

















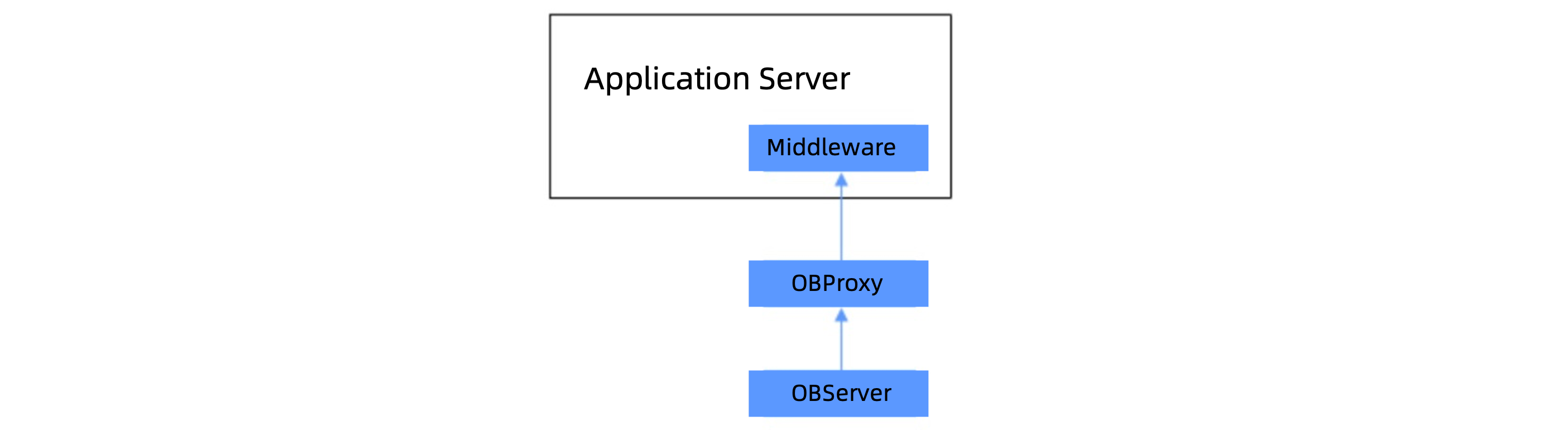
As described in the "High availability" section, data is processed through the following link: application server <-> OceanBase Database Proxy (ODP) <-> OBServer node. Specifically, an application server connects and sends requests to ODP by calling database drivers. Then, ODP forwards the requests to the most appropriate OBServer nodes of OceanBase Database, which stores user data in multiple partitions and replicas across OBServer nodes in its distributed architecture. OBServer nodes execute the requests and return the execution results to the user. OBServer nodes also support request forwarding. If a request cannot be executed on the current OBServer node, it is forwarded to the appropriate OBServer node.
In the case of an end-to-end performance issue, such as long response time (RT) monitored on the application server, you need to first find the component that has caused the issue on the database access link, and then troubleshoot the component.
The following two troubleshooting methods are often used:
Drill-down method
Check in sequence the time taken by each component on the data access link to call the downstream component, and identify the components (also known as "time-consuming hotspots) that obviously take more time to call their downstream components. This recursive method allows you to follow the clues and drill down to the root cause step by step.
Targeted troubleshooting
Focus on the components with most exceptions based on historical data, check their health by monitoring their core metrics specified in the Service Level Agreement (SLA), and then perform further troubleshooting on abnormal components. This method is based on the principle of exclusion, and allows you to find the root cause by gradually excluding the suspicious components.

The preceding figure shows a simplified database access link. Note that the network between two components should also be regarded as a component. If you suspect that a network exception is possible, you need to troubleshoot switches on the network link. Considering the deployment mode of ODP, we recommend that you pay close attention to accesses that involve long access links, such as cross-VPC and cross-cloud accesses.
