

















Histograms are a special type of column statistics. Data is stored in a series of ordered buckets to describe the statistical distribution features of the column. The optimizer can estimate a more accurate number of rows based on a histogram.
By default, the optimizer considers that data is evenly distributed in a column and estimates the number of rows based on this feature. However, in real scenarios, data distribution is uneven in most tables. A histogram helps the optimizer estimate the number of rows more accurately.
In the OceanBase Database optimizer, column histogram statistics are stored in the ALL_TAB_HISTOGRAMS, DBA_TAB_HISTOGRAMS, and USER_TAB_HISTOGRAMS views and include the following information:
Applicability
At present, OceanBase Database Community Edition does not support the ALL_TAB_HISTOGRAMS and USER_TAB_HISTOGRAMS views.
Basic information of the histogram, including
tenant_id,table_id,partition_id, andcolumn_idStatistics type of the histogram, where the information level can be
GLOBAL,PARTITION, orSUBPARTITIONAmount of data accumulated per bucket in the histogram (including the sum of the current bucket and its previous buckets)
Maximum value in each bucket in the histogram
Frequency of the maximum value in each bucket in the histogram
Types of histograms
The optimizer of OceanBase Database supports three types of histograms: frequency histograms, TopK histograms, and hybrid histograms.
In a frequency histogram, each distinct column value corresponds to a single bucket in the histogram. The number of buckets specified must be no less than the NDV value of the column.
A TopK histogram is a variant of the frequency histogram. Based on the Lossy Counting algorithm, it estimates the overall data distribution by calculating the feature of some data at a ratio of no less than 1-(1/bucket_size).
A hybrid histogram is set based on a specified amount of data collected and is a supplement to frequency histograms and TopK histograms.
