





Migrated from Legacy System to OceanBase Database, vivo Built a Robust Data Foundation Without Standalone Performance Bottlenecks




Author: Xu Shaohui from the vivo Internet and Database Tea
This article was originally published by vivo Internet Technology on WeChat Official Accounts Platform. It listed major database challenges vivo faced and described the solution provided by OceanBase, along with its implementation.
vivo is a technology company providing smart devices and intelligent services to over 500 million users worldwide. As our expanding user base kept generating more data, our database team ran into challenges in O&M of our legacy database system.
- Necessity for sharding: As the growing data volume of MySQL instances exceeded the capacity limits of a single server, we must perform database and table sharding, which incurred high costs and risks, and compelled the need for a MySQL-compatible distributed database to address these issues.
- Cost pressure: Our large user base caused significant annual data growth, and we had to keep buying new servers for data storage, leading to mounting cost pressure.
To tackle those challenges, we chose OceanBase Database after evaluating distributed database products that are compatible with MySQL and provide proven features.
Replace the Sharding Solution with OceanBase Database
We chose OceanBase Database in the expectation that its native distributed architecture and table partitioning feature could resolve the issues due to the MySQL sharding solution. We also hoped that its exceptional data compression and tenant-level resource isolation could help cut our storage and O&M costs.
(1) Native distributed architecture and table partitioning
The native distributed architecture of OceanBase Database consists of an OBProxy layer for data routing and an OBServer layer that stores data and handles computing tasks. OBServer nodes are managed in zones to ensure the proper functioning of automatic disaster recovery mechanisms and optimization strategies within an OceanBase cluster. Depending on the business scenarios, we can deploy OceanBase Database in different high-availability architectures, such as three IDCs in the same region and five IDCs across three regions. By adding or removing OBServer nodes, we can horizontally scale out or in an OceanBase cluster to quickly increase or decrease resources, thus eliminating capacity limits of a single server.
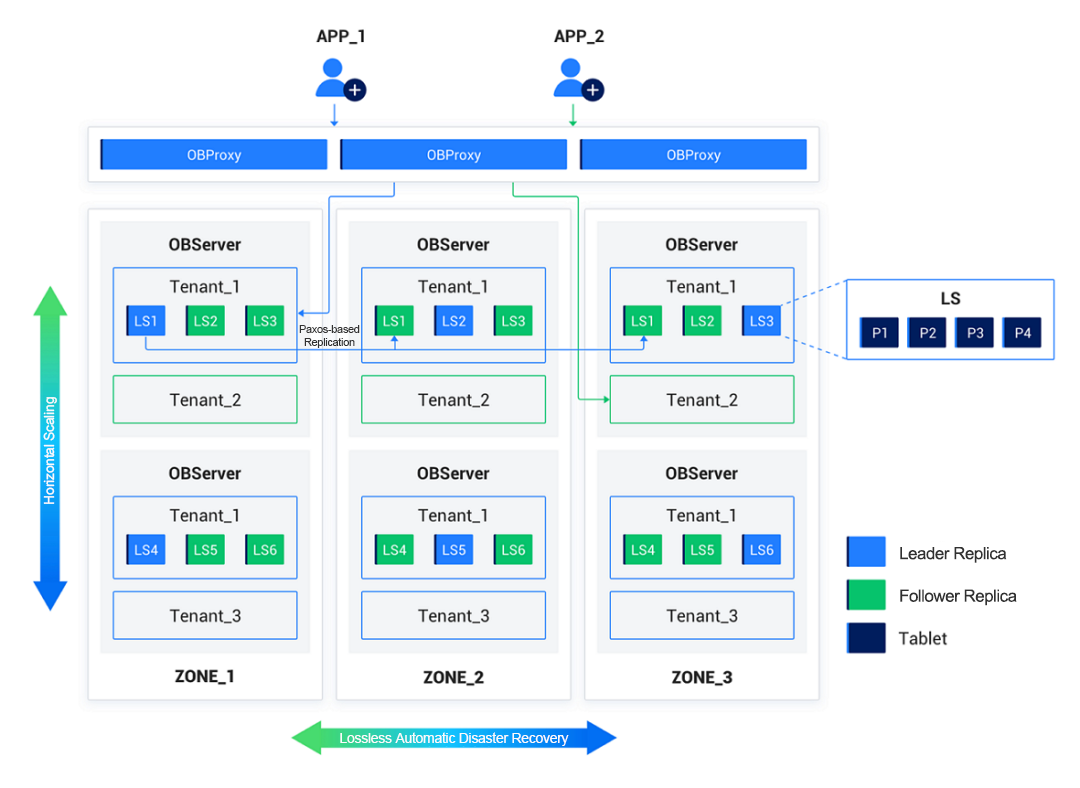
Figure: Distributed architecture of OceanBase Database
(2) Data compression and tenant-level resource isolation
OceanBase Database supports table partitioning. Partitions are evenly distributed across different OBServer nodes. Each physical partition has a storage layer object, called a tablet, for storing data records. A tablet has multiple replicas distributed across different OBServer nodes. OceanBase Database uses log streams for data persistence and inter-replica synchronization. Under normal conditions, leader replicas are used to provide services. When a leader replica fails, the system automatically uses a follower replica instead to ensure data safety and service availability.
