

















Distributed execution overview
OceanBase Database adopts a distributed shared-nothing architecture that can generate and execute distributed execution plans.
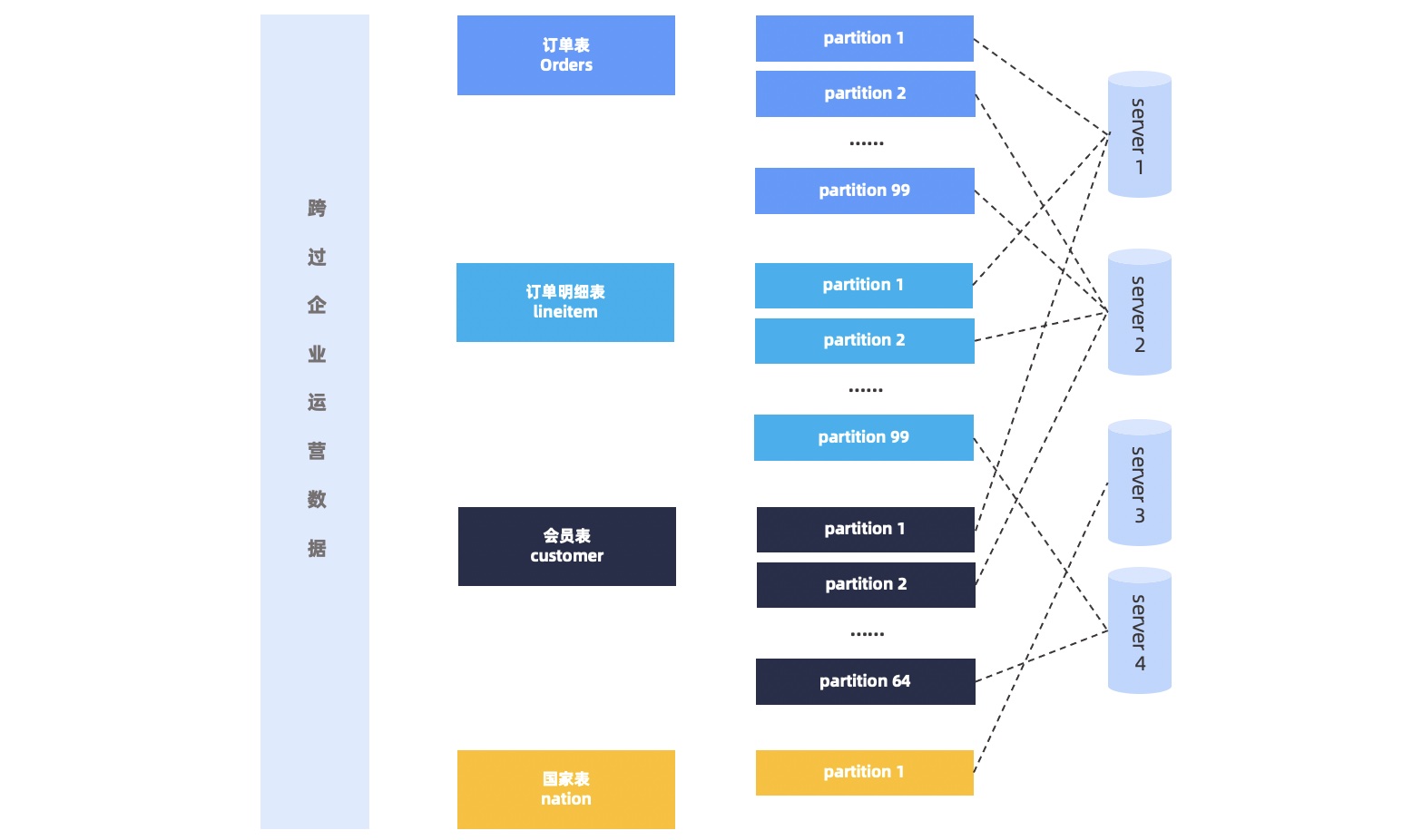
Data of a relational table is stored in partitions on various nodes of the system. Therefore, to run a cross-partition query, the execution plan must be designed to access data on multiple nodes. The optimizer of OceanBase Database automatically generates a distributed execution plan based on the query and the physical distribution of data. For distributed execution plans, partitioning improves query performance. You do not need to partition a small relational table. However, for a large relational table, you need to carefully select the partitioning key based on the requirements of the upper-layer application system. Make sure that most queries can use the partitioning key for partition pruning, which reduces the data access workload.
