

















Parallel execution is an optimization strategy for SQL queries. It breaks down a query task into multiple subtasks that run simultaneously on multiple processor cores, thereby accelerating the query.
Modern computer systems widely use multi-core processors, multithreading, and high-speed network connections, making parallel execution an efficient query technique. This technique significantly reduces the response time of heavy queries and applies to business scenarios such as offline data warehouses, real-time reporting, and online big data analysis. It also powers applications in areas such as batch data transfer and quick index table construction.
Parallel execution significantly enhances the performance of the following SQL query scenarios:
- Large table scans, large table joins, large-scale sorting, and aggregation.
- DDL operations, such as modifying primary keys, changing column types, and creating indexes, on large tables.
- Table creation (using
Create Table As Select) from large amounts of data. - Batch data insertion, deletion, and updating.
Scenarios
Parallel execution applies to not only analytical systems such as offline data warehouses, real-time reporting, and online big data analytics but also OLTP scenarios to speed up DDL operations and batch data processing.
Parallel execution aims to reduce SQL execution time by making full use of multiple CPU and I/O resources. It is more efficient than sequential execution under the following conditions:
- A large amount of data is accessed.
- The concurrency of SQL queries is low.
- The requirement for latency is not high.
- Adequate hardware resources are available.
Parallel execution allows multiple processors to work on the same task concurrently, which enhances performance in the following system environments:
- Symmetric multiprocessing (SMP) systems and clusters
- Sufficient I/O bandwidth
- Abundant memory (for memory-intensive operations such as sorting and hash table construction)
- Moderate system load or load peaks (for example, the system load is generally below 30%)
If the system does not meet the preceding conditions, parallel execution may not significantly improve performance. In highly loaded systems with limited memory or I/O capabilities, parallel execution may even degrade performance.
Parallel execution has no special hardware requirements. However, the performance of parallel execution depends on the number of CPU cores, the size of memory, the storage I/O performance, and the network bandwidth. If any of these resources becomes a bottleneck, the overall performance will be compromised.
Principle
Parallel execution involves decomposing a SQL query task into multiple subtasks and scheduling these subtasks to run concurrently on multiple processors to achieve efficient parallel execution.
Once a SQL query is parsed into a parallel execution plan, the execution process proceeds with the following steps:
- The SQL main thread (the thread responsible for receiving and parsing SQL) allocates the required thread resources for parallel execution in advance according to the planned pattern. These thread resources may involve clusters across multiple machines.
- The SQL main thread enables the parallel scheduling operator (PX Coordinator).
- The parallel scheduling operator parses the plan, breaks it down into multiple operation steps, and schedules these steps in a bottom-up order. Each operation is designed to support maximum parallel execution.
- After all operations complete parallel execution, the parallel scheduling operator receives the computation results and serially completes the remaining calculations (for example, the final SUM calculation) on behalf of upper operators (for example, the aggregate operator).
Granule
In parallel data scanning, the basic unit of work is a Granule.
OceanBase Database divides a table scan task into multiple Granules, with each Granule describing the range of a scan task. Because a Granule does not span partitions, each scan task is located in one partition. Based on the Granule, parallel data scanning can be classified into the following two categories:
Partition Granule
A Partition Granule describes a complete partition. If a scan task involves multiple partitions, it is divided into the same number of Partition Granules. Partitions in a Partition Granule can be from a primary table and an index table. Partition Granules are most commonly used in partition-wise joins to ensure that corresponding partitions of the two tables are processed by the same Partition Granule.
Block Granule
A Block Granule describes a continuous data range in a partition. In a data scan scenario, block granule is usually used to divide data. A partition is divided into several blocks, and these blocks are queued and processed in parallel according to specific rules.
The following figure shows how block granule works.
