

















In the OceanBase Database optimizer, statistics are stored as regular data in internal tables, and a local statistics cache is maintained to speed up the access of the optimizer to statistics. In OceanBase Database of a version earlier than V4.0, statistics are collected during daily major compactions. However, statistics are not always accurate because of the incremental data involved in major compactions. In addition, histogram information cannot be collected during major compactions to resolve the issue of data skew. Therefore, the statistics feature is upgraded in OceanBase Database V4.0 and later, so that statistics are no longer collected during major compactions, and the execution plans are no longer affected by major compactions.
Types of statistics
The OceanBase Database optimizer collects three types of statistics: table statistics, column statistics, and index statistics. The following table describes these types of statistics.
Type |
Description |
|---|---|
| Table statistics |
|
| Column statistics |
|
| Index statistics |
|
Histograms and their benefits
Histograms are a special form of column statistics. By default, the optimizer considers that data is evenly distributed in a column and estimates the number of rows based on this feature. However, in real scenarios, data distribution is uneven in most tables. As a result, the optimizer inaccurately estimates the number of rows and cannot select the optimal execution plan. A histogram helps the optimizer estimate the number of rows more accurately. In a histogram, data is stored in a series of ordered buckets to describe the statistical distribution features of the column. The optimizer can estimate a more accurate number of rows based on a histogram. Each bucket of a histogram contains the following information:
Amount of data accumulated in the current bucket (including the sum of the current bucket and its previous buckets)
The end value of the current bucket.
The occurrence frequency of the end value of the current bucket.
The OceanBase Database optimizer supports three types of histograms: frequency histograms, TopK histograms, and hybrid histograms. When collecting statistics, the optimizer chooses the appropriate type of histogram based on the data distribution of columns. The following figure shows the specific strategy.
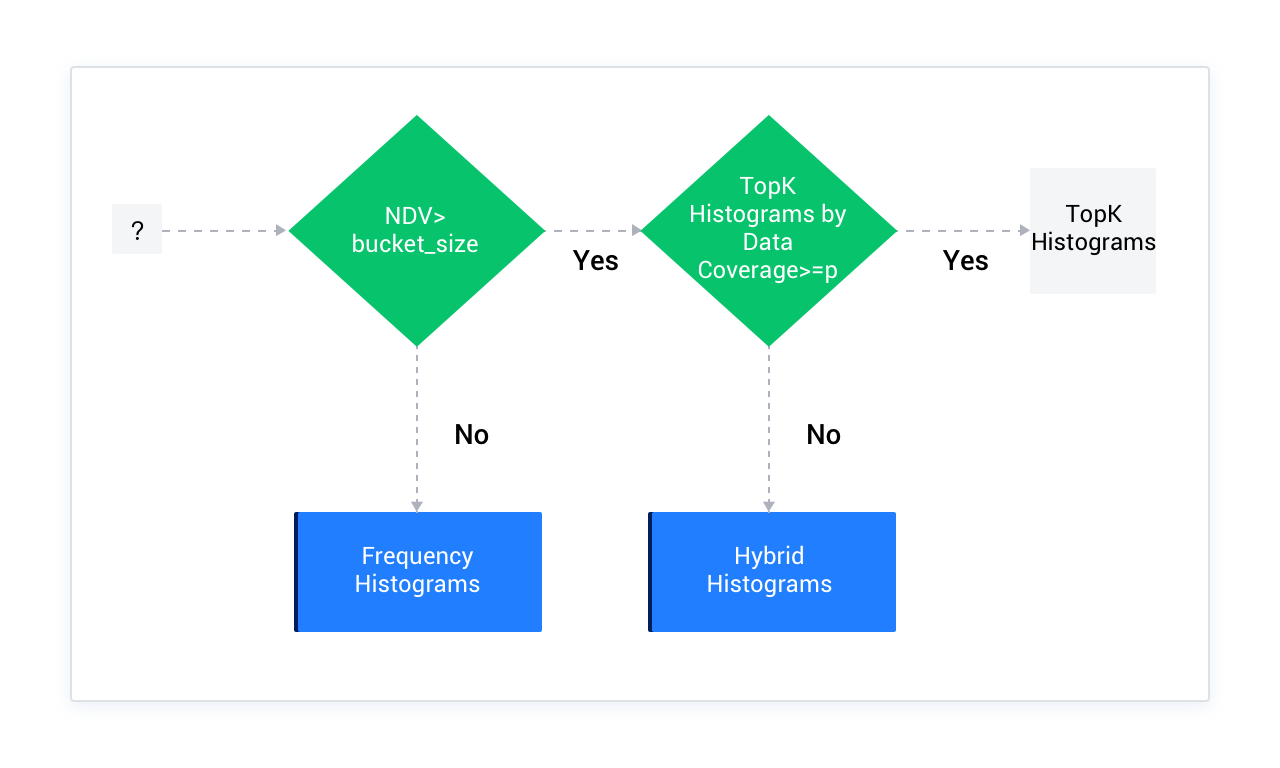
In the figure above:
- NDV indicates the number of distinct values in a column.
- bucket_size indicates the number of buckets for the histogram. The default value is 254.
- p indicates the minimum percentage threshold expected for the TopK histogram. The calculation formula is
(1 - (1/bucket_size)) × 100. If the default bucket size 254 is used, the corresponding minimum percentage threshold is 99.6.