We recommend that you use the join key as the partitioning key for related tables and apply the same partitioning method to configure the same partitions on the same node by using table groups to reduce cross-node data interaction.
Parallel query overview
A parallel query refers to the process of executing multiple execution plans in parallel. It increases CPU utilization and the I/O throughput for executing each plan, and thus reduces the system response time to the corresponding query. The parallel query technology applies to both distributed and local execution plans.
When a single query involves access to data stored on different nodes, you need to distribute such data to the same node for computing through data redistribution. The system takes each data redistribution node as the upper and lower boundaries to vertically divide each execution plan of OceanBase Database into multiple data flow objects (DFOs). Each DFO is split into tasks of specified degrees of parallelism (DOPs) to improve execution efficiency by running tasks in parallel.
Generally, a higher DOP leads to a shorter response time to the query, but it requires more CPU, I/O, and memory resources to execute the query. For decision support systems (DSS) or data warehouses that support querying massive amounts of data, the response time is shortened.
Generally, the execution logic of a parallel query is similar to that of a distributed execution plan. After an execution plan is decomposed, each part of the plan is executed by multiple execution threads. DFOs of the execution plan and the tasks within each DFO are executed in parallel through scheduling. Parallel queries are ideal for batch update, index creation, and index maintenance operations in online transaction processing (OLTP) scenarios.