In an OceanBase cluster, you can create multiple isolated database instances. Each of such instances is called a tenant. In other words, a single cluster can serve multiple business lines with the data of one tenant isolated from that of others. This feature reduces deployment and O&M costs.
Moreover, OceanBase Database provides a storage engine based on the log-structured merge-tree (LSM-tree) architecture, and thus boasts exceptional data compression capabilities. According to official documentation and case studies, it can slash storage costs by over 70%.
In a nutshell, OceanBase Database's native table partitioning feature effectively addresses the issues due to a sharding solution. Table partitioning is transparent to upper-layer applications. It not only greatly cuts the costs and time wasted on code modifications, but also lowers system risks and improves business availability. Additionally, OceanBase Database provides data compression algorithms that substantially shrink the storage space required, while its performance, availability, security, and community support meet our expectations and business needs.
Deploy Tools to Prepare for Migration
To ensure a successful migration to OceanBase Database and smooth database O&M in the new architecture, we deployed OceanBase Cloud Platform (OCP), OceanBase LogProxy (oblogproxy), and OceanBase Migration Service (OMS) before migration. These tools could help us manage cluster deployment, handle monitoring alerts, perform backup and restore, collect logs, and migrate data. Combined with our internal database management platform, our database administrators were able to manage metadata, and query and modify data, making the system ready for production.
(1) OCP deployment
OCP is an enterprise-level database management platform tailored for OceanBase clusters. It provides full-lifecycle management of components such as OceanBase clusters and tenants, and manages OceanBase resources such as hosts, networks, and software packages. It enables us to manage OceanBase clusters more efficiently and reduces our IT O&M costs.
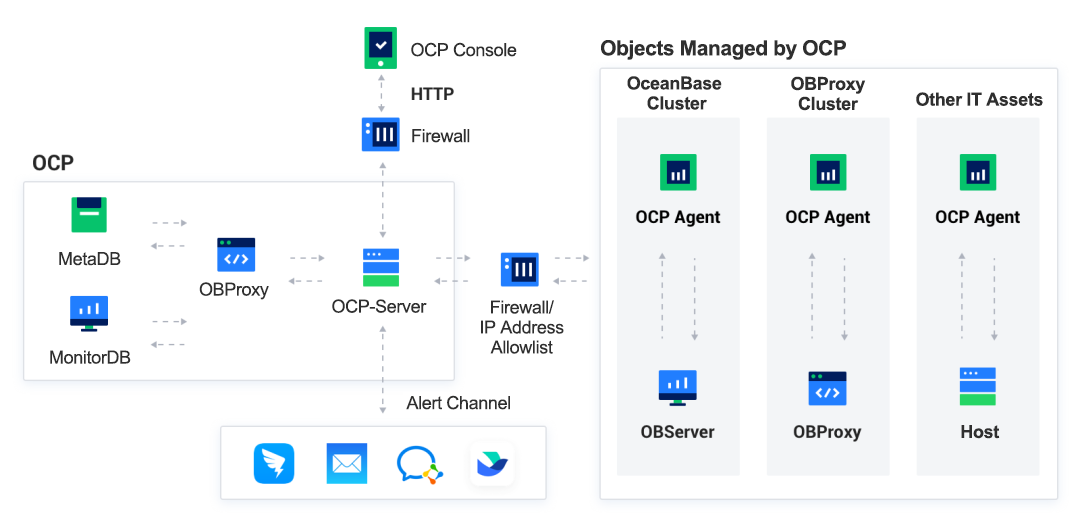
Figure: Architecture of OCP
OCP consists of six modules working in coordination: Management Agent, Management Service, Metadata Repository, Monitor Repository, Management Console, and OBProxy. It can be deployed in high availability mode, where one primary and multiple standby OCP clusters are maintained to avoid single points of failure (SPOFs).
