

















Compatible with HBase APIs, OBKV-HBase is a wide table database dedicated to the storage of massive structured or semi-structured data and high access performance.
Core benefits
Stable P99
OBKV-HBase is developed by using C++ and uses a self-developed memory management subsystem. It does not have the issue of Java garbage collection (GC) or other jitter issues caused by memory, as seen in open-source HBase. Taking advantage of TP refinement and optimization in storage access links achieved by OceanBase Database over the past decade and more, OBKV-HBase demonstrates excellent P99 stability.
Hot replica
OBKV-HBase is built based on the native high-reliability capabilities of OceanBase Database and uses the Paxos protocol to ensure strong consistency among multiple replicas. When a node fails, the failover to a hot replica is quickly performed to ensure business continuity. OceanBase Database V4.0 can achieve a recovery time objective (RTO) less than 8s. Open-source HBase is built based on a storage/computing splitting architecture, where each partition at the RegionServer layer has only one replica. When a fault occurs, business will be unavailable for several minutes due to the process of partition scheduling and fault recovery.
Disaster recovery across zones
OBKV-HBase allows you to deploy a cluster instance across multiple zones. Typical disaster recovery architectures include three IDCs across two regions and five IDCs across three regions, which provide higher disaster recovery capabilities. Generally, open-source HBase implements the primary/standby cluster mode for disaster recovery based on HLogs. However, to achieve the same disaster recovery level, open-source HBase requires more replicas, leading to higher costs.
High performance
Both OBKV-HBase and open-source HBase use a storage engine based on the log-structured merge-tree (LSM-tree). Therefore, they have the same benefit in write performance. Based on over 10 years of continuous development and optimization in TP scenarios by OceanBase Database, OBKV-HBase can achieve ultimate read performance. In scenarios with large amounts of data, OBKV-HBase can achieve read performance more than four times higher than that of open-source HBase.
Easy O&M
OBKV-HBase provides only OBServer nodes for users, who do not need to concern about the differences among roles involved in distributed implementation. OceanBase Database provides a series of easy-to-use development and O&M tools to simplify O&M. OceanBase Database is an all-in-one database. The O&M for OBKV is exactly the same as that for OceanBase Database. This reduces the workload in performing O&M on multiple databases while unifying the technical stack.
Application scenarios
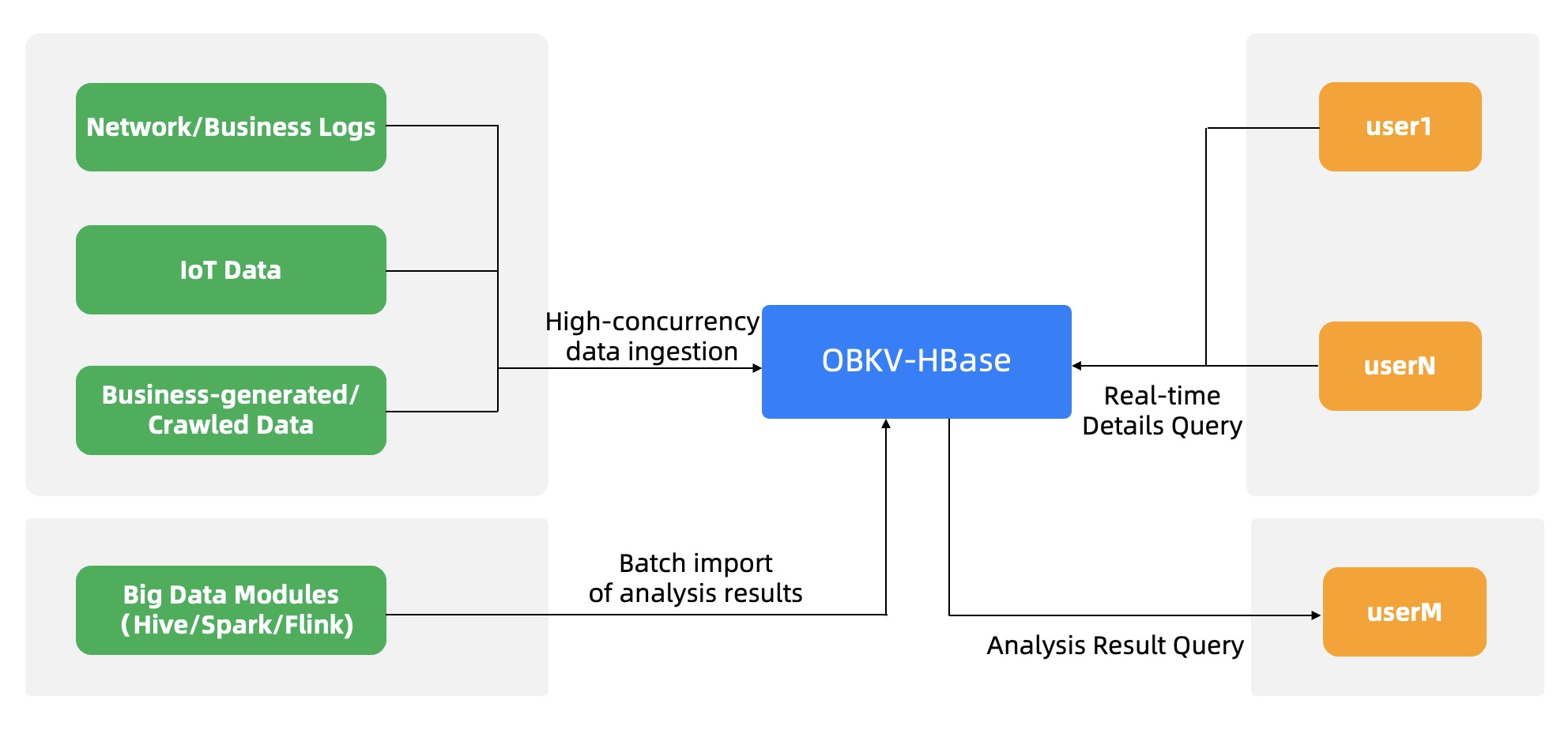
Massive data storage
OBKV-HBase is built based on the distributed storage engine of OceanBase Database to provide real-time reads and writes and low-cost storage of massive data. It supports API-based batch import and direct load.
OBKV-HBase adapts to open-source components such as DataX and Flink for efficient incremental and full data synchronization. It can integrate with Flink and other data warehousing and big data components for real-time or offline data analysis. It can also implement real-time analysis of data in a database based on the integration and real-time data warehousing capabilities of OceanBase Database. You can use OBKV-HBase to quickly store application logs, Internet of Things (IoT) data, trace data, and monitoring data in real time, and perform online or offline data analysis based on the data warehousing or big data component.
High-performance real-time access to characteristics data in scenarios such as recommendation and risk control
Based on the TP capabilities accumulated by OceanBase Database in over 10 years, OBKV-HBase can support low-latency data reads. It can also handle concurrent access at a level of 10 million or higher through horizontal scaling.
OBKV-HBase supports HBase features such as schemaless, wide tables, sparse columns, multiple data versions, and TTL. It can flexibly store characteristics data and support high-performance access to the data in scenarios such as recommendation and risk control.