Frequency histograms
In a frequency histogram, each distinct column value corresponds to a dedicated bucket in the histogram. Because each value has a dedicated bucket, some buckets may have many values while others few. For example, we have 20 coins in four different denominations (CNY 0.1, CNY 0.2, CNY 0.5, and CNY 1) in a purse. We put all CNY 0.1 coins in the first bucket, CNY 0.2 coins in the second bucket, CNY 0.5 coins in the third bucket, and CNY 1 coins in the fourth bucket, and get the following frequency histogram. Taking into consideration the characteristics of histograms, the number of buckets specified must be no less than the NDV value of the column.
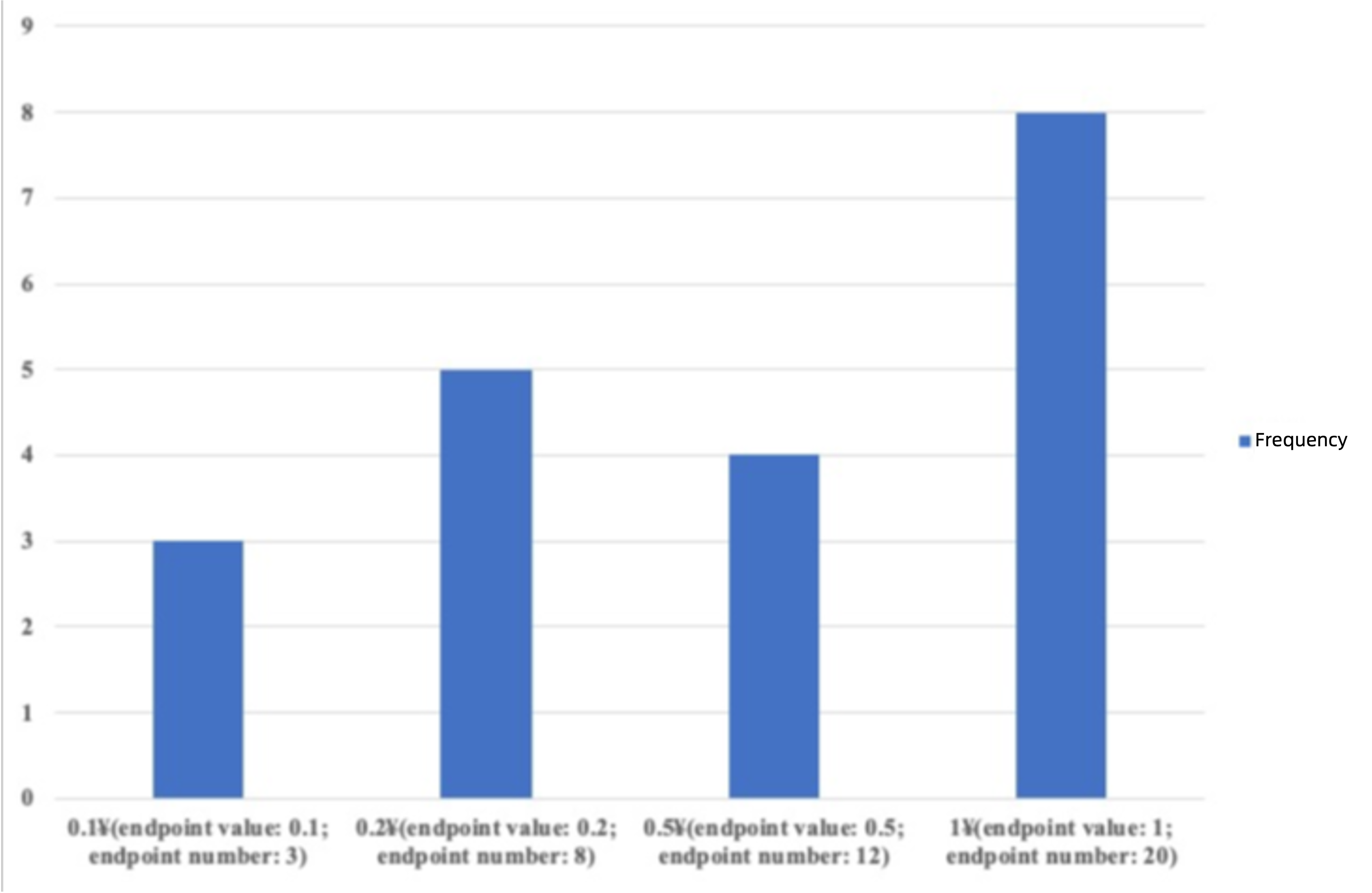
TopK histograms
A TopK histogram is a variant of the frequency histogram. When the number of buckets specified is less than the NDV of the column, we can use a TopK histogram, which ignores low-frequency values and demonstrates the distribution of high-frequency values. For example, we have 100 coins in four different denominations (CNY 0.1, CNY 0.2, CNY 0.5, and CNY 1) in a purse. Among them, only one is a CNY 0.1 coin. If we have only three buckets, we can ignore the CNY 0.1 coin and create the following TopK histogram to demonstrate the distribution of the remaining coins.
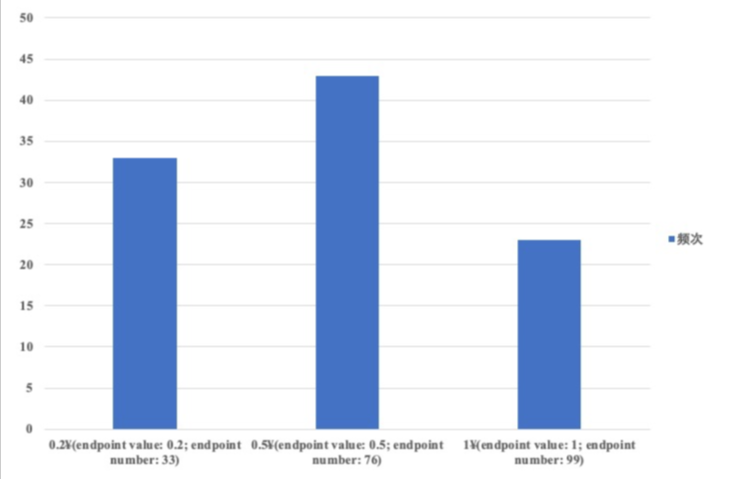
A TopK histogram estimates the overall distribution by calculating only part of the data. Therefore, to restrict the error, the ratio of the data records in the TopK histogram to all data records must be no less than 1-(1/bucket_size). For example, in the above scenario, for a total of 100 coins, the specified number of buckets is 3, the TopK histogram records 99 coins. That is, the ratio 99/100 is greater than 1-(1/3), which meets the requirement. The OceanBase Database optimizer implements TopK histograms mainly based on the Lossy Counting algorithm.