We deployed OCP on three nodes in different IDCs. In addition, since we already had an alerting platform, we created custom alerting channels to integrate it with OCP, making it more compatible with the OCP alerting service.
Another crucial feature of OCP is backup and restore. Physical backups stored in OCP consist of baseline data and archived log data, and follower replicas are often used for backup tasks. When a user initiates a backup request, it is first forwarded to the node running RootService. RootService generates a data backup task based on the current tenant and the partition groups (PGs) of the tenant. The backup task is then distributed to OBServer nodes for parallel execution. Backup files are stored on online storage media.
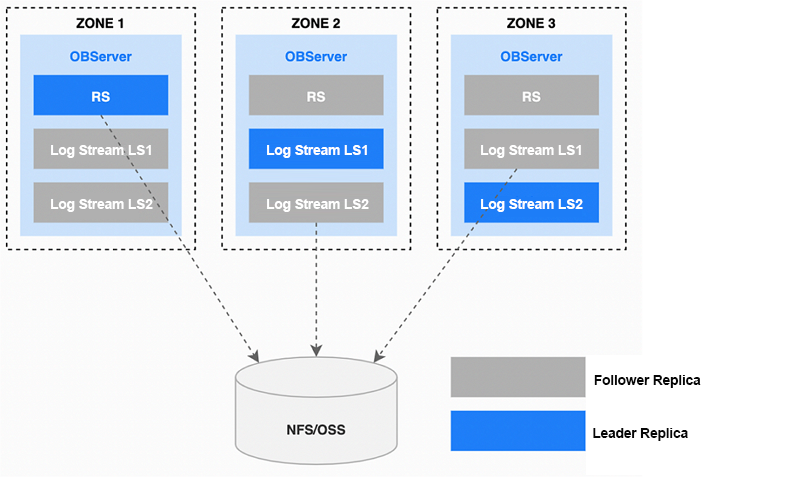
Figure: OCP high-availability architecture
OceanBase Database supports various storage media, such as Network File System (NFS), Alibaba Cloud Object Storage Service (OSS), Tencent Cloud Object Storage (COS), Amazon Simple Storage Service (S3), and object storage services compatible with the S3 protocol. Notably, the backup strategy of OCP requires S3 storage media. If you launch a cluster backup task in OCP, you must store backup files in the specified S3 directory, as shown in the following figure.
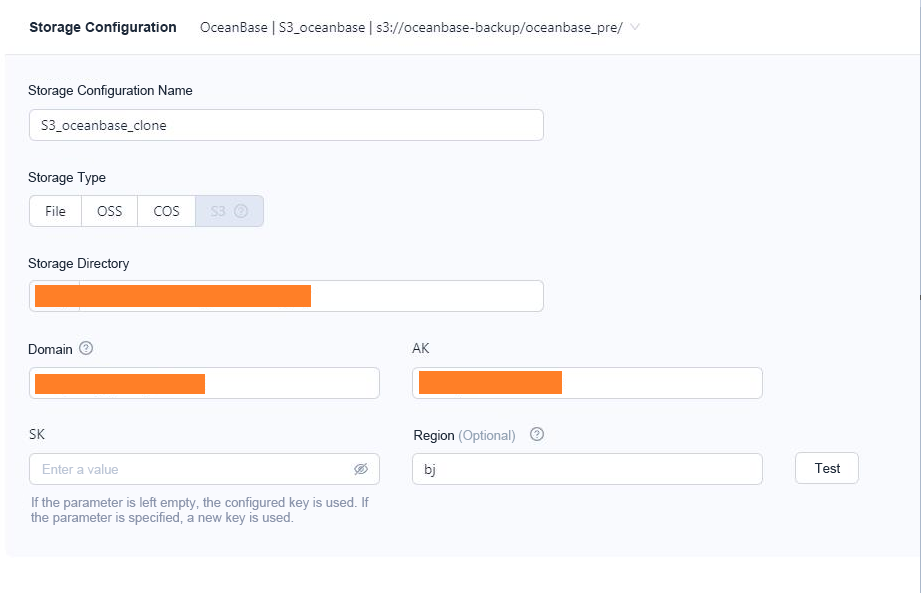
(2) oblogproxy deployment
oblogproxy is the incremental log proxy service of OceanBase Database. It establishes connections with OceanBase Database to read incremental logs and provides downstream services with change data capture (CDC) capabilities. The binlog mode of oblogproxy is designed for compatibility with MySQL binlogs. It allows us to synchronize MySQL binlogs to OceanBase Database.