Parallel queries can effectively improve the processing performance of the system when the system has:
Sufficient I/O bandwidth
Low CPU utilization
Adequate memory resources
If the system does not have sufficient resources for parallel processing, you cannot improve the execution performance by using parallel queries or increasing the DOPs of the tasks. On the contrary, when the application system is overloaded, the operating system has to perform more scheduling tasks, such as context switching. This may degrade the performance of the operating system.
In most cases, for a DSS that queries large amounts of data, parallel execution can reduce the response time. For simple DML operations, intra-partition queries, or queries across a small number of partitions, parallel queries cannot significantly reduce the response time.
Mechanism of parallel queries and distributed queries
Data partitions of an OceanBase database are stored on various nodes that communicate with each other by using a 1 Gbit/s or 10 Gbit/s network. Generally, an observer process is deployed on each node to provide OceanBase Database services to external applications. The following figure describes the details:
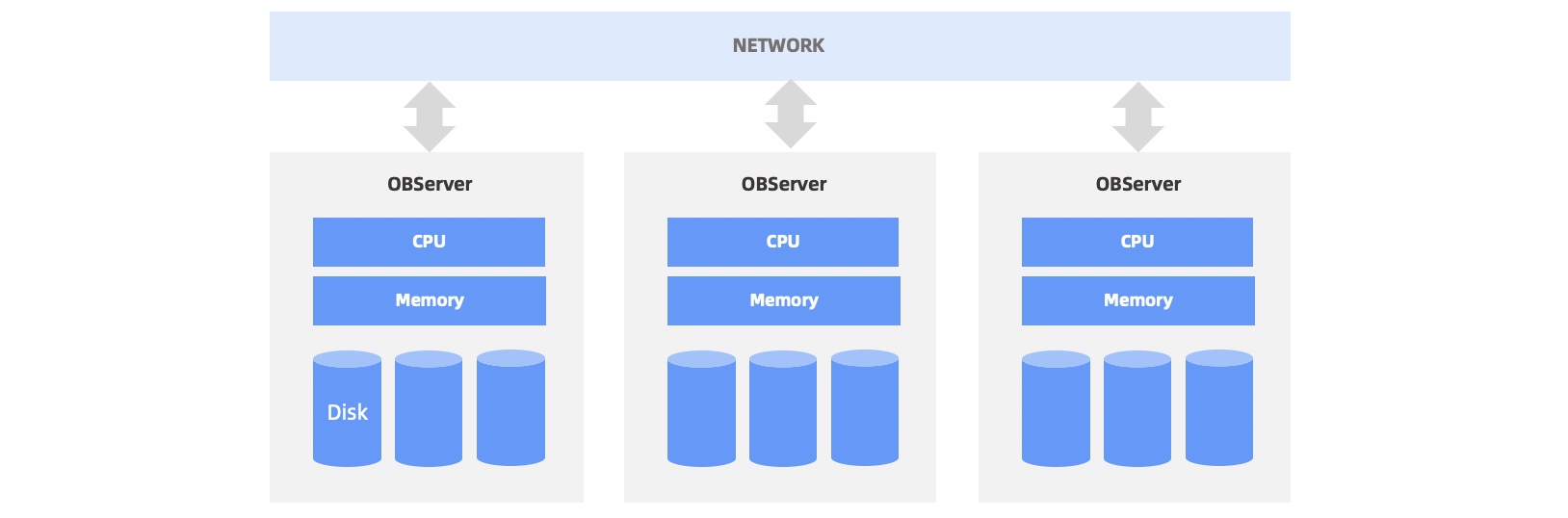
OceanBase Database evenly distributes data partitions across multiple OBServers based on the specified load balancing strategy. Therefore, a parallel query usually accesses multiple observer processes at a time. The following figure describes the details:
Parallel execution process of SQL statements
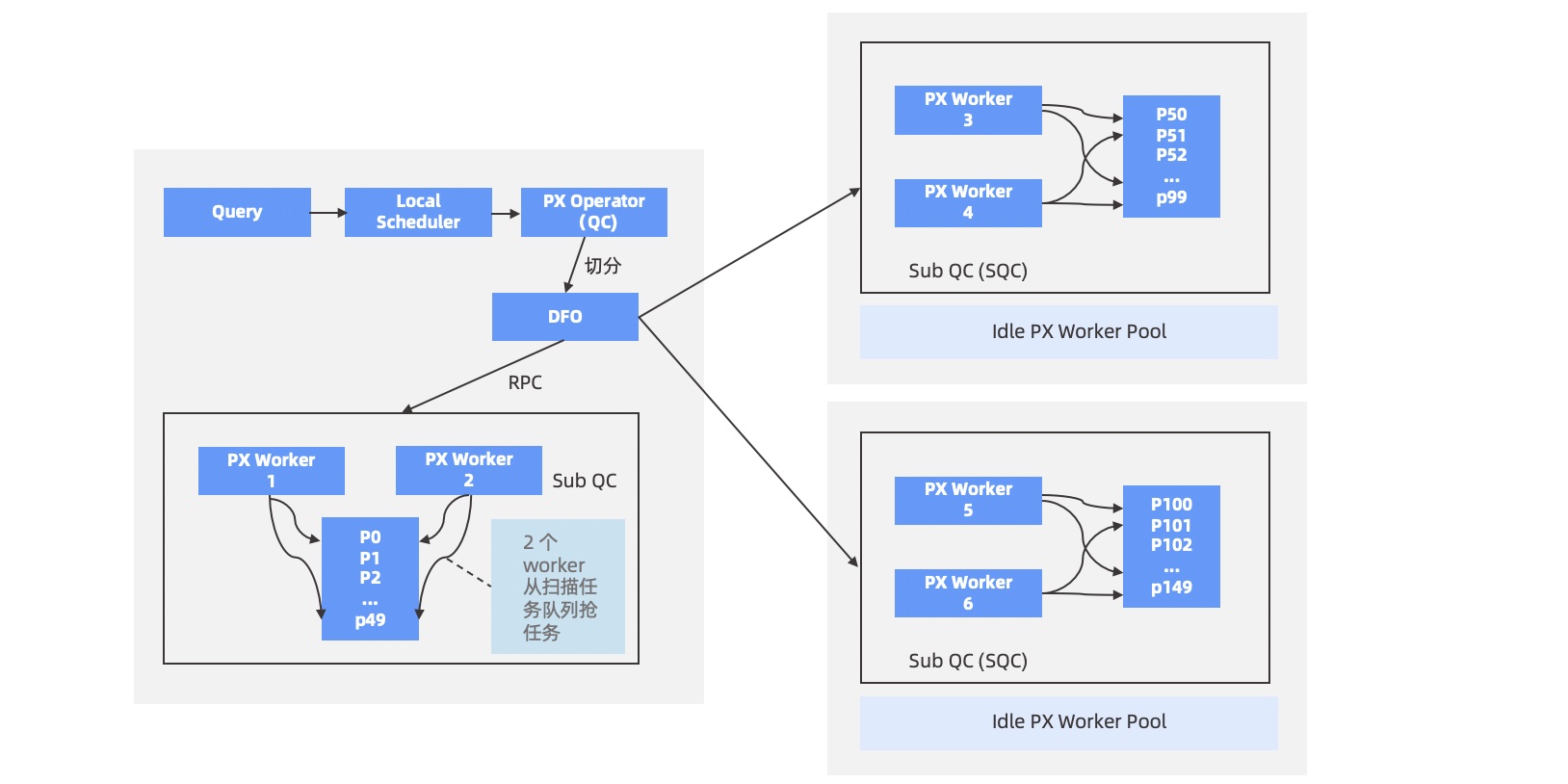
When you execute an SQL statement to query data on two or more OBServer nodes, a parallel query is run. Then, the OBServer node to which you have logged on acts as the query coordinator (QC). The process takes the following steps:
The QC reserves enough worker threads.
