

















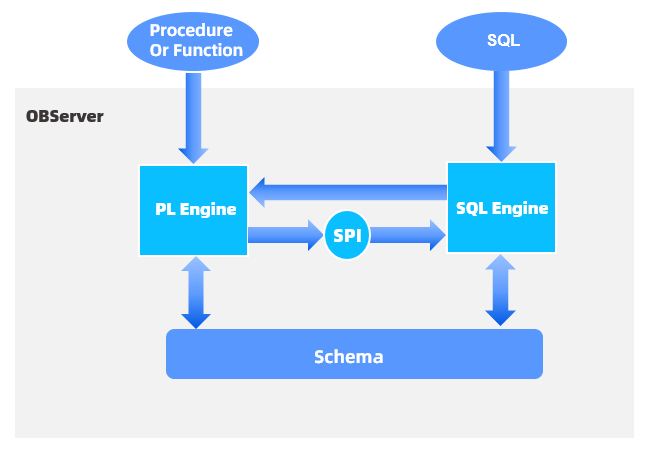
The procedural language (PL) engine works interactively with the SQL engine. SQL statements can directly access the PL engine. For example, SQL statements can call user-defined PL functions. PL can access the SQL engine through SPIs to evaluate expressions and execute SQL statements.
The following figure shows the interaction between the two engines.
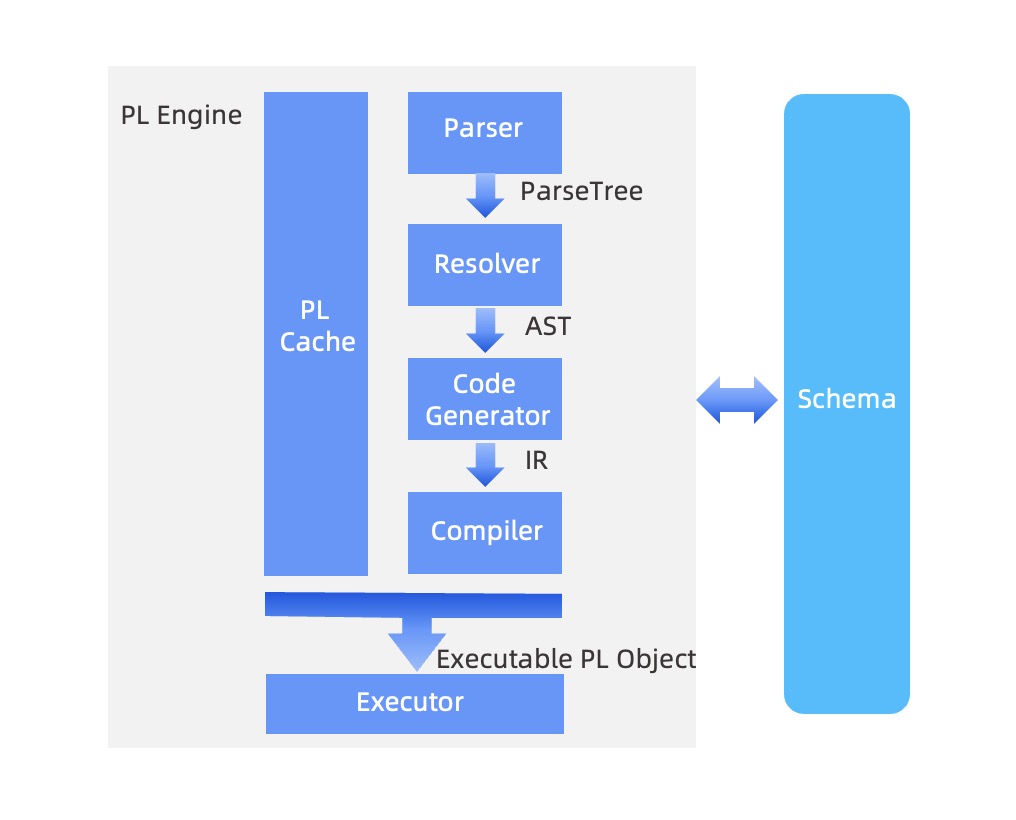
The PL engine consists of six modules: the parser, resolver, code generator, compiler, executor, and PL cache, among which the parser, resolver, code generator, and compiler form a complete PL compilation process.
The following figure shows the details.
Parser (syntax parser)
The parser analyzes PL syntax and provides a parse tree. The PL engine and the SQL engine each have their own parsers but the two parsers undertake different tasks. On the OBServer, a query string is first parsed by the PL parser. After the PL parser identifies it as an SQL statement, the PL parser sends the query to the SQL engine for parsing.
Resolver (semantic parser)
The resolver is used for semantic analysis. For example, it can check the action scope of variables and the schema of data objects in static SQL statements. It can also generate an abstract syntax tree (AST) for each PL statement and generate a global AST. The AST stores the basic information defined by PL and the generated global symbol table, global label table, and global exception table. The AST of each statement records the logical information pointed to these global tables.
Code generator
The code generator uses APIs provided by LLVM to further translate the AST into IR intermediate codes. IR codes can then be used to verify the translation process.
Compiler
The compiler converts the IR codes into machine codes through just-in-time (JIT) compilation and outputs the codes as executable PL objects.
Executor
The executor creates an execution environment based on the executable PL objects and input parameters, calls functions through function pointers, and obtains the function results.
PL cache (cache module for execution plans)
The PL cache is an internal mechanism of the PL engine. The PL engine provides unified APIs through which external systems can call procedures or functions based on IDs. The external systems can execute PL statements by using the PL engine without a need to understand the PL caching mechanism. The PL cache is a Hash table. You can find values by using keys, in other words, find executable PL objects based on procedure or function IDs. You can also access the schema to check whether the executable PL objects are valid. If an object is invalid, it will be deleted immediately. The PL cache avoids the re-compilation of PL and improves PL execution efficiency. However, for anonymous blocks, it is not necessary to use the PL cache.
The PL engine provides external Execute APIs whose parameters include PL ID, params, Context, and Result. The Result parameter is valid only for functions. The PL engine first checks whether compiled executable PL objects exist in the PL cache based on the ID. If yes, it further checks whether the version is available. If no, the PL engine calls the compilation process and caches the compilation result to the PL cache for the executor to execute. The compilation result is a memory address in binary code. The executor converts the memory address into a function pointer and transfers it to the execution parameters and execution environment for execution, to obtain the function results.