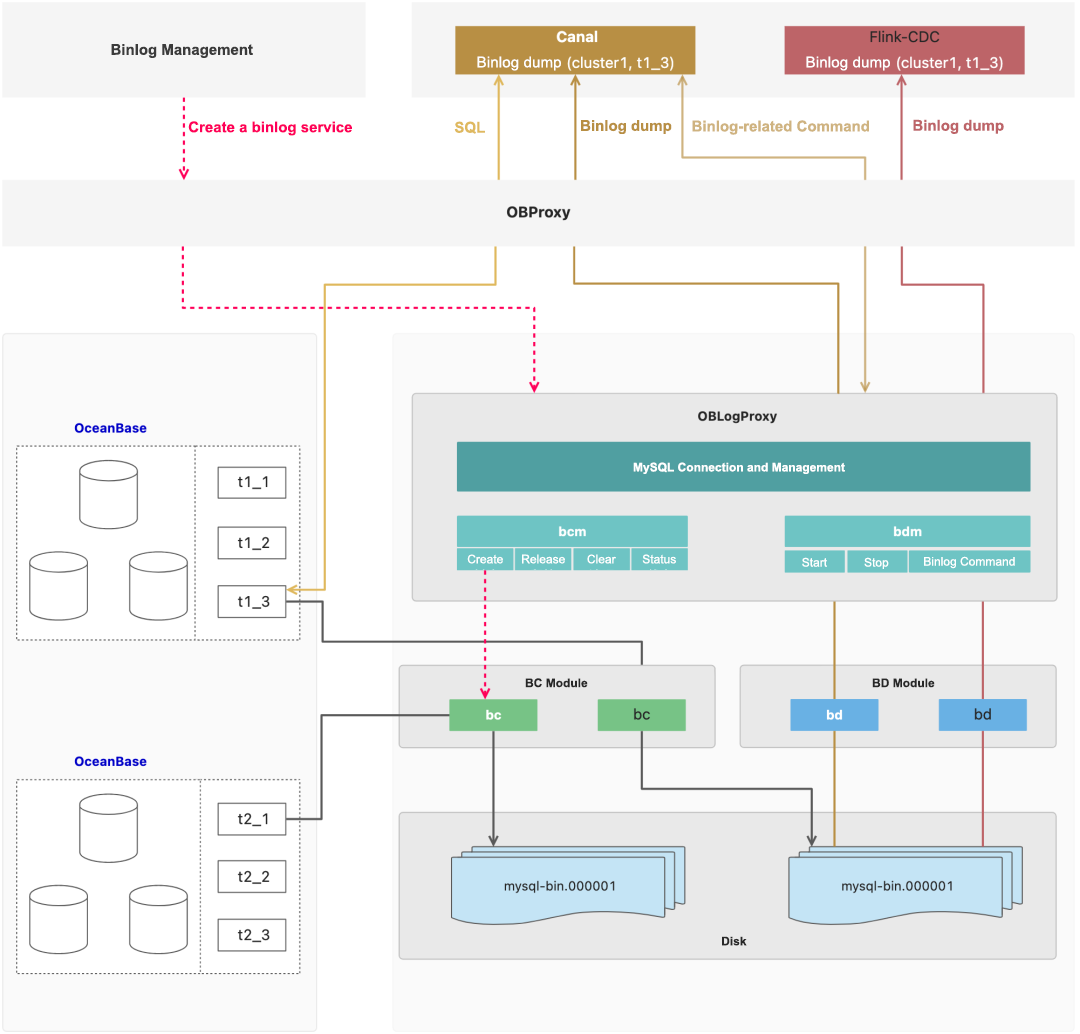
Figure: Architecture of oblogproxy
oblogproxy starts the binlog converter (BC) module to pull clogs from OceanBase Database and converts them into binlogs, which are then written to binlog files. A MySQL binlog tool, such as Canal or Flink-CDC, initiates binlog subscription requests to OBProxy, which forwards the requests to oblogproxy. Upon receiving a request, oblogproxy starts the binlog dumper (BD) module, which reads binlog files and provides subscription services by performing binlog dumps. We deployed oblogproxy across multiple nodes and stored the metadata in shared online storage to ensure high availability.