Hybrid histograms
For a large table with massive data, when the number of buckets specified is lower than the NDV value and the minimum ratio requirement of the TopK histogram cannot be met, you can use a hybrid histogram, which is more balanced, to describe data distribution. A hybrid histogram is set based on a specified amount of data collected. Unlike frequency histograms and TopK histograms, in a hybrid histogram, a bucket may contain multiple different values. The collected data records are divided into segments whose number is the same as that of buckets. Data records in each segment are placed in the corresponding bucket, so that a minimum number of buckets are used to describe the distribution of data at a larger volume. The maximum value in each bucket is endpoint_value. endpoint_repeat_cnt records the frequency of endpoint_value.
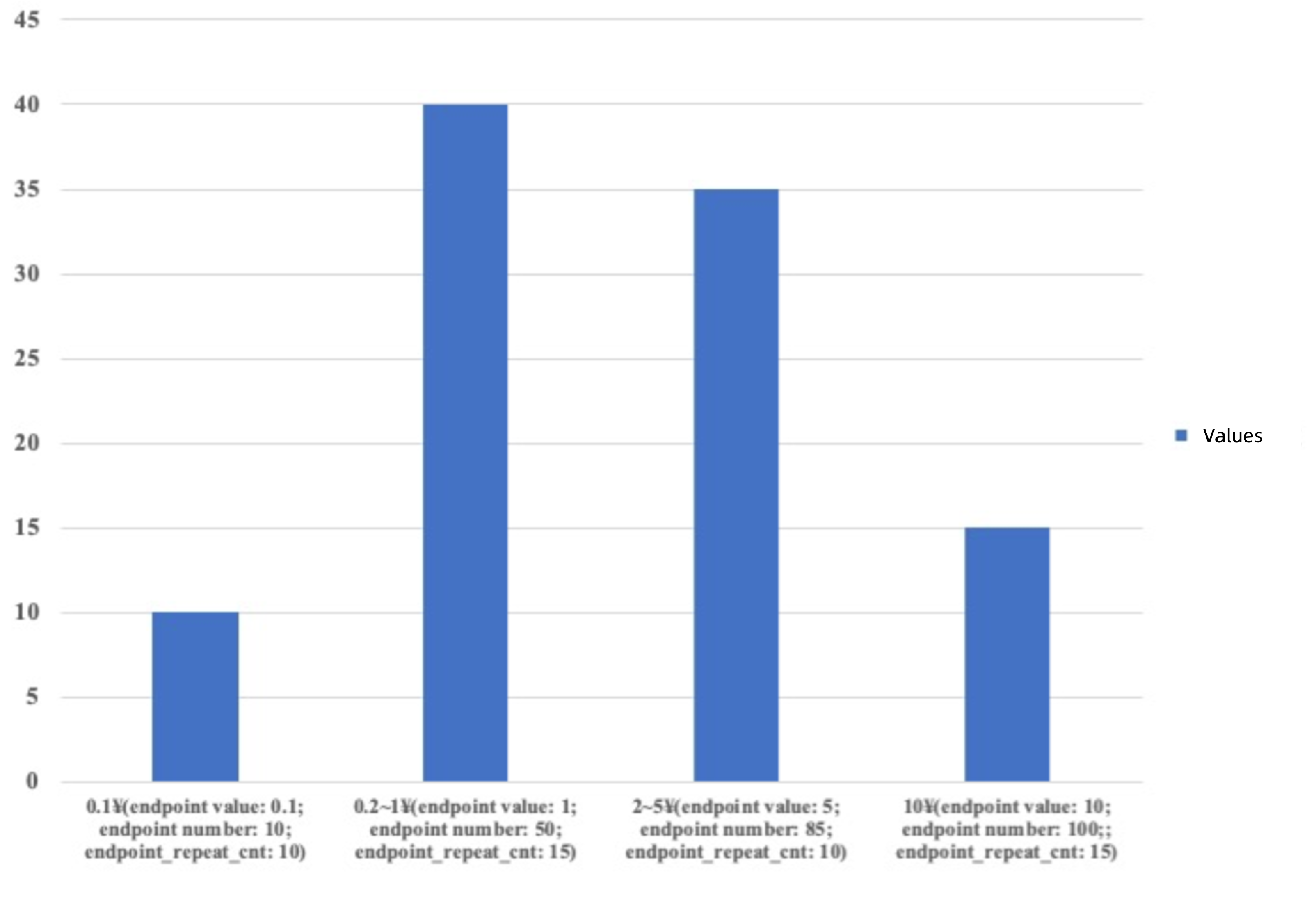
For example, we have 100 coins, 10 in CNY 0.1, 10 in CNY 0.2, 15 in CNY 0.5, 15 in CNY 1, 25 in CNY 2, 10 in CNY 5, and 15 in CNY 10. The ratio of data covered by a TopK histogram is (25+15+15+15)/100=0.7, while the minimum ratio required for generating a TopK histogram is 1-1/N = 3/4 = 0.75, which means that a TopK histogram cannot be generated. N is the number of specified buckets, which is 4 (smaller than the NDV value) in this case, so a frequency histogram cannot be generated.
