

















This topic describes the rules for selecting the access path in OceanBase Database.
Currently, OceanBase Database provides pre-rules, or forward rules, and skyline pruning rules, or reverse rules. The pre-rule is based on strict matching and directly specifies the index to use for a query.
The skyline pruning rule compares two indexes. If an index dominates another index in some defined dimensions, the inferior index is pruned, and the remaining index is compared in terms of cost to decide the optimal plan.
The OceanBase Database optimizer applies pre-rules first to select indexes. If no matching index is found, it applies the skyline pruning rule to exclude some inferior indexes. The remaining indexes are compared by using the cost model to select the one with the lowest cost.
As shown in the following example, OceanBase Database displays the information about a path selection rule in the plan demonstration.
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d));
Query OK, 0 rows affected
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| =====================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
-------------------------------------
|0 |TABLE SCAN|t1(k1)|2 |94 |
=====================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178058bf0)], [t1.b(0x7f3178058860)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), filter(nil),
access([t1.b(0x7f3178058860)], [t1.a(0x7f3178058bf0)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), partitions(p0),
is_index_back=true,
range_key([t1.b(0x7f3178058860)], [t1.shadow_pk_0(0x7f31780784b8)]), range(1,MIN ; 1,MAX),
range_cond([t1.b(0x7f3178058860) = 1(0x7f31780581d8)])
Optimization Info:
-------------------------------------
t1:optimization_method=rule_based, heuristic_rule=unique_index_with_indexback
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(k3)|1 |7 | |
| ==================================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.c(0x7f3178058e90)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter(nil), sort_keys([t1.c(0x7f3178058e90), ASC])
1 - output([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter([t1.c(0x7f3178058e90) < 5(0x7f3178058808)]),
access([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), partitions(p0),
is_index_back=false, filter_before_indexback[false],
range_key([t1.a(0x7f3178059220)]), range(MIN ; MAX)always true
t1:optimization_method=cost_based, avaiable_index_name[t1,k3], pruned_index_name[k1,k2]
optimization_method indicates the detailed rule information. It has the following two formats:
optimization_method=rule_basedindicates the hit of a pre-rule. It is followed by the rule name.unique_index_with_indexbackis the third type of pre-rule, which requires that three conditions must be met: "exact match with a unique index + table access by index primary key is required + the number of table access by index primary key operations is less than the specified threshold".optimization_method=cost_basedindicates that the path selection is based on the cost. It is followed by the access paths pruned by skyline pruning as listed inpruned_index_name, and the remaining access paths as listed inavailable_index_name.
Pre-rules
At present, pre-rules in OceanBase Database only apply to simple single table scanning. Pre-rules are based on strict matching. An index is applied as soon as a pre-rule is hit. Therefore, pre-rules are used only in limited scenarios to prevent the risks of incorrect selection.
Depending on whether the query criteria cover all index keys and whether the use of the index requires table access by index primary key, OceanBase Database classifies pre-rules into the following three types based on the priority:
Exact match with a unique index + no table access by index primary key is required. The primary key is considered a unique index in this case. If multiple indexes hit the pre-rule, the one with the minimum number of columns is selected.
Exact match with a normal index + no table access by index primary key is required. If multiple indexes hit the pre-rule, the one with the minimum number of columns is selected.
Exact match with a unique index + table access by index primary key is required + the number of table access by index primary key operations is less than the specified threshold. If multiple indexes hit the pre-rule, the one with the minimum number of table access by index primary key operations is selected.
Full index match means that an equality condition exists on every index key, which corresponds to get or multi-get.
In the following example, query Q1 hits index uk1 (exact match with a unique index + no table access by index primary key is required) and query Q2 hits Index uk2 (exact match with a unique index + table access by index primary key is required + at most four rows returned by a table access by index primary key operation).
obclient> CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );
Query OK, 0 rows affected
Q1:
obclient> SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);
Q2:
obclient> SELECT * FROM test WHERE (c = 1 OR c =2) AND (d = 1 OR d = 2);
Skyline pruning rules
The skyline operator is a relatively new database operator introduced in 2001. It is not a typical SQL operator. Information scientists have since invested a great deal of effort in studying the skyline operator, such as its syntax, semantics, and execution.
