

















TableAPI provides an interface for operations on table model data. It also defines a set of common protocols for interactions between the client and a database server, which is known as an OBServer node. This topic describes the implementation of TableAPI in detail.
Working process of TableAPI
The working process of TableAPI involves the client, RPC framework, and an OBServer node, as shown in the following figure. These three parts are described in the following sections. 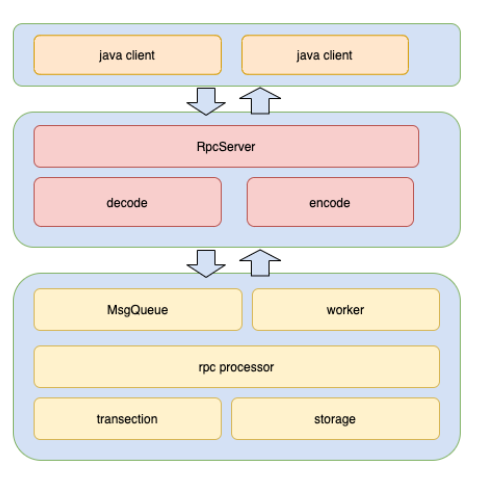
Client
OceanBase Database is a distributed database. Tables, or different partitions of a table, are stored on different servers. To read or write table data, you must first locate the table or partition to which the data belongs.
Route forwarding is not supported for TableAPI requests. Route forwarding is performed on the local OBServer nodes only. Therefore, a routing error will result in unexpected data reads or writes. Therefore, the client calculates the specific partition id based on the table name and rowkey for each operation. Then, it locates the OBServer node to process the request based on the partition id before sending the request to the OBServer node.
This means that the client also calculates routes in addition to data reads and writes.
RPC framework
TableAPI is implemented based on the RPC protocol for OceanBase Database. This protocol follows the standard request-response model.
Requests are separated from each other, and the OBServer node concurrently processes multiple requests. Multiple TCP connections can be created between a client and an OBServer node. This layer is encapsulated by using libeasy.
An RPC packet of OceanBase Database encapsulated by libeasy contains the header and data body. After a packet is transmitted to the OBServer node over the RPC protocol, the packet is parsed by the decode module to obtain the message type and data body.
OBServer node
An OBServer node processes TableAPI requests from the client by using the producer-consumer model. The maximum number of concurrent requests from the client depends on the length of the queue and the processing capacity of the OBServer node.
After the OBServer node receives a request from the client, an independent thread puts the request into a message queue. A worker thread then pulls the request from the queue and processes it.
The OBServer node arranges requests of different types, such as MySQL and RPC requests, in a priority queue. This prevents requests with higher priority from being starved due to timeout.
In addition, TableAPI uses the same transaction framework and storage engine as those for SQL statements of OceanBase Database. The storage engine consists of a two-level partitioned table and an LSM tree. The two-level partitioned table supports hash partitioning, range partitioning, and composite range-hash partitioning. The storage engine uses automatic range partitioning and partition load balancing to address partition and server hotspots, making them transparent to users.
Note
TableAPI does not support cross-partition transactions.
TableAPI operation types
Operation types supported by OceanBase Database are login, execute, batch execute, and query.
The four operation types are respectively managed by four processor classes. A process handling function is inherited and derived from each operation type to process different RPC requests:
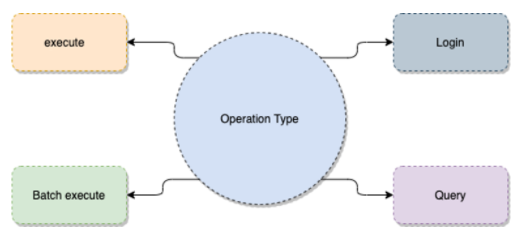
- ObTableLoginRequest: the login operation type. It requires the username and password of the OceanBase Database tenant for authentication, which is similar to SQL statements. You can call other TableAPI operations only after successful authentication.
- ObTableOperationRequest: the execute type. Operations of this type include insert, update, replace, get, increment, and append.
- ObTableBatchOperationRequest: the batch execute type that consists of multiple execute operations.
- ObTableQueryRequest: the type for streaming queries, such as the range scan for a specific primary key.
The following class diagram shows the implementation of different operation types.
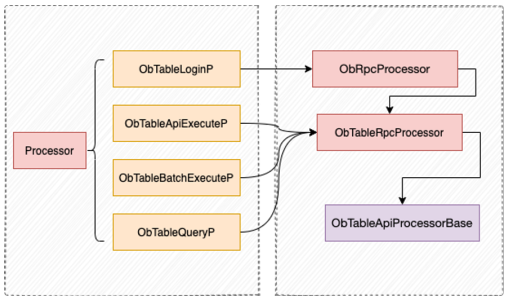
Execute
The OBServer node processes the ObTableOperationRequest operations and returns the values of errno and affected_rows to the client.
