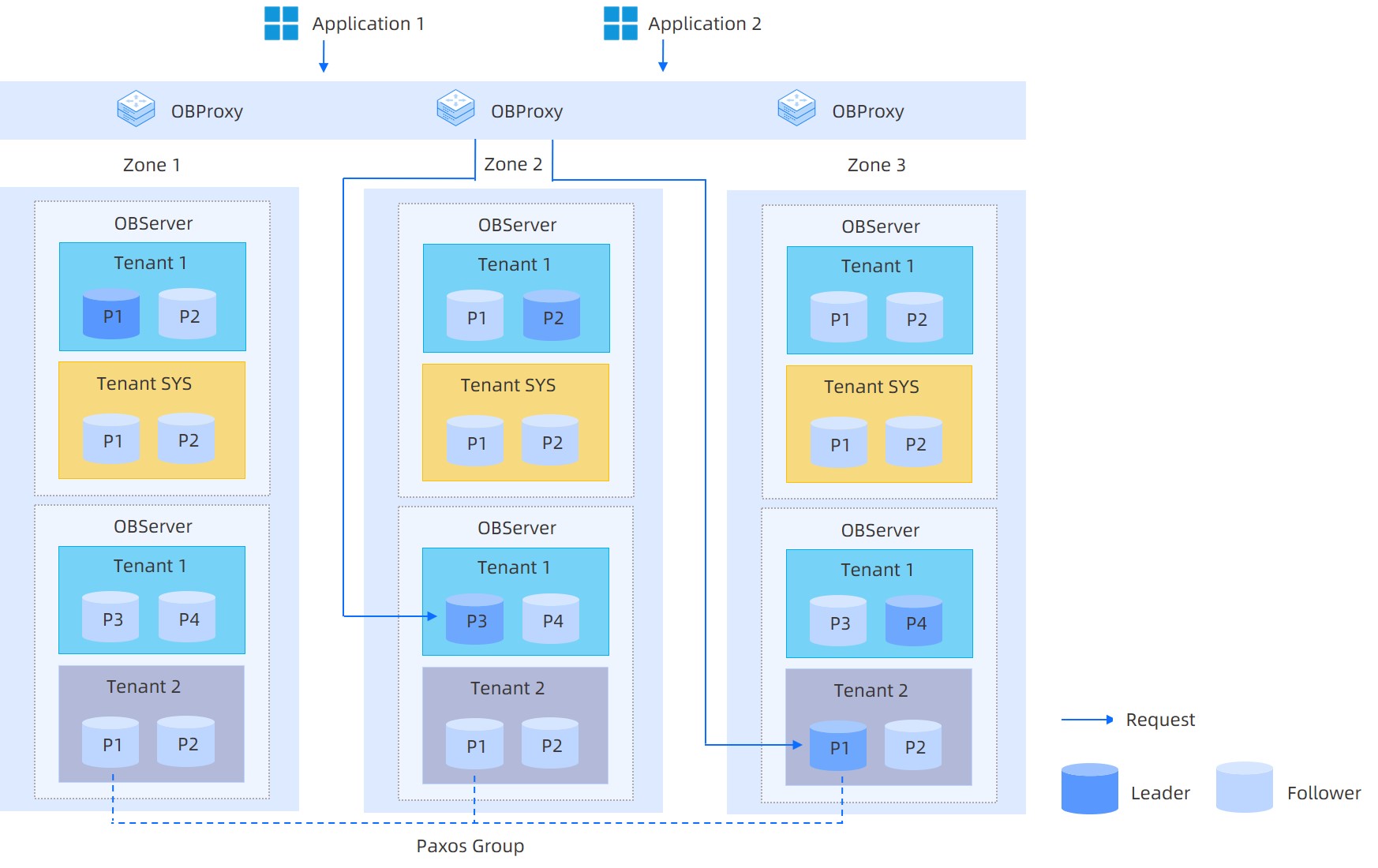
OceanBase Database can run on general server hardware and relies on local storage. Servers for distributed deployment are fully equivalent without special hardware requirements. The shared-nothing architecture of OceanBase Database allows the SQL execution engine to perform distributed execution in the database.
OceanBase Database runs an OBServer process, a single-process program, on each server to support the operation of database instances and stores data and redo logs of transactions in local files.