(3) OMS deployment
OMS supports data exchange between a homogeneous or heterogeneous data source and OceanBase Database. OMS provides the capabilities for online migration of existing data and real-time synchronization of incremental data.
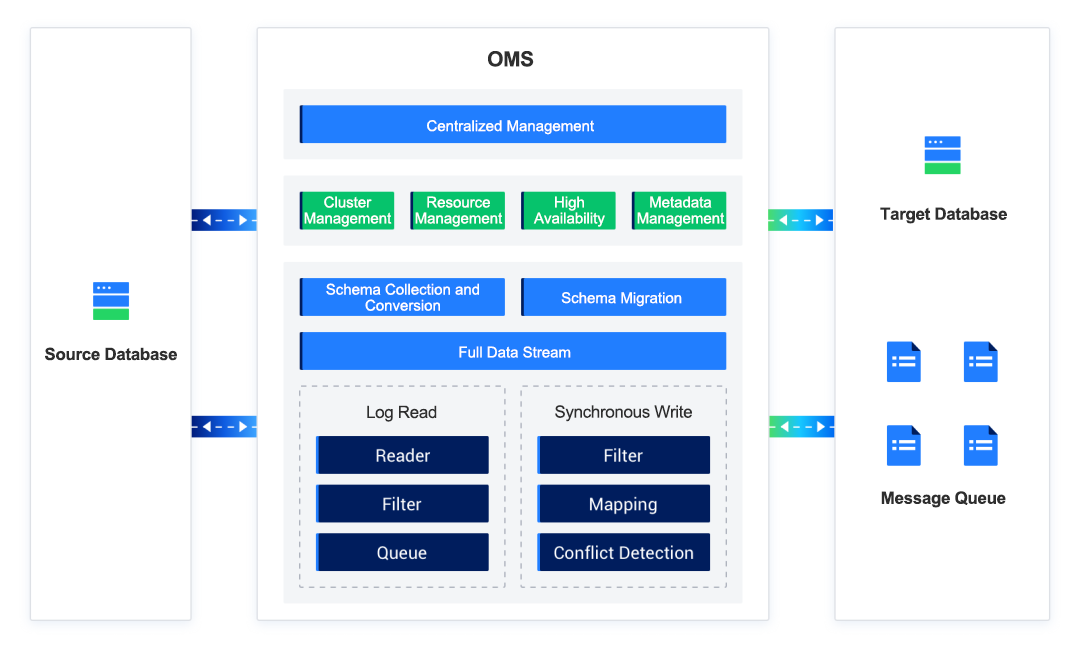
Figure: Architecture of OMS
OMS has the following components:
- DBCat: It collects and converts data objects.
- Store for pulling incremental data, Incr-Sync for synchronizing incremental data, Full-Import for importing full data, and Full-Verification for verifying full data.
- Basic service components for the management of clusters, resource pools, high availability mechanism, and metadata. These components ensure efficient scheduling and stable operations of the migration module.
- Console: It provides all-round migration scheduling capabilities.
We also deployed OMS on three nodes in different IDCs to ensure its high availability. For monitoring and alerting during data migration and synchronization, OMS leverages OCP’s alerting channels instead of implementing redundant components.
Smooth Migration to Break Capacity Limits of a Single Server
(1) Migration from MySQL to OceanBase Database
To prevent issues during migration, we conducted a feasibility assessment, which included performance stress tests and compatibility tests on, for example, table schemas, SQL statements, and accounts. The test results met our requirements. During partition adaptability testing, we found that applications required table schemas and SQL statements be adapted to partitioned tables, which, considering the modification costs, was within our expectations.
Then, we launched OMS to migrate all existing data and incremental data from MySQL to OceanBase Database. OMS ensured real-time synchronization and full data verification. Its reverse incremental synchronization feature enables instant rollback in case of migration failures, ensuring business availability.
