

















The cache design of OceanBase Database is different from that of Oracle and MySQL. The storage engine of OceanBase Database is developed based on the log-structured merge-tree (LSM tree) architecture. All modifications are written only to the MemTable, and the SSTable is read-only. This means that the caches of OceanBase Database are read-only, and OceanBase Database does not involve dirty page flushing. Compared with traditional database services, the cache logic of OceanBase Database is simpler. However, OceanBase Database encodes and compresses the data stored in the SSTable, which means that the size of the data to be stored is variable, not fixed. This makes cache memory management in OceanBase Database more complex than that in traditional database services. OceanBase Database is a distributed database system oriented to multiple tenants. In addition to memory eviction, which is required in traditional database services, OceanBase Database also needs to isolate the memory of multiple tenants inside the caches.
Similar to Oracle and MySQL, OceanBase Database has different cache types, including the block cache (similar to the buffer cache in Oracle and MySQL) for caching SSTable data, row cache for caching data rows, log cache for caching REDO logs, location cache for caching positions of data replicas, schema cache for caching table schemas, and Bloom filter cache for caching Bloom filters of static data and quickly filtering out empty queries. OceanBase Database adopts a unified cache management framework. Different types of caches of different tenants are managed by the framework in a unified manner. OceanBase Database sets different priorities for different cache types. Caches occupy memory space in a reciprocal way based on priorities and the data access frequency. OceanBase Database also specifies the upper limit and lower limit of the memory space that can be used by each tenant. Caches of different tenants occupy memory spaces based on the memory upper limits of their tenants and the overall memory upper limit of the server.
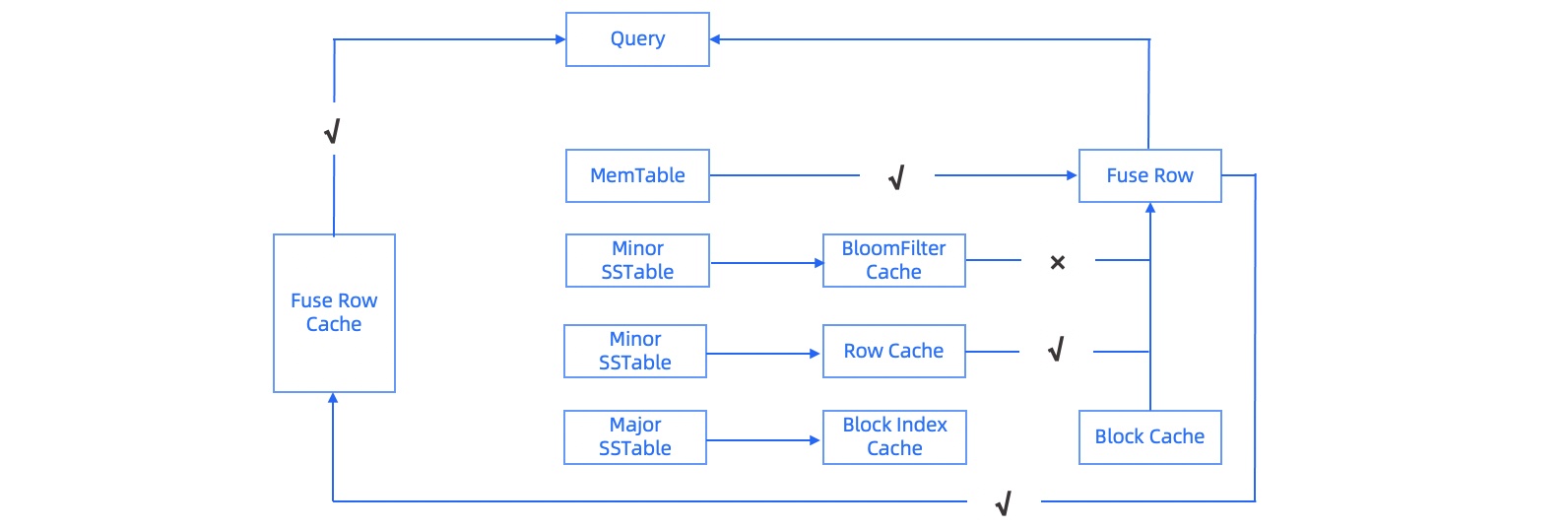
The table get operator in the preceding figure shows the various cache types in OceanBase Database that serve the query process.
BloomFilter Cache
In OceanBase Database, Bloom filters are created based on the actual empty query rate on macroblocks. If the number of empty queries on a macroblock exceeds the specified threshold, a Bloom filter is created and placed into the cache.
Row cache
OceanBase Database caches data rows for each SSTable. During a Get or MultiGet query, the queried data rows can be placed in the row cache to avoid repeated searches for the rows by using the binary location method.
