Background information
In the information explosion era, users often need to quickly retrieve necessary information from massive amounts of data. Efficient retrieval systems are required to quickly locate content of interest in online literature databases, e-commerce product catalogs, and rapidly growing multimedia content libraries. As the amount of data continues to increase, traditional keyword-based search methods cannot meet users' needs for both accuracy and speed. This is where vector search technology comes in. It encodes different types of data, such as text, images, and audio, into mathematical vectors and performs search operations in the vector space. This allows the system to capture the deep semantic information of data and provide more accurate and efficient search results.
This topic will show you how to build a document intelligent Q&A robot using OceanBase's vector search capability.
Architecture
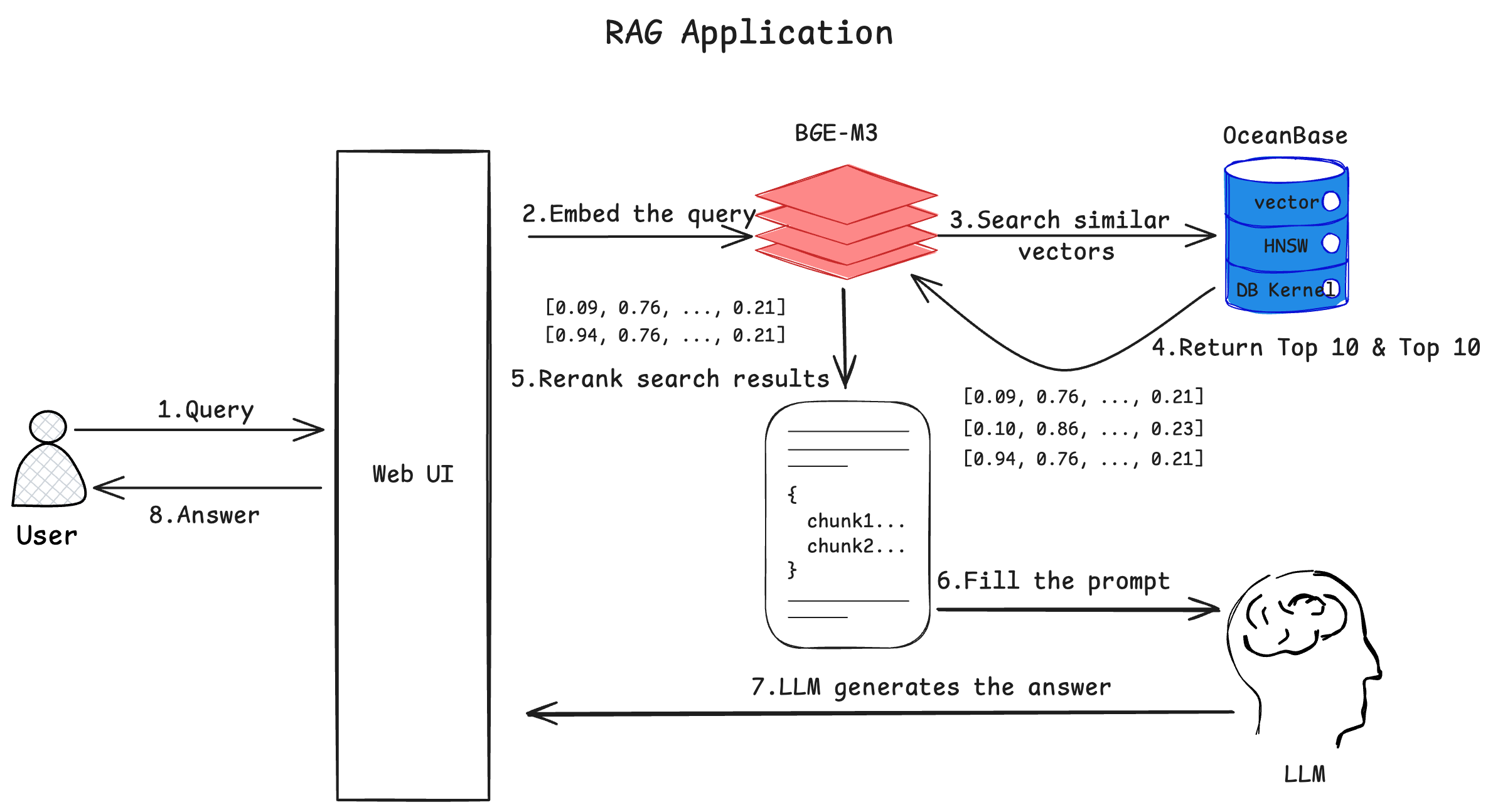
The intelligent Q&A robot stores documents as vectors within an OceanBase database. When a user asks a question through the user interface (UI), the application embeds the question into vectors by using the BGE-M3 model and retrieves similar vectors from the database. After obtaining the documents corresponding to the similar vectors, the application sends them along with the user's question to the Large Language Model (LLM). The LLM then generates a more accurate answer based on the provided documents.