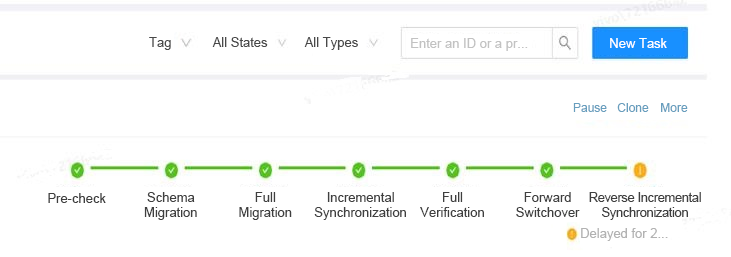
Figure: Process of a Data Migration Task in OMS
The migration process consists of eight steps:
- Pre-migration configuration verification.
- Verification of OceanBase Database tenants and accounts.
- Data consistency verification.
- Pausing DDL operations that could modify table schemas.
- Verification of synchronization latency.
- Configuring database switchover connections or modifying DNS parameters for applications.
- Terminating all connections to the source database and ensuring that applications are connected to OceanBase Database.
- Stopping forward synchronization and enabling reverse synchronization to get ready for rollback.
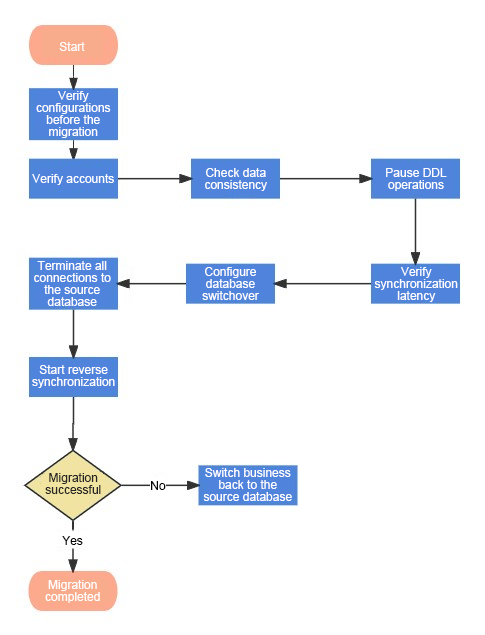
Figure: Migration process
To ensure a successful switchover, minimize risks, and maximize business availability and security, we prepared a rollback plan.
That time, we migrated nearly 20 TB of data from five MySQL clusters to OceanBase Database, which has brought us the following benefits:
- With massive and rapidly growing data stored on cloud storage services, the MySQL sharding solution caused huge maintenance and management costs and serious availability risks. OceanBase Database not only provides table partitioning to diminish maintenance costs, and its high compression ratio also saves storage expenses.
- The high data write volume of the risk control cluster caused considerable master-slave latency, risking data loss. OceanBase Database fixes that issue by ensuring strong consistency, and shrinks the required storage space by 70%.
- The TokuDB-based archive database of the financial service suffered ineffective unique indexes and lacked technical support from TokuDB. OceanBase Database has resolved these problems. It not only improves query and DDL performance, but also eliminates capacity limits of a single server, thanks to its horizontally scalable distributed architecture.
(2) Migration of another distributed database
We deployed a distributed database of another vendor to support some peripheral applications, and decided to migrate these applications to OceanBase Database. Two migration methods were considered. One was based on TiCDC, Kafka, and OMS, and the other was based on CloudCanal. Their pros and cons are described in the following figure.

The CloudCanal-based method was simple, but it did not support reverse synchronization, and demonstrated unsatisfactory performance in incremental synchronization. The other, despite a more complex architecture, was more compatible with OceanBase Database, and supported reverse synchronization, showing better overall performance. So we chose the TiCDC + Kafka + OMS method for full migration, incremental synchronization, full verification, and reverse incremental synchronization.