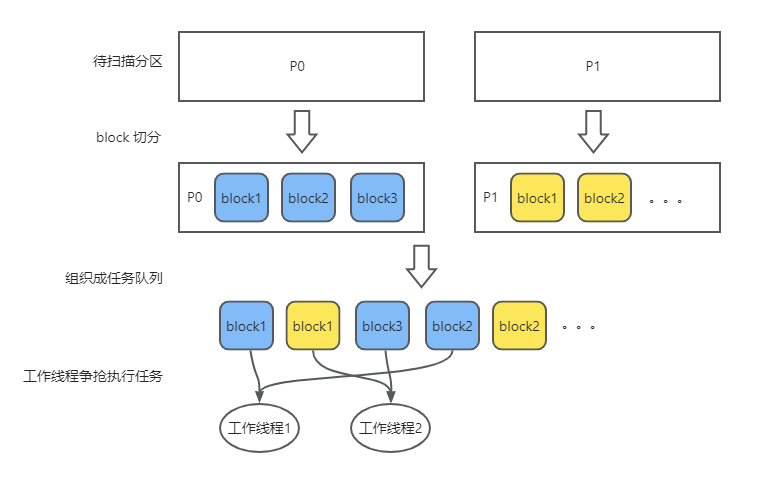
When the degree of parallelism is specified, the optimizer automatically determines whether to divide data into partition granules or block granules to maintain the balance of scan tasks. If block granules are chosen, the parallel execution framework dynamically determines the block division at runtime based on the principle that a block is neither too large nor too small. A block that is too large can cause data skew and lead to insufficient work for some threads; a block that is too small results in frequent switchovers, causing high overheads.
Once the data is divided into granules, a scan task corresponds to each granule. The table scan operator sequentially processes the scan tasks in the order of the granules and completes them one by one until all tasks are executed.
Parallel execution model
Producer-consumer pipeline model
Parallel execution is implemented using the producer-consumer pipeline model.
After a parallel scheduling operator parses an execution plan, the plan is divided into multiple operation steps. Each operation step is called a DFO (Data Flow Operation).
Generally, the parallel scheduling operator starts two DFOS simultaneously. These two DFOS are connected in a producer-consumer relationship to enable parallel execution between them. Each DFO uses a group of threads to execute tasks. This is called intra-DFO parallel execution, and the number of threads in an DFO is the DOP (Degree of Parallisim).
In the pipeline model, the consumer DFO of the current phase becomes the producer DFO of the next phase. Under the coordination of the parallel scheduling operator, the consumer DFO and the producer DFO are started simultaneously. The following figure shows the process of the producer-consumer model.
- The data generated by the DFO A is transmitted to the DFO B for processing in real time.
- After the DFO B completes the processing, the data is stored in the current thread and waits for the DFO C to start.
- After receiving the start completion notification from the DFO C, the DFO B changes its role to that of a producer and begins to transmit data to the DFO C. The DFO C starts processing after it receives the data.

In the following query example, the execution plan of the SELECT statement first performs a full-table scan on the game table, then groups and sums the data based on the team table, and finally calculates the total scores of each team in the team table.