Note
In the following sections, subheadings such as insert and get are the names of operations instead of functions or APIs.
insert
You can call this operation to insert a row.
This operation returns the following results:
- If the row is inserted, the return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the insertion fails, the return value of affected_rows is 0.
- If the insertion fails because of a primary key conflict, which means the row already exists, the return value of errno is OB_ERR_PRIMARY_KEY_DUPLICATE.
- Other common values of errno are as follows:
- OB_TIMEOUT: indicates an execution timeout.
- OB_TRY_LOCK_ROW_CONFLICT: indicates a lock wait timeout.
get
You can call this operation to retrieve a row.
The target row is returned if it exists, and null is returned if the target row does not exist.
delete
You can call this operation to delete a row.
This operation returns the following results:
- If the target row is deleted, the return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the target row does not exist, the return value of errno is OB_SUCCESS, and that of affected_rows is 0.
update
You can call this operation to update a row.
This operation returns the following results:
- If the target row is updated, the return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the target row does not exist, the return value of errno is OB_SUCCESS, and that of affected_rows is 0.
insert_or_update
You can call this operation to insert or update a row.
This operation returns the following results:
- If the target row does not exist, the new row is inserted, and the return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the target row already exists, which means a primary key conflict, the row is updated. The return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the insertion encounters a unique index conflict, the target row is also updated.
replace
You can call this operation to replace a row.
This operation returns the following results:
- If the target row does not exist, the new row is inserted, and the return value of errno is OB_SUCCESS, and that of affected_rows is 1.
- If the target row already exists, which means a primary key conflict, the original row is deleted and the new row is inserted. The return value of errno is OB_SUCCESS, and that of affected_rows is greater than 1.
- If a unique index conflict takes place, conflicting rows are deleted, and rows to be replaced are inserted. The return value of errno is OB_SUCCESS, and that of affected_rows is greater than 1 because the deleted rows are counted.
Notice
The replace and insert_or_update operations can be confusing. For more information, see Differences between replace and insert_or_update.
increment
You can call this operation to atomically increment the value of the specified column by an increment value. The increment value can be negative.
This operation is supported since OceanBase Database V1.4.75. It supports columns of integer data types: TINYINT, SMALLINT, MEDIUMINT, INT, and BIGINT, and their unsigned versions. Errors are returned for columns of other data types. This operation returns the following results:
- If the calculation result overflows the value range of the column type, an error is returned.
- If the target row does not exist, the new row is inserted and the increment value is set as the initial value, which is equivalent to having an original value of 0.
- If the target row exists but the value of the specified column is NULL, the increment value is set as the initial value, which is equivalent to having an original value of 0.
append
You can call this operation to atomically append a string to the value of the specified column.
This operation is supported since OceanBase Database V1.4.75. It supports columns of VARCHAR and VARBINARY data types. Errors are returned for columns of other data types. This operation returns the following results:
- If the calculation result overflows the length of the column, an error is returned.
- If the target row does not exist, the new row is inserted and the increment value is set as the initial value, which is equivalent to having an original value of an empty string.
- If the target row exists but the specified column value is NULL, the increment value is set as the initial value, which is equivalent to having an original value of an empty string.
Batch execute
A batch execute operation includes a collection of execute operations. For more information about a specific execute operation, see Execute.
To accelerate the batch operation, the OBServer node is optimized for batch processing read-only transactions. Therefore, it demonstrates better performance in batch operations of read-only requests than those of read/write requests.
Query
TableAPI supports range scan based on the primary key or the prefix of the primary key. When the primary key is not specified, TableAPI also supports range scan based on the index or index prefix.
You can call query operations to scan multiple specified segments. At present, the OBServer node can return a result set of at most 64 MB of data (adjustable) in the RPC message interaction process of a Query.
For more information about how to set various query conditions, see Introduction to the client and instructions for use.
Supported value types
TableAPI is compatible with all value types that are supported by OceanBase SQL statements, including:
- NULL
- Tiny Int and Unsigned Tiny Int
- Small Int and Unsigned Small Int
- Medium Int and Unsigned Medium Int
- Int and Unsigned Int
- Big Int and Unsigned Big Int
- Float and Unsigned Float
- Double and Unsigned Double
- Decimal and Unsigned Decimal
- Datetime and Timestamp
- Date, Time, and Year
- Varchar and Char (the utf8mb4_general_ci and utf8mb4_bin collations are supported).
- Varbinary and Binary
- Tiny Text, Text, Medium Text, and Long Text
- Tiny Blob, Blob, Medium Blob, and Long Blob
- Bit