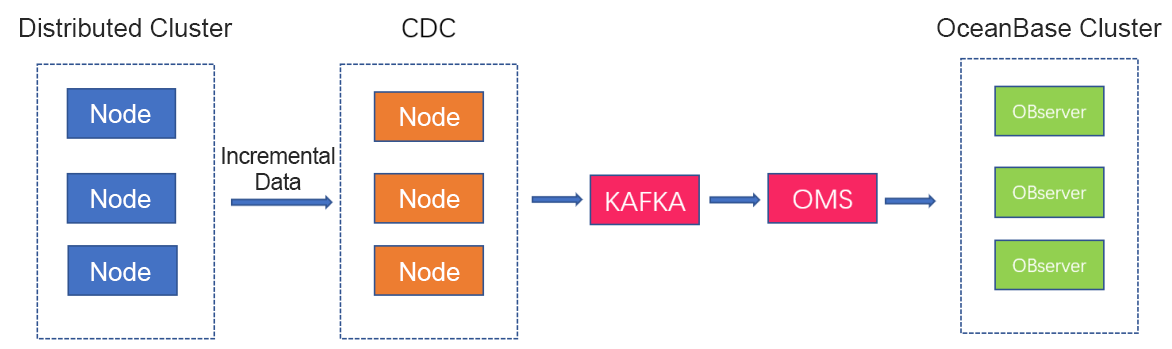
Figure: Synchronization process
As shown in the figure above, TiCDC parses incremental data from the business cluster into ordered row-level change data, and sends it to Kafka. OMS consumes this incremental data from Kafka and writes it to OceanBase Database. Kafka retains data for seven days by default, but you can adjust the retention period if the delay is considerable. You can also increase the concurrency of OMS to improve the synchronization speed.
The full migration, which involved nearly 50 billion rows, was initially quite slow, running at only 6,000-8,000 rows per second (RPS), and was estimated to take weeks to complete. Analysis revealed that the source and target databases were not under pressure, and OMS host loads were normal. The issue was traced to widely spaced values of the primary key in the source tables, causing OMS to migrate small data chunks as it used the primary key for data slicing.
We set the source.sliceBatchSize parameter to 12000 and increased memory, improving RPS to around 39,257, which still fell short of our expectations.
By analyzing the msg/metrics.log file, we found that the value of wait_dispatch_record_size reached 157690, which was pretty high, indicating OMS bottlenecks in partition calculations. So we disabled partition calculation by setting the sink.enablePartitionBucket parameter to false, and set the srink.workerNum parameter to a larger value. After that, the RPS increased to 500,000-600,000.
Here, I would like to talk about three issues occurred during migration.
Issue 1: A message reading "The response from the CM service is not success" was reported during the migration task.
Solution: The connector.log file recorded that CM service is not success, but the CM service was normal. So we checked the memory usage of the synchronization task, and found a serious memory shortage, which led to highly frequent full garbage collection, and thus service anomalies. We logged in to the OMS container, opened the /home/admin/conf/command/start_oms_cm.sh file, and set the jvm parameter to -server -Xmx16g -Xms16g -Xmn8g.
Issue 2: The RPS of incremental synchronization was quite low, around 8,000, despite high concurrency settings and normal loads of databases and OMS.
Solution: The connector.log file of the task indicated serious primary key conflicts when the incremental synchronization caught up the full synchronization timestamp, while no data exceptions were found in the source and target databases. The issue was then traced to TiCDC writing duplicate data, which in turn prevented the OMS from batch writing. Back then, OMS had not been optimized for this specific scenario, so the only way to improve RPS was to increase the write concurrency.
Issue 3: Index space amplification. When an index was created, despite the cluster's disk usage being only around 50%, this error was reported: ERROR 4184 (53100): Server out of disk space.
Solution: The OBServer log indicated that the index space usage was amplified by 5.5 times, requiring 5.41 TB of space, while the cluster only had 1.4 TB of space remained.
Index space amplification was an issue of OceanBase Database earlier than V4.2.3. The causes were as follows:
- During sorting, intermediate results were written to disk, and metadata records were also generated simultaneously.
- External sorting involved two rounds of data recording.
- During the sorting process, data was decompressed.
In OceanBase Database V4.2.3 and later, intermediate results are compressed and stored in a compact format, and the disk space is incrementally released during data writing. As a result, the index space amplification has been reduced to 1.5. Therefore, you can use OceanBase Database V4.2.3 or later for scenarios involving large datasets and great incremental data volume.
Summary
Overall, OceanBase Database has fixed vulnerabilities of vivo's previous MySQL solution, thanks to its excellent performance and data compression capabilities and robust O&M tools. Next, we will continue exploring OceanBase Database’s features and look forward to further enhancements in its O&M tools to address our challenges more effectively.
