

















Basic theories
Performance tuning
Performance tuning aims to make full use of the software and hardware capabilities to achieve the best system performance and improve the cost performance of the software and hardware in production environment, thereby lowering the costs for customers. You can run the perf stat command collect the hardware performance metrics within a period of time, as shown in the following example:
Performance counter stats for process id '3260':
182250.331423 task-clock (msec) # 18.221 CPUs utilized
3,259,379 context-switches # 0.018 M/sec
1,628,966 cpu-migrations # 0.009 M/sec
51 page-faults # 0.000 K/sec
442,995,845,816 cycles # 2.431 GHz
226,812,458,841 instructions # 0.51 insn per cycle
45,556,284,037 branches # 249.965 M/sec
662,510,643 branch-misses # 1.45% of all branches
10.002402740 seconds time elapsed
Performance tuning procedure
The performance tuning procedure is as follows:
Determine the optimization objectives.
Throughput: Pay attention to the CPU information and component bottlenecks. At present, both the ODP and OBServers can exhaust CPU resources.
Latency: Pay attention to the number of components on the access link and the time consumption on each segment. The network latency must also be considered.
Experience: From a global perspective, performance tuning performed nearer to the business system achieves better effects.
Perform stress testing and collect required information: Besides the target data, you must also collect other data such as the CPU usage and network latency of each component.
Analyze the stress and identify the performance bottleneck: Based on the collected data, identify the component that causes the bottleneck and then perform detailed analysis.
Implement optimization: Adjust parameters and deployments. In special cases, you may need to modify the code and release a new version.
Confirm the optimization effect: Observe whether the throughput and latency meet the customer requirements or test results.
ODP performance
Data summary
Performance data:
Queries per second (QPS) = Concurrency × 1000 ms/RT)
Response time (RT) = 1000 ms/(QPS/Concurrency)
The network latency within an IDC is within 100 μs.
The forwarding efficiency of the OBServer is lower than 50% of the forwarding efficiency of ODP.
ODP performance data:
In the case of exclusive use, the QPS is between 20,000 and 35,000 and affected by factors such as the CPU model. The QPS will be higher if the stress is low and hyper-threading (HT) is not used.
If the ODP is deployed on the same physical server as an OBServer node, resource preemption occurs. In this case, the performance will be higher if load balancing is configured for ODP.
Compared with other deployment modes, deployment on the application side achieves the best performance.
The advanced RISC machine (ARM) platform is supported but its performance is lower than that of the x86 platform.
Troubleshooting
The issues of ODP are mainly related to the QPS and RT.
QPS: You can improve the QPS through scale-out. If scale-out is not supported, you can improve the performance of individual ODP instances. If the CPU resources are sufficient but the QPS is low, you must analyze the issue based on the actual situation.
RT: You can view the execution time on the ODP in slow query logs. The execution time on the ODP is at the μs level. The RT is greatly affected by the overall architecture.
When you handle issues, you must be clear with your objectives. For example, if data migration by using OceanBase Migration Service (OMS) is slow because the ODP has become a bottleneck due to full CPU utilization, you can increase the number of ODP instances.
Thread model
You can add the -H parameter to the top command to check the thread status. The worker threads of ODP are obproxy and the threads whose name starts with ET NET. In ODP, threads basically share nothing with each other and each thread can work independently. Requests can be evenly distributed to the worker threads.
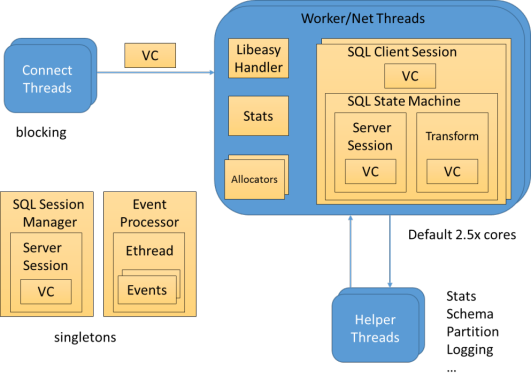
Parameter adjustment
Parameters involved in performance tuning:
alter proxyconfig set enable_compression_protocol=false; -- Disable compression to reduce the CPU utilization.
alter proxyconfig set proxy_mem_limited='16G'; --You can dynamically adjust the value as needed to prevent out-of-memory (OOM) errors.
alter proxyconfig set enable_prometheus=false;
alter proxyconfig set enable_metadb_used=false;
alter proxyconfig set enable_standby=false;
alter proxyconfig set enable_strict_stat_time=false;
alter proxyconfig set use_local_dbconfig=true; This parameter is available in ODP V3.x and later.
alter proxyconfig set work_thread_num= xxx; --xxx must be smaller than or equal to the actual number of cores.
Routing accuracy
The forwarding efficiency of an OBServer is lower than that of ODP. Therefore, the routing accuracy of ODP is essential in core scenarios, for which local plans are recommended. This is not required in non-core scenarios. At present, ODP supports routing based on regular tables, partitioned tables, logical data centers (LDCs), and primary zones. For more information, see Data routing.
Process performance analysis
Thread model data
The following table describes the CPU usage under the assumption that the QPS is 100,000.
Number of threads |
QPS |
CPU usage |
IPC |
Context switching |
|---|---|---|---|---|
| 4 | 100021.12 | 3.979 | 0.49 | 19746 context-switches # 0.165 K/sec 4043 cpu-migrations # 0.034 K/sec |
| 8 | 99985.25 | 5.816 | 0.36 | 1294736 context-switches # 0.007 M/sec (100.00%) 19267 cpu-migrations # 0.110 K/sec (100.00%) |
| 12 | 99943.38 | 6.763 | 0.33 | 2239606 context-switches # 0.011 M/sec (100.00%) 80049 cpu-migrations # 0.395 K/sec (100.00%) |
| 16 | 99912.43 | 7.345 | 0.31 | 2885634 context-switches # 0.013 M/sec (100.00%) 172082 cpu-migrations # 0.781 K/sec (100.00%) |
| 20 | 99959.15 | 8.102 | 0.33 | 3256951 context-switches # 0.013 M/sec (100.00%) 296914 cpu-migrations # 0.001 M/sec (99.99%) |
| 24 | 100032.52 | 8.156 | 0.29 | 3673410 context-switches # 0.015 M/sec (100.00%) 471850 cpu-migrations # 0.002 M/sec (100.00%) |
View performance data by using tools
You can view performance data by using the following tools.
topcommandYou can use the
topcommand to view the CPU utilization of an ODP in real time. If the CPU utilization of the ODP exceeds that of the OBServer, the ODP performance is abnormal and further analysis is required.You can use the
top -Hcommand to view the CPU utilization of threads, which is steady in normal cases.
perfcommandYou can use the
perf topcommand to view hotspot functions. At present, no functions in ODP has a CPU utilization of more than 5%.You can use the
perf statcommand to view hardware metrics, which are helpful in analyzing the performance of CPUs of different models.
Log printing
Logging severely compromises performance. You can check the ODP log generation interval. If a log is generated every 1 to 2 seconds, the performance will be significantly downgraded.