The following figure shows a hybrid histogram generated for this case.
Selection of histograms
The OceanBase Database optimizer selects the histogram type according to the values of NDV, bucket_size, and p.
The following figure shows the strategy for selecting histograms.
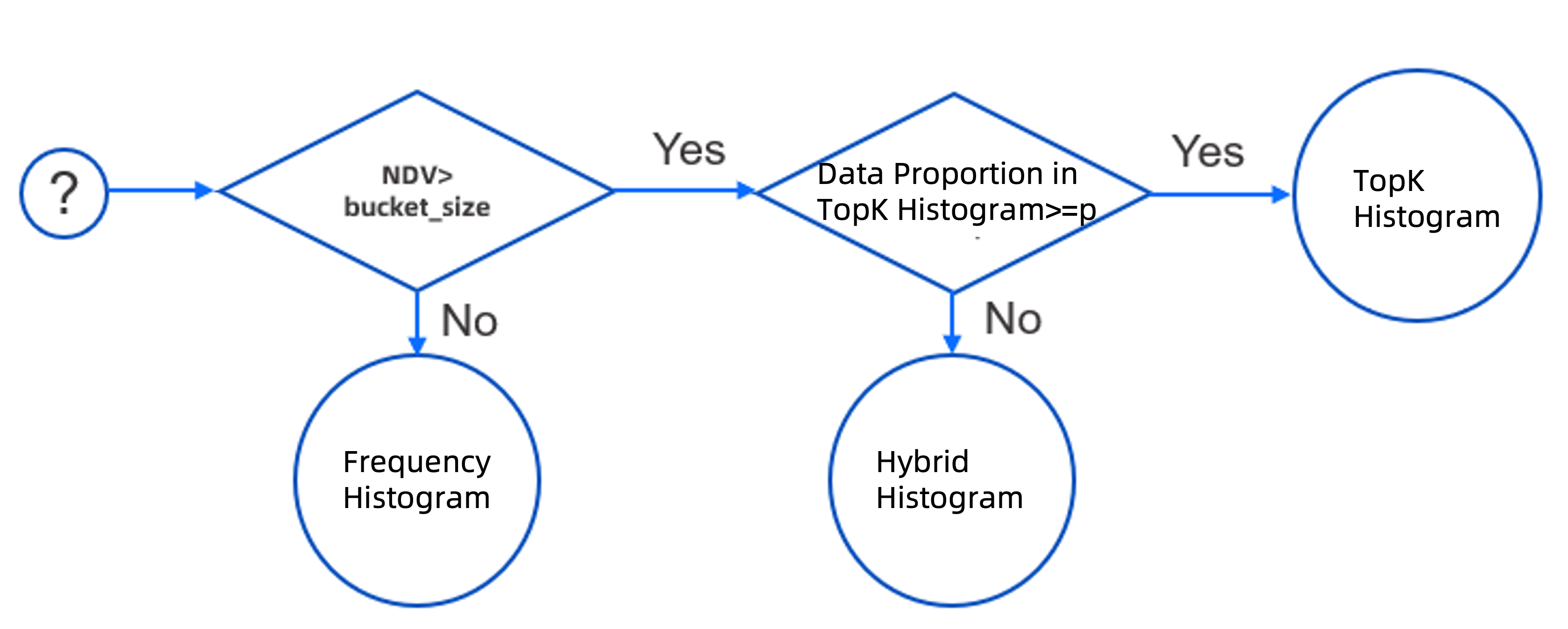
The metrics are described as follows:
NDV: the number of distinct values in a column.bucket_size: the number of buckets for the histogram. The default value is 254.p: the minimum percentage threshold expected for the TopK histogram. The calculation formula is(1 - (1/bucket_size)) × 100. If the default bucket size 254 is used, the corresponding minimum percentage threshold is 99.6.