CREATE TABLE game (round INT PRIMARY KEY, team VARCHAR(10), score INT)
PARTITION BY HASH(round) PARTITIONS 3;
INSERT INTO game VALUES (1, "CN", 4), (2, "CN", 5), (3, "JP", 3);
INSERT INTO game VALUES (4, "CN", 4), (5, "US", 4), (6, "JP", 4);
SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
obclient> EXPLAIN SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
obclient> EXPLAIN SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
+---------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |4 | |
| |1 | EXCHANGE OUT DISTR |:EX10001|1 |4 | |
| |2 | HASH GROUP BY | |1 |4 | |
| |3 | EXCHANGE IN DISTR | |3 |3 | |
| |4 | EXCHANGE OUT DISTR (HASH)|:EX10000|3 |3 | |
| |5 | HASH GROUP BY | |3 |2 | |
| |6 | PX BLOCK ITERATOR | |1 |2 | |
| |7 | TABLE SCAN |game |1 |2 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| 1 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| dop=3 |
| 2 - output([game.team], [T_FUN_SUM(T_FUN_SUM(game.score))]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(T_FUN_SUM(game.score))]) |
| 3 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| 4 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| (#keys=1, [game.team]), dop=3 |
| 5 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(game.score)]) |
| 6 - output([game.team], [game.score]), filter(nil), rowset=256 |
| 7 - output([game.team], [game.score]), filter(nil), rowset=256 |
| access([game.team], [game.score]), partitions(p[0-2]) |
| is_index_back=false, is_global_index=false, |
| range_key([game.round]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------------+
29 rows in set
The execution process of the preceding query is shown in the following figure:
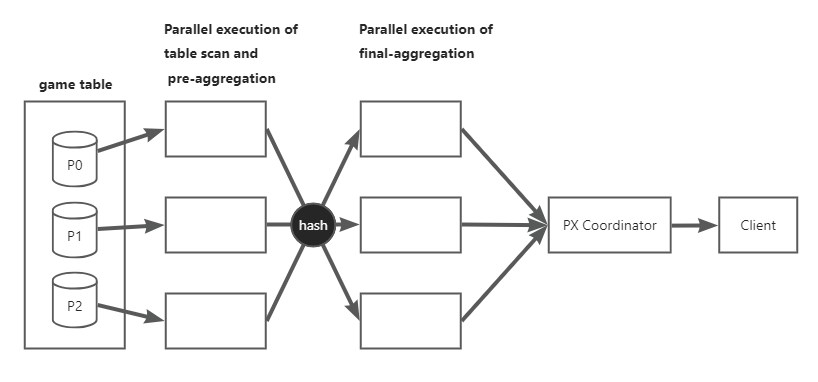
As shown in the figure, the query actually uses six threads. The execution process and task allocation are as follows:
- Step 1: The first three threads scan the
gametable and aggregate thegame.teamdata within each thread. - Step 2: The last three threads aggregate the pre-aggregated data.
- Step 3: The aggregated result is returned to the client by the parallel scheduler.
When the data from Step 1 is sent to Step 2, the data is hashed by using the game.team field to determine the destination threads.
Data distribution between producers and consumers
Data distribution refers to the method used to send data from a group of worker threads (producers) that execute in parallel to another group of worker threads (consumers). The optimizer uses a series of optimization strategies to select the optimal data redistribution method to achieve the best performance.
Common data distribution methods in parallel execution include the following:
HASH Distribution
In HASH distribution, the producers hash and modulo the data rows based on the distribution key to determine the consumer threads to send the data rows to. Generally, HASH distribution can distribute data evenly to multiple consumer threads.
PKEY distribution
In PKEY distribution, the producers calculate the partitions of the destination tables for the data rows and send the data rows to the consumer threads that process the partitions. PKEY distribution is commonly used in partial partition-wise join scenarios. In this scenario, the data does not need to be redistributed to the consumers. Instead, the data can be partition-wise joined with the data from the producers through join algorithms, thereby reducing the network communication and improving the performance.
PKEY HASH distribution
In PKEY HASH distribution, the producers calculate the partitions of the destination tables for the data rows and then hash and modulo the data rows based on the distribution key to determine the consumer threads to send the data rows to.
PKEY HASH distribution is commonly used in parallel DML scenarios. In a parallel DML scenario, multiple threads can concurrently update a partition. Therefore, the PKEY HASH distribution method is used to ensure that data rows with the same value are processed by the same thread, and data rows with different values are as evenly distributed as possible among the threads.
BROADCAST distribution
In BROADCAST distribution, each data row is sent to all consumer threads from the producers, so that each consumer thread has all the data from the producers. BROADCAST distribution is commonly used to copy data from a small table to all nodes that execute the join operation and then perform the join operation locally on each node to reduce the network communication.
BROADCAST TO HOST distribution (BC2HOST)
In BROADCAST TO HOST distribution, each data row is sent to all consumer nodes from the producers, so that each consumer node has all the data from the producers. Then, the consumer threads in the nodes cooperate to process the data.