Prerequisites
You have deployed OceanBase Database V4.3.3 or later and created a MySQL tenant. For more information about how to deploy an OceanBase cluster, see Overview.
The MySQL tenant you created has the
INSERTandSELECTprivileges. For more information about how to configure privileges, see Grant direct privileges.You have created a database. For more information about how to create a database, see Create a database.
The vector search feature is enabled for the database.
obclient> ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;You have installed Python 3.9 or later.
You have installed Poetry.
python3 -m ensurepip python3 -m pip install poetry
Procedure
Register for a Zhipu LLM platform account.
Log in to Zhipu LLM and obtain the API key.
Notice
- Zhipu LLM provides a free usage quota. Pay attention to your usage to avoid exceeding the free quota, as additional usage will incur fees.
- This topic uses Zhipu LLM as an example to introduce the setup of a Q&A robot. You can also use other LLMs by updating the
.envfile to change the values ofAPI_KEY,LLM_BASE_URL, andLLM_MODEL.
Clone the code repository.
git clone https://gitee.com/oceanbase-devhub/ai-workshop-2024.git cd ai-workshop-2024Install the dependencies.
poetry installSet the environment variables.
cp .env.example .env # Update the database information in the.env file. vi .envHere's how to update the contents of the
.envfile.API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxx ## The API key obtained from the Zhipu LLM platform. LLM_BASE_URL="https://open.bigmodel.cn/api/paas/v4/" ## The URL of the LLM. If you choose to use an LLM other than Zhipu, you need to update this field. LLM_MODEL="glm-4-flash" ## The model name. If you choose to use an LLM other than Zhipu, you need to update this field. HF_ENDPOINT=https://hf-mirror.com BGE_MODEL_PATH=BAAI/bge-m3 DB_HOST="127.0.0.1" ## The IP address of the tenant. DB_PORT="2881" ## The port number of the tenant. DB_USER="root@mysql_tenant" ## The tenant and username. DB_NAME="test" ## The name of the database. DB_PASSWORD="" ## The password of the tenant user.Prepare the BGE-M3 model.
poetry run python utils/prepare_bgem3.pyThe following output indicates that the model is loaded successfully.
# =================================== # BGEM3FlagModel loaded successfully. # ===================================Prepare the document corpus.
Note
This process involves converting OceanBase's open-source documents into vectors and storing them in an OceanBase database, which may take some time.
Clone the document repository.
cd doc_repos git clone --single-branch --branch V4.3.3 https://github.com/oceanbase/oceanbase-doc.git cd ..Convert the headings to the standard Markdown format.
poetry run python convert_headings.py \ doc_repos/oceanbase-doc/en-US \Embed the document text as vectors.
poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/en-US
Start the chat interface.