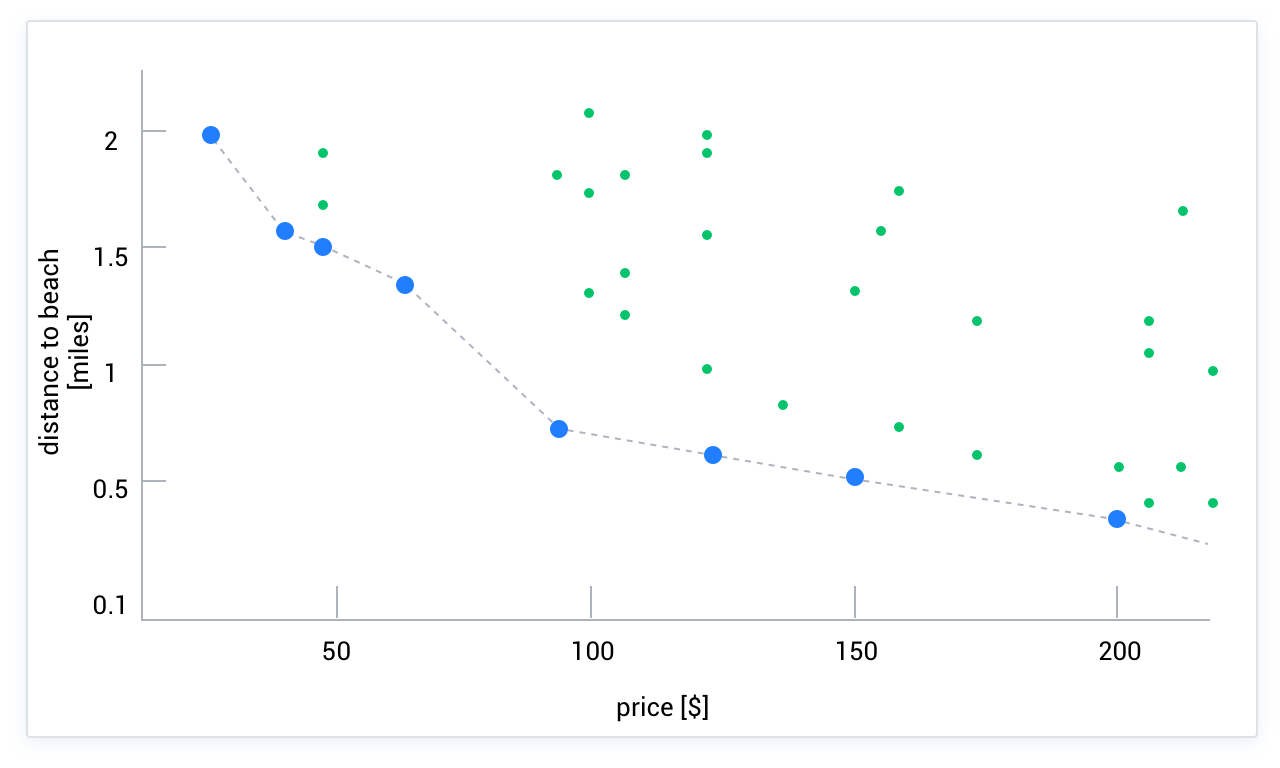
Skyline literally refers to points in the sky that forms its boundaries. These points make up the set of optimal solutions in a search space. For example, you want to find the most inexpensive and nearest hotel. Imagine a two-dimensional coordinate system, with the horizontal axis being the price and the vertical axis being the distance. Every point in the space represents a hotel. As shown in the following figure, the optimal solution is definitely on the "skyline" of this space. Assume that Point A is not on the skyline. You can find a point, such as Point B, on the skyline that is better than Point A in both dimensions. In this scenario, Point B is a hotel that is more inexpensive and closer to you, and Point B dominates Point A. If you cannot establish the significance of multiple dimensions, or these dimensions cannot be comprehensively quantified, you can use the skyline algorithm. If comprehensive quantification is possible, you can use an SQL function and ORDER BY to get the job done.
Given Object Set O, the principle of the skyline operation is to find the set of objects that are not dominated by other objects. If Object A is not dominated by Object B in any dimension, and Object A dominates Object B in at least one dimension, Object A dominates Object B. In other words, the selection of dimensions and the definition of the domination relationship on each dimension are two major factors in the skyline operation. Assume that the optimizer can choose from N index paths <idx_1, idx_2, idx_3...idx_n>, and for query Q, index idx_x dominates index idx_y on the defined dimensions, the optimizer can prune index idx_y off to remove it from the final cost comparison.