BC2HOST distribution is commonly used in
NESTED LOOP JOINandSHARED HASH JOINscenarios. In theNESTED LOOP JOINscenario, each consumer thread obtains a part of the shared data as the driving data and uses it to perform the join operation on the target table; in theSHARED HASH JOINscenario, each consumer thread builds a hash table based on the shared data. This way, the shared data is used to avoid unnecessary overheads of building the same hash table for each thread.RANGE distribution
In RANGE distribution, the producers divide the data into segments based on ranges and distribute the data segments to the consumer threads. Generally, the consumer threads only need to sort the data within their segments to maintain the global order. RANGE distribution is commonly used in sorting scenarios.
RANDOM distribution
In RANDOM distribution, the producers randomly disperse the data and send the data to the consumer threads. This ensures that each consumer thread processes nearly the same amount of data, achieving load balancing. RANDOM distribution is commonly used in multi-threaded parallel
UNION ALLscenarios, where it is necessary to disperse the data and achieve load balancing but the data does not need to be sorted or associated in any other way.Hybrid HASH distribution
Hybrid HASH distribution is used in adaptive join algorithms. Based on the collected statistics, OceanBase Database provides a set of parameters to define regular values and frequent values. In the Hybrid HASH distribution method, regular values on both sides of the join are distributed by using the HASH method, frequent values on the left side are distributed by using the BROADCAST method, and frequent values on the right side are distributed by using the RANDOM method.

Data transmission between producers and consumers
At any time, DFOs that are parallelly scheduled by the same operator are connected in a producer-consumer manner for parallel execution. To transmit data between producers and consumers, a data transmission network is needed.
For example, suppose a data scan DFO uses DOP = 2 and a data aggregation DFO uses DOP = 3. In this case, each of the two producer threads creates three virtual links to connect to the consumer threads, resulting in a total of six virtual links. The following figure shows an example.
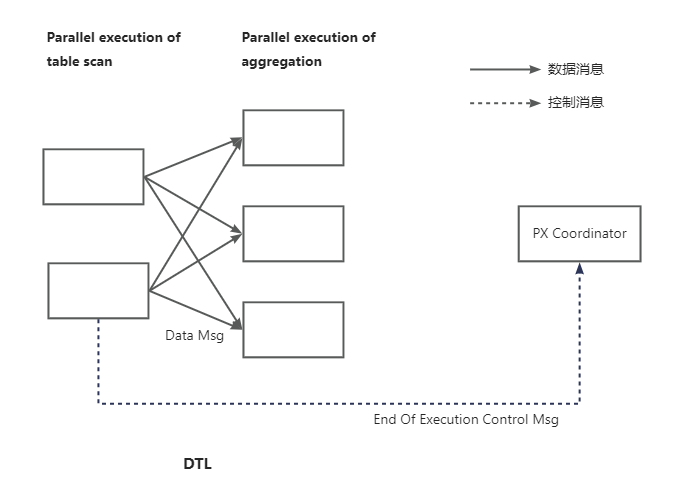
The virtual transmission network created is called the data transfer layer (DTL). In the parallel execution framework of OceanBase Database, all control messages and row data are transmitted through the DTL. Each worker thread can establish thousands of virtual links, demonstrating high scalability. Additionally, the DTL supports features such as data buffering, batch data transmission, and automatic flow control.
When the DTL is located within a node, it transmits messages through memory copying. When the DTL spans multiple nodes, it transmits messages through network communication.
Worker threads
In a parallel query, there are two types of threads: a main thread and multiple worker threads. The main thread runs in the same thread pool as that used for typical TP queries, whereas the worker threads run in a dedicated thread pool.
OceanBase Database uses a dedicated thread pool to allocate worker threads for parallel queries. Each tenant has a dedicated parallel execution thread pool on each node it belongs to. All worker threads for parallel queries are allocated from these thread pools.