UI_LANG=en poetry run streamlit run --server.runOnSave false chat_ui.pyThe following result is returned:
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false. You can now view your Streamlit app in your browser. Local URL: http://localhost:8501 Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501
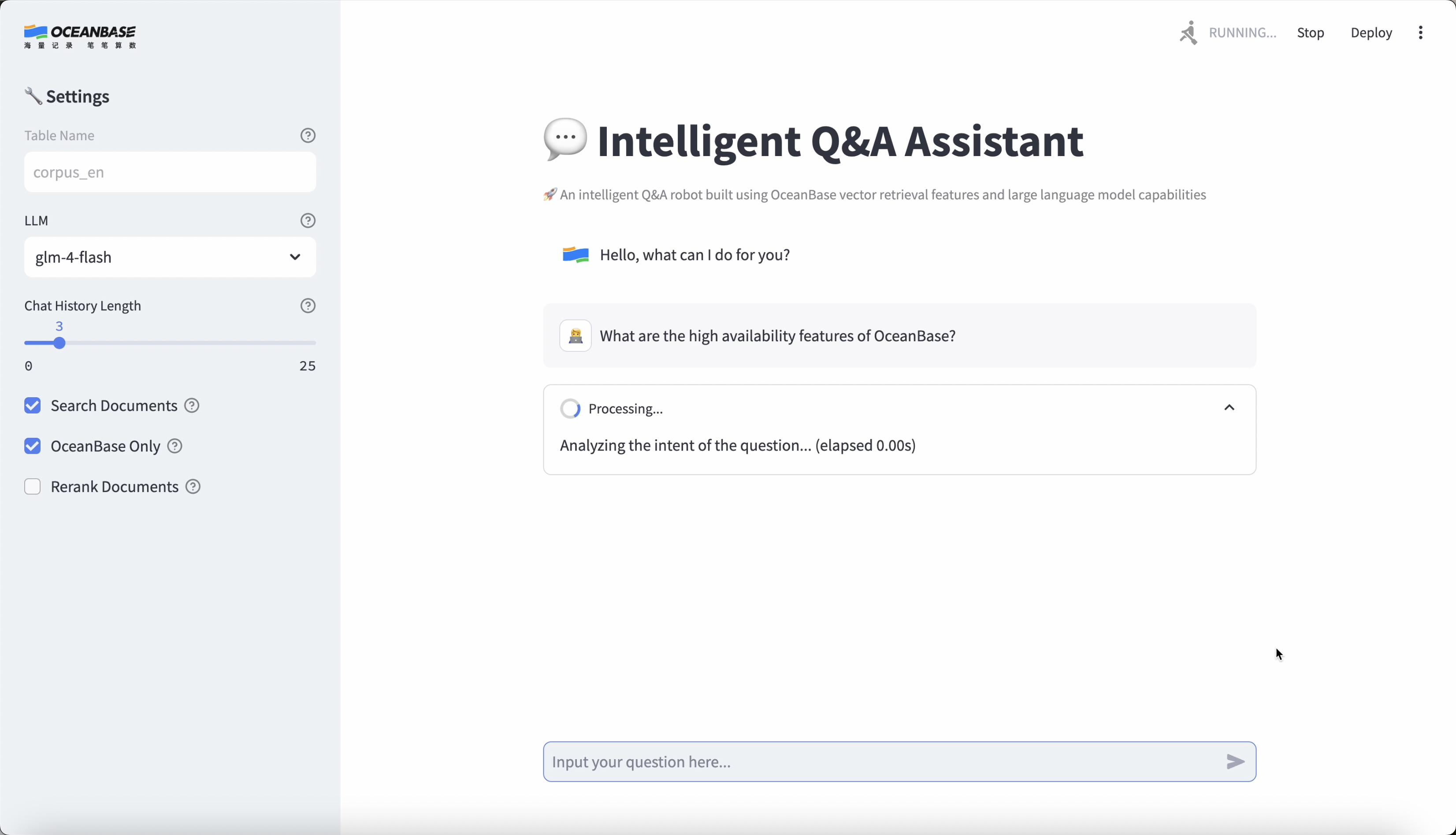
Example
Open the chat interface in your browser using the URL provided in the previous step. You can now start asking questions to the assistant.
Since this application is built using OceanBase documentation, please ask questions related to OceanBase.