The QC divides the execution plan that requires parallel execution into multiple sub-plans. These sub-plans are called data flow operations (DFOs). Each DFO contains several operators that are run in sequence. For example, one DFO may involve tasks such as partition scanning, operator aggregation, and operator sending. Another DFO may involve tasks such as operator collection and aggregation.
The QC schedules DFOs to appropriate OBServer nodes in a logical order. Then, a sub-query coordinator (SQC) is temporarily launched on each OBServer node to prepare resources and context for DFO execution. After that, DFOs are executed in parallel on OBServer nodes.
After all DFOs are executed, the QC performs the rest calculations in sequence. For example, after the
COUNTalgorithm is run in parallel on each OBServer node, the QCsums upall the counting results.The QC returns the final results to the client.
In this process, the optimizer generates the parallel execution plan, and the QC executes the plan. For example, if you want to join two partitioned tables, the optimizer may generate a distributed partition-wise join plan or a distributed HASH-HASH join plan based on rules and costs. Then, the QC divides the generated plan into multiple DFOs for execution. The following figure describes the execution process implemented by the QC:
DOP and granules
The DOP specifies the number of worker threads that are used to execute a DFO. You can use the PARALLEL hint to specify the DOP. Then, the DOP is divided into several parts and assigned to the OBServer nodes on which the DFOs are executed.
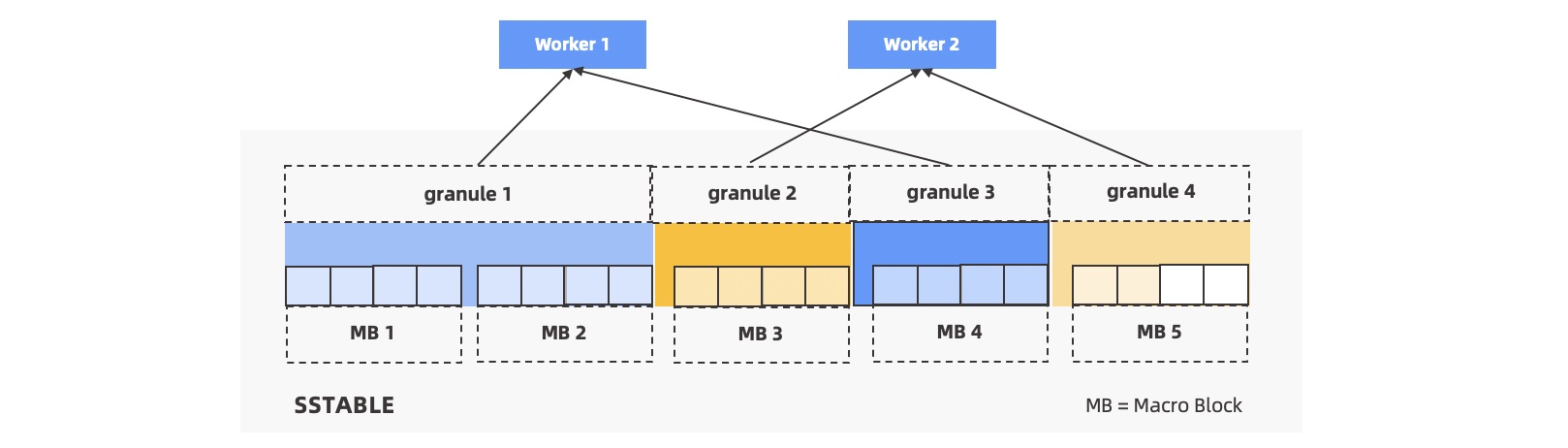
For DFOs that require partition scanning, the QC calculates the number of partitions that DFOs access on each OBServer node and assigns specific parts of DOP in proportion to OBServer nodes. For example, assume that the DOP for a query is 6, and the DFOs of the query access a total of 120 partitions. Among them, 60 partitions are on OBServer 1, 40 on OBServer 2, and 20 on OBServer 3. In this case, 3 worker threads are assigned to OBServer 1, 2 to OBServer 2, and 1 to OBServer 3. On average, each worker thread scans 20 partitions. If the DOP cannot evenly divide the total partition number, OceanBase Database adjusts the distribution of worker threads to reduce long-tail latency.