Before a parallel scheduling operator schedules each DFO, it requests thread resources from the thread pool. After the DFO completes execution, the thread resources are immediately released.
The initial size of the thread pool is 0 and it can grow dynamically without an upper limit. To avoid excessive idle threads, the thread pool has an automatic thread recycling mechanism. Any thread that meets either of the following conditions will be recycled and destroyed:
- It has been idle for more than 10 minutes and the thread pool still has more than eight threads.
- It has been idle for more than 60 minutes.
Although the upper limit of the thread pool size is unlimited, two mechanisms generally set an upper limit on the actual number of threads:
- Before parallel execution starts, you must use the Admission module to reserve thread resources. You can only start execution after the reservation succeeds. This mechanism limits the number of concurrent queries.
- When you request threads from the thread pool, the maximum number of threads that can be allocated to you in one request is N. Here, N is the result of the MIN_CPU of the unit multiplied by the px_workers_per_cpu_quota tenant parameter. If more threads are needed, the maximum number of threads that can be allocated to you is N. The default value of px_workers_per_cpu_quota is 10. For example, the DOP of a DFO is 100. It needs to request 30 threads from node A and 70 threads from node B. If the MIN_CPU of the unit is 4 and the px_workers_per_cpu_quota is 10, then N = 4 × 10 = 40. In this case, the DFO can actually request 30 threads from node A and 40 threads from node B. The actual DOP is 70.
Optimize performance by load balancing
To achieve the best performance, the tasks assigned to all worker threads should be as equal as possible.
When SQL uses a block granularity to divide tasks, the system dynamically allocates tasks to worker threads. This minimizes workload imbalance, ensuring that no worker thread is obviously overloaded.
When SQL uses a partition granularity to divide tasks, you can optimize performance by setting the number of tasks to be an integer multiple of the number of worker threads. This is useful for partition-wise joins and parallel DML.
Assume that a table has 16 partitions with roughly the same amount of data in each partition. In this case, you can use 16 worker threads (with the DOP set to 16) to complete the work in about 1/16 of the time; or you can use five worker threads to complete the work in about 1/5 of the time; or you can use two worker threads to complete the work in about half the time. However, if you use 15 worker threads to process 16 partitions, the first thread will start processing the 16th partition after it completes the first one. The other threads will become idle after they complete their work. If the amount of data in each partition is similar, this configuration results in poor performance. If the amount of data in each partition varies, the actual performance varies accordingly.
Assume that you use six worker threads to process 16 partitions with roughly the same amount of data in each partition.
In this case, after each thread completes the work of the first partition, it will process the second partition. However, only four threads will process the third partition, and the other two threads will remain idle.
Generally, the time required to perform parallel operations on N partitions using P worker threads does not necessarily equal N/P. This is because some threads may need to wait for others to complete the last partition. However, you can select an appropriate DOP to minimize workload imbalance and optimize performance.
Scenarios where parallel execution is not recommended
Parallel execution is generally not recommended in the following scenarios:
Typical SQL queries take milliseconds to execute in your system.
Parallel queries have scheduling overheads measured in milliseconds. For short queries, the scheduling overheads can offset the benefits of parallel execution.
Your system is under high load.
The design goal of parallel execution is to make full use of idle system resources. If the system itself has no idle resources, parallel execution is unlikely to bring additional benefits and may even compromise the overall system performance.
Serial execution uses a single thread to perform database operations. It is more advantageous than parallel execution in the following scenarios:
- The query accesses a small amount of data.
- High concurrency is required.
- The query execution time is shorter than 100 milliseconds.
Parallel execution cannot be enabled for the following scenarios:
- The top-level DFO does not require parallel execution. It is responsible for interactions with the client and performs operations that do not require parallel execution, such as
LIMITandPX COORDINATORat the top level. - A DFO containing a
TABLEUDF can only be executed serially, but other DFOs can still be executed in parallel. - Parallel execution is not supported for ordinary
SELECTand DML statements in OLTP systems.