An OceanBase cluster is deployed across several zones and each zone consists of several servers. The term zone is a logical concept that represents a set of nodes with similar hardware availability in a cluster. It has different meanings in different deployment modes. For example, if a cluster is deployed in one IDC, nodes in a zone can belong to the same rack and the same switch. If a cluster is deployed across IDCs, each zone can correspond to one IDC.
User data can be stored in multiple replicas inside a distributed cluster for fault tolerance and for spreading read pressure. There is only one replica of data inside a zone, and different zones can store multiple replicas of the same data, and the consistency of data between replicas is guaranteed by a consensus protocol.
OceanBase Database supports the multi-tenant feature where each tenant is a separate database to the user and a tenant is able to set up a distributed deployment of tenants at the tenant level. CPU, memory and I/O are isolated between tenants.
The database instance of OceanBase consists of different components that cooperate with each other. These components are composed of storage layer, replication layer, transaction layer, SQL layer, and access layer from the bottom up.
Storage layer |
Stores the data of a table or a table partition. |
|---|---|
| Replication layer | Ensures data consistency between replicas of a partition based on consensus algorithms. |
| Transaction layer | Ensures the atomicity and isolation of the modifications to one or multiple partitions. |
| SQL layer | Translates user-initiated SQL queries into operations on the stored data. |
| Access layer | Forwards user queries to the appropriate OceanBase Database instances for processing. |
Storage layer
The storage layer provides data storage and access at the granularity of a table or a partition. A user-defined non-partitioned table can also be considered as a table that has one default partition. Partition is used as the granularity of storage operations below.
Data is stored in four layers in a partition. Data related to DML operations, such as insert, update, and delete, is first written into the MemTable. After the size of the MemTable reaches the specified threshold, its data is compacted into L0 SSTable on the disk. When the number of L0 SSTables reaches the specified threshold, the L0 SSTables are merged into one L1 SSTable. During the specified daily off-peak hours, the system performs a major compaction to merge all MemTables, L0 SSTables, and L1 SSTables into one major SSTable.
An SSTable consists of macroblocks with a fixed length of 2 MB, and each macroblock consists of microblocks of variable lengths.
During the major compaction, OceanBase Database uses the dictionary, run-length, constant, or differential encoding method to encode data of each microblock by column. After compression of data in each column, OceanBase Database performs inter-column equivalence encoding or inter-column substring encoding for multiple columns. The encoding can significantly compress the data, and the extracted in-column characteristic information can speed up subsequent queries.
After data is encoded, OceanBase Database performs lossless compression according to a user-specified general compression algorithm to further increase the data compression ratio.
Replication layer
The replication layer maintains a consensus algorithm for replicas of a partition and selects one of the replicas as the leader. Other replicas of the partition are followers. DML operations and strong consistency queries are performed only on the leader.
The replication layer unifies the write-ahead log of the database and the log required by the consensus algorithm to form a consensus between the replicas. The redo log is generated while a DML operation is written to the MemTable. The replication layer uses the self-developed Paxos protocol to persist the redo log on the local server and sends it to the followers of the partition over the network. The followers reply to the leader upon completing their persistence. After the leader confirms that the redo log is persisted on the majority of followers, it confirms the persistence of the redo log. Then, the followers replay the redo log in real time to keep their state consistent with that of the leader.
When a replica is elected as the leader, it gets a lease. A healthy leader keeps renewing the lease based on the election protocol during the lease period. The leader executes operations only when the lease is valid. The lease ensures the database capabilities to handle exceptions.
The replication layer automatically responds to server failures to guarantee the continuity of database services. When a fault occurs on servers where less than half of the replicas are located, the database services are not affected because more than half of the replicas are working normally. If a fault occurs on the server that hosts the leader, the lease will not be renewed. After the lease expires, a new leader is elected from the followers based on the election protocol and granted a new lease. After that, the database services are resumed.
Transaction layer
The transaction layer ensures the atomicity of committing DML operations on one or more partitions and the multi-version isolation among concurrent transactions.
Atomicity
The atomicity of committing a transaction is ensured through the write-ahead log, which records the modifications to transactions on a partition. When the modification of a transaction involves multiple partitions, each partition generates and persists its own write-ahead log. The transaction layer guarantees atomicity of commits through an optimized two-phase commit protocol.