If the number of worker threads assigned to each OBServer exceeds the number of partitions on the OBServer, the worker threads automatically work in parallel on each partition. To be specific, the scan of each partition is divided into several parts by macroblock. The worker threads compete for the implementation of the parts.
The task to scan one or part of a partition is abstracted and encapsulated into the concept granule. Each scan task is referred to as a granule that scans an entire partition or only a part of the partition. The following figure describes the details:
Parallel scheduling method
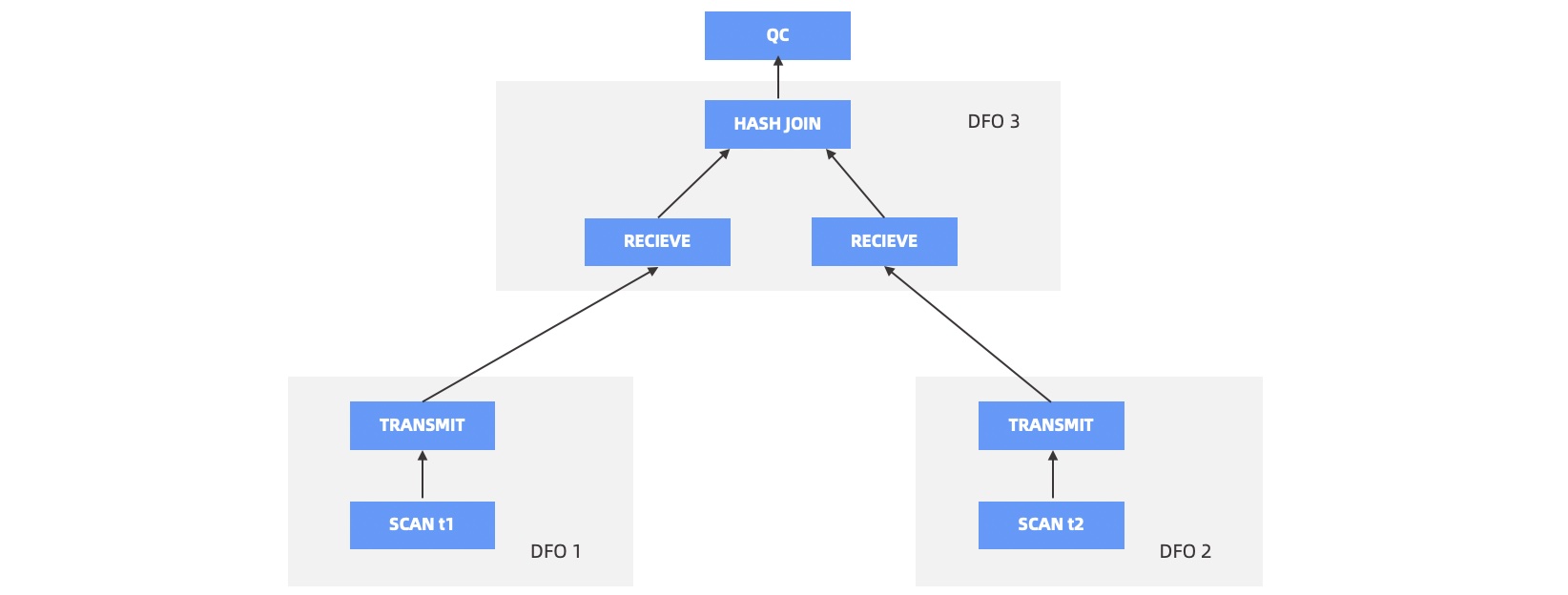
After the optimizer generates a parallel execution plan, the QC divides it into multiple DFOs. In the following figure, the HASH JOIN algorithm is used for the t1 and t2 tables. The execution plan is divided into 3 DFOs. DFO 1 and DFO 2 scan data and map the data into hash values on specific nodes. DFO 3 runs the HASH JOIN algorithm and sends the results to the QC.