Block index cache
OceanBase Database caches the indexes of microblocks. While each SSTable is built on macroblocks, the granularity of 2 MB is coarse for user queries. Therefore, the required microblocks need to be located in a macroblock based on the query range. Microblock indexes describe the range of all microblocks in a macroblock. When the microblocks of a macroblock need to be accessed, microblock indexes need to be loaded in advance. Microblock indexes are small in size because prefix compression is performed. In addition, microblock indexes have a high priority in OceanBase Database. This results in a high hit rate.
Block cache
It is similar to the buffer cache in Oracle and is used for specific data microblocks. Each microblock is decompressed before it is loaded to the block cache. Therefore, each cache has a variable length.
Fuse row cache
In the LSM tree architecture, the modifications of the same row may be stored in different SSTables. To optimize storage space usage, OceanBase Database stores only incremental data for each update. Therefore, the query results of various SSTables need to be fused. Before a new update is triggered, the existing fusion result is always valid for queries. OceanBase Database provides a fuse row cache for fusion results to facilitate hotspot row queries.
In addition to query-related multi-level caching, OceanBase Database also supports other cache types. The following list provides some examples:
Partition location cache: the location information of partitions, which is used to facilitate query routing.
Schema cache: the metadata of tables, which is used to generate execution plans and subsequent queries.
Clog cache: clog data, which is used to accelerate Paxos log pulling under specific circumstances.
...
To support the preceding cache types, OceanBase Database needs to handle variable-length data. The underlying cache framework of OceanBase Database divides the memory into multiple memory blocks with a total size of 2 MB. In this way, memory space is allocated and released based on the unit of 2 MB. Variable-length data is packed into the memory blocks. For quick data location, pointers that point to specific data are stored in HashMap. The following figure shows the overall structure.
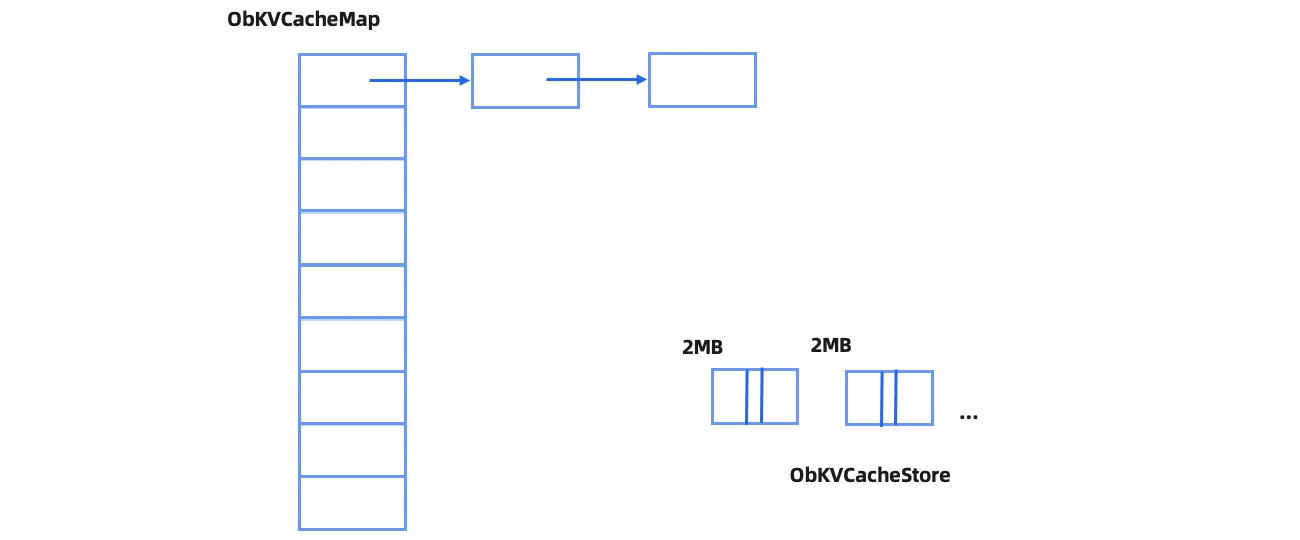
Cache memory is evicted based on the unit of 2 MB. OceanBase Database generates a score for each memory block based on the access frequency of the elements on the memory block. A memory block with a higher access frequency has a higher score. A backend thread is assigned to periodically sort all memory blocks by score and evict those with low scores. For a memory block that has a low score but stores hotspot data, OceanBase Database moves the hotspot data from the cold block to a hot block to prevent the hotspot data from being evicted. In terms of data structures, OceanBase Database does not maintain line-replaceable unit (LRU) linked lists as that in Oracle and MySQL. Therefore, cache data access in OceanBase Database requires no locks, except for bucket locks on HashMap. OceanBase Database is more suitable for highly concurrent access to hotspot data. During the eviction process, OceanBase Database considers the memory upper and lower limits of tenants and controls the cache memory usage of tenants.