Definition of dimensions
For skyline pruning, the following three dimensions are defined for the indexes including the primary key:
Necessity for table access by index primary key
Existence of an interesting order
Extraction of the query range from index prefixes
The following example is provided for analysis:
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, a INT, b INT, c INT,
KEY idx_a_b(a, b),
KEY idx_b_c(b, c),
KEY idx_c_a(c, a));
Query OK, 0 rows affected
Necessity for table access by index primary key in the query:
/*Primary table access is necessary if index idx_a_b is selected because idx_a_b does not contain column c.*/ obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;Existence of an interesting order:
/*The ORDER BY clause can be eliminated if index idx_b_c is selected.*/ obclient>SELECT pk, b FROM skyline ORDER BY b;Extraction of the query range from index prefixes:
/*By using index idx_c_a, the range of rows can be quickly located without a full table scan.*/ obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
The domination relationship between indexes is defined by these three dimensions. If Index A is not dominated by Index B in any of the three dimensions and dominates Index B in at least one dimension, a plan based on Index B will not be better than a plan based on Index A. Therefore, Index B can be pruned off. The judgment is made on the following basis:
If table access by index primary key is not required for
idx_A, but is required foridx_B,idx_Adominatesidx_Bin this dimension.If the interesting order extracted from
idx_Ais vectorVa<a1, a2, a3 ...an>, the interesting order extracted fromidx_Bis vectorVb<b1, b2, b3...bm>, andn > m, indexidx_Adominates indexidx_Bin this dimension whenai = bi (i=1..m).If the set of columns for extracting the query range is
Sa<a1, a2, a3 ...an>foridx_A, andSb <b1, b2, b3...bm>foridx_B, andSais a superset ofSb,idx_Adominatesidx_Bin this dimension.
Table access by index primary key
Table access by index primary key checks only whether the queried column is included in the index. However, in some scenarios, such as a scenario where neither the primary table nor the index tables have an interesting order or can be used to extract the query range, using the primary table is not necessarily the optimal solution.
obclient> CREATE TABLE t1(
pk INT PRIMARY KEY, a INT, b INT, c INT, v1 VARCHAR(1000),
v2 VARCHAR(1000), v3 VARCHAR(1000), v4 VARCHAR(1000),INDEX idx_a_b(a, b));
Query OK, 0 rows affected
obclient>SELECT a, b,c FROM t1 WHERE b = 100;
Index |
Table access by index primary key |
Interesting order |
Query range |
|---|---|---|---|
| primary | No | No | No |
| idx_a_b | Yes | No | No |
The index table is narrow if compared with the primary table. Although the primary table dominates idx_a_b in the three dimensions, the cost of an index scan plus table access by index primary key operation is not necessarily higher than a full scan of the primary table. Simply put, an index table may have only one macroblock to read, while a primary table may have 10. Because of this, it is necessary to allow for some margin for rules and reflect comprehensively on specific filter conditions.
Interesting order
If the optimizer can utilize the underlying order by leveraging the interesting order, it does not need to sort the rows scanned at the underlying layer. This also eliminates the need for ORDER BY by performing MERGE GROUP BY instead, which can optimize the Pipeline because materialization is not required.
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected
obclient> (SELECT DISTINCT v1, v3 FROM skyline JOIN tmp WHERE skyline.v1 = tmp.c1
ORDER BY v1, v3) UNION (SELECT c1, c2 FROM tmp);

The execution plan shows that ORDER BY is eliminated, while MERGE DISTINCT is applied. Sorting is also omitted for UNION. The order generated from the underlying TABLE SCAN can be used by the upper-layer operators. In other words, retaining the row order from idx_v1_v3_v5 allows subsequent operators to perform better operations without changing the order. The optimizer can generate a better execution plan only if it recognizes these orders.
Therefore, when you perform skyline pruning based on the interesting order, you must take into consideration the order in which the indexes can make the maximum use. For example, the most useful order in the preceding example is (v1, v3) rather than just v1. The order (v1, v3) derived from the MERGE JOIN operator can also be used by the MERGE DISINCT operator and then the UNION DISTINCT operator.
Query range
The extraction of the query range allows for the location of a specific macroblock at the bottom layer, reducing the I/O resource consumption at the storage layer.
For example, SELECT * FROM t1 WHERE pk < 100 AND pk > 0 can be applied to locate the specific macroblock by using the level-1 index. This makes the query faster because a more accurate query range allows the database to scan fewer rows.
obclient> CREATE TABLE t1 (
pk INT PRIMARY KEY, a INT, b INT,c INT,
KEY idx_b_c(b, c),
KEY idx_a_b(a, b));
Query OK, 0 rows affected
obclient> SELECT b FROM t1 WHERE a = 100 AND b > 2000;
For idx_b_c, the query range is (b), which can be extracted from its index prefix. For idx_a_b, the extracted query range is (a, b). So, idx_a_b dominates idx_b_c in this dimension.
Examples
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected
obclient> SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;
Index |
Table access by index primary key |
Interesting order |
Query range |
|---|---|---|---|
| primary | No | No | No |
| idx_v1_v3_v5 | No | (v1) | (v1, v3) |
| idx_v3_v4 | Yes | No | (v3) |
idx_v1_v3_v5 is not dominated by either the primary key index or idx_v3_v4 in any of the three dimensions. Based on the skyline pruning rule, the primary key index and idx_v3_v4 are pruned off. The validity of skyline pruning depends on the correct definition of dimensions. Incorrect dimensions may cause improper pruning of indexes, leaving the selection of the optimal plan an impossible task.