Where possible, the QC uses two sets of worker threads to schedule the execution plan. The following steps describe the scheduling process:
The QC schedules DFO 1 and DFO 3. DFO 1 scans the data and sends rows that meet the requirements to DFO 3.
After DFO 3 receives all data from DFO 1, it creates a hash table by using the HASH JOIN algorithm. Then, it requests data from DFO 2. DFO 2 has not been scheduled, so DFO 3 waits to receive data. At this point, DFO 1 releases the worker threads that it used in data scanning.
When the QC recycles the worker threads released by DFO 1, it schedules DFO 2.
DFO 2 scans the data and sends rows that meet the requirements to DFO 3. After DFO 3 receives a row from DOF 2, it searches the hash table for the matching row. If the matching row exists, DFO 3 sends the result to the QC, which is responsible for sending the result to the client.
Network communication method
Assume that you have a child DFO and a parent DFO. The child DFO acts as the producer and the parent DFO as the consumer. The child DFO has M worker threads and the parent DFO has N worker threads. The data transmission between these two DFOs requires M * N network channels. The following figure describes the details:
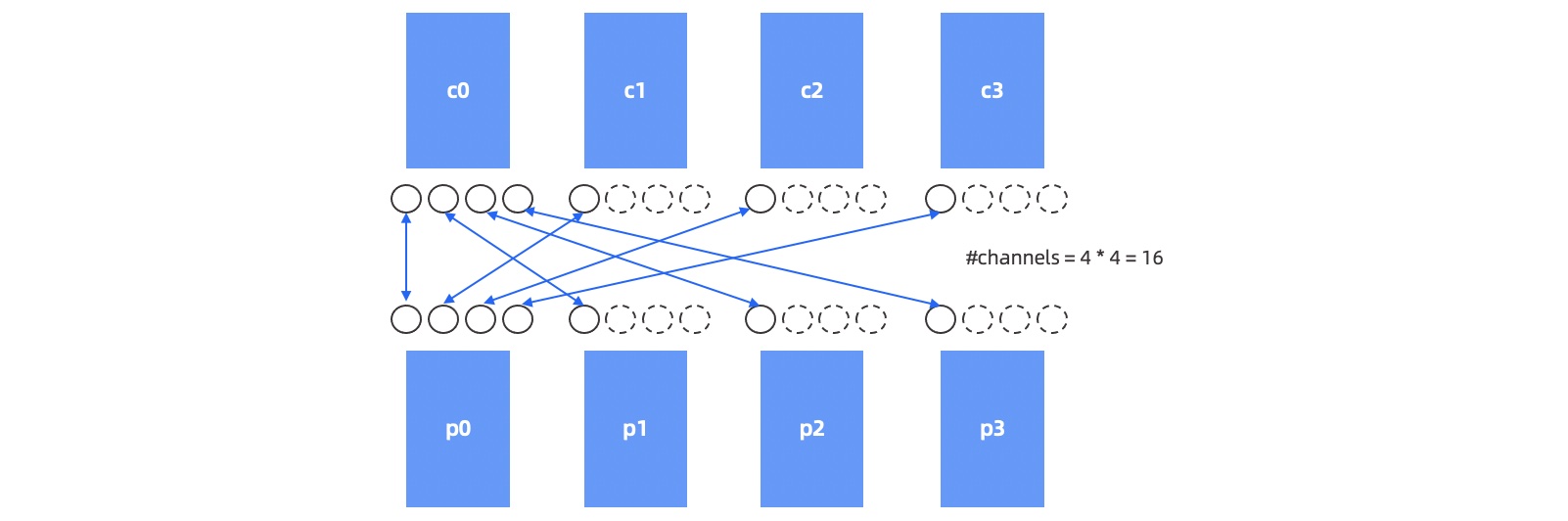
A network communication channel between two endpoints can be called a data transfer layer (DTL).
A network channel is usually built between a producer and a consumer. Earlier versions of OceanBase Database allow the producer to send unlimited amounts of data to the consumer. However, if the consumer cannot consume all the data in a short time, its memory may be used up. To prevent this, the amount of data sent to a consumer is now limited. The consumer of a channel has three slots. When the slots are occupied by data, the system requests the producer to stop sending data. When data in any of these slots is consumed and a slot becomes free, the producer is requested to continue sending data.