The transaction layer selects a partition modified in a transaction to act as the coordinator. The coordinator communicates with all partitions modified in the transaction to determine whether the write-ahead log is persistent. When the log is persistent in all partitions, the transaction is committed. The coordinator then drives all partitions to write the commit log for this transaction, indicating the final state of the transaction. When a follower replays commit logs or the database restarts, OceanBase Database recovers the commit state of committed transactions on each partition based on the commit logs.
If a server crashes, it is possible that unfinished transactions are written to the write-ahead log but there is no commit log yet. The write-ahead log of each partition contains a list of all partitions involved in the transaction. Through this information, OceanBase Database re-determines which partition is the coordinator, restores the state of the coordinator, and drives the two-phase state machine again until the transaction is committed or aborted.
Isolation
Global Timestamp Service (GTS) is a service that generates constantly increasing timestamps in a tenant. Its availability is guaranteed by multiple replicas, with the same underlying mechanism as the partition replica synchronization mechanism described in the replication layer above.
When a transaction is committed, GTS generates a timestamp. This timestamp serves as the transaction commit version number and is persisted in the write-ahead log of the partition. This timestamp is used as the version of all modified data in the transaction.
When OceanBase Database begins a query (for the Read Committed isolation level) or a transaction starts (for Repeatable Read and Serializable isolation levels), GTS generates a timestamp as the read version number of the statement or transaction. When OceanBase Database reads data, it skips the data whose transaction version number is greater than the read version number. This provides a uniform global snapshot for data reads.
SQL layer
The SQL layer translates a user's SQL queries into data access to one or more partitions.
Components at the SQL layer
The flow for the SQL layer to process a request is: parser, resolver, transformer, optimizer, code generator, and executor.
The parser performs lexical and syntactic parsing. It divides a user-initiated SQL query into tokens, parses the query based on the predefined syntax rules, and converts the query into a syntax tree.
The resolver is responsible for semantic parsing. It translates tokens of the SQL query into the corresponding objects (such as libraries, tables, columns, and indexes) based on the database metadata, and the resulting data structure is called Statement Tree.
The transformer rewrites the SQL statements in equivalent but different formats based on internal rules or cost models, and then sends the equivalent statements to the optimizer. In this process, the transformer performs an equivalent transformation on the original statement tree, and the result of the transformation is still a statement tree.
The optimizer generates the best execution plan for the SQL query. It selects the access path, join order, and join algorithms, and determines whether to generate a distributed plan by considering various factors such as the semantics of the SQL query, characteristics of the objects, and physical distribution of the objects.
The code generator converts the execution plan into executable code but does not optimize the plan.
The executor initiates the SQL execution.
In addition to the standard SQL execution process, the SQL layer also provides the plan cache feature. A historical execution plan can be cached in memory and reused by subsequent executions. This avoids repeating the optimization process. Working with the fast-parser module, the SQL layer performs only lexical parsing to parameterize statement strings and obtains the parameterized statement and constant parameters. This way, SQL queries can directly hit the plan cache, speeding up the execution of frequently executed SQL queries.
Multiple plan types
Execution plans at the SQL layer are divided into three types, namely local plans, remote plans, and distributed plans. A local execution plan involves only data access at the local server. A remote execution plan involves only data access on a server other than the local server. A distributed execution plan involves data access on more than one server and is divided into multiple sub-plans that are executed on multiple servers.
The SQL layer can divide an execution plan into multiple parts, which are executed in parallel by multiple worker threads based on scheduling rules. Parallel execution makes full use of the CPU and I/O resources and can reduce the response time of a single query. The parallel query technology applies to both distributed and local execution plans.
Access layer
OBProxy serves as the access layer of OceanBase Database. An OBProxy forwards user queries to the appropriate OceanBase Database instance for processing.
OBProxy is an independent process instance, deployed independently of OceanBase's database instance. It listens to network ports, handles MySQL protocols, and supports the direct connection to OceanBase Database from applications using MySQL driver.
OBProxy automatically discovers the data distribution information of an OceanBase cluster. It tries to identify the data to be accessed when it receives each SQL statement, and directly forwards the statement to the OceanBase instance of the server where the data exists.
There are two deployment methods for OBProxy, one is to deploy on each application server that needs to access OceanBase Database, and the other is to deploy on the same machine as OceanBase. In the first deployment method, the application directly connects to the OBProxy deployed on the same server, and all queries are sent by the OBProxy to the appropriate OBServer. In the second deployment method, you need to use a load balancing service to aggregate multiple OBProxies into the same entry address that provides service to the application.