The aforementioned two troubleshooting methods have their respective strong points. You can choose the more efficient one based on the tools at hand and experience.
For example, if you have deployed a new hybrid cloud system and migrated some business modules from a self-managed IDC to the public cloud for the first time, we recommend that you use the drill-down method for troubleshooting because the access involves cross-cloud links.
If you have just changed specific components on a mature business link for certain purposes, such as a big sales event or ODP upgrade, we recommend that you use the targeted troubleshooting method.
The preceding examples describe how to choose the troubleshooting method based on the scenario. However, if you are an experienced engineer, you can also locate the exact bottleneck component based on the error message.
The preceding figure shows a typical error reporting stack that consists of the following three layers: OBServer node layer, ODP layer, and application layer. Usually, an application uses data middleware to manage database connection tasks, such as access authentication, connection warm-up, and connection pooling. The data middleware is integrated with the application as a package, and the two generate operation logs separately. Therefore, applications and data middleware are hereby collectively referred to as the application layer.
In OceanBase Database, errors of components at a layer are not only recorded in the operation logs of the layer, but also thrown to the upper layer and recorded in the operation logs of components at the upper layer. Therefore, when you receive an error message for a layer, you must determine the layer from which the error is thrown. If the error is thrown from a component at the current layer, you can start troubleshooting from the current layer. If the error is thrown from a component at a lower layer, you can perform troubleshooting at the target layer.
The following sections describe possible errors of each layer. Note that errors reported at a layer are not only recorded in the operation logs of the layer, but also thrown to the upper layer and recorded in the operation logs of the upper layer.
Application errors
Database connection pool exhausted
This error is one of the most likely errors in an application system. If the database connection pool of the application system is exhausted, new requests for building a connection will fail. Generally, the application code starts a transaction to access the database. In addition to database access, other downstream systems, such as downstream applications and caches, are also called during the transaction. When the transaction starts, a connection is obtained from the connection pool. When the transaction ends, the connection is returned to the connection pool. A connection pool is exhausted usually due to prolonged transaction execution. Possible causes of prolonged transaction execution include long RT of database requests, time-consuming access to downstream systems, and exceptions of the application system.
If it takes a long time to call a downstream system by using a remote process call (RPC), the overall execution duration of a transaction can be increased, even when the database access is normal.
If an application system is stuck due to a full garbage collection (GC) or CPU exhaustion, the overall execution duration of a transaction can also be increased, even when the database access is normal.
Database connection failed
This error indicates that the application system failed to connect to an OBServer node. Possible causes include: overloading of the database system due to a large number of requests, exceptions of the application system, such as a full GC, an NIC error of the application server, and incorrect database configuration at the application layer, and a network exception between the application server and the OBServer node.
Lock contention
A lock contention may occur when the application system tries to lock a database object. Generally, an application system controls concurrent access to the same object by adding a pessimistic or optimistic lock on the object. In addition to a large RT value of the database system that results in serious timeouts and retries, a lock contention is likely caused by exceptions of the application system, such as a large number of concurrent operations on the same object due to an error of the scheduling system or a hacker attack.
ODP errors
ERROR 1317 (70100): Query execution was interruptedThis error indicates that the client cancels the query. This is often because that a response is not returned for an SQL query sent by the client within the expected timeout period, or that the user initiates the
Kill Queryaction by pressingCtrl + C. If this error is frequently reported in a production environment, the SQL query execution exceeds the timeout value specified for the client. You need to troubleshoot each component on the link from the client to the OBServer node.
OBServer node errors
ERROR 4012 (HY000): Timeout, query has reached the maximum query timeoutThis error indicates that the processing duration of an SQL query on the OBServer node exceeds the value specified for the
ob_query_timeoutvariable of the server. You can check the OBServer node for internal exceptions.Here,
ob_query_timeoutspecifies the maximum execution time allowed for an SQL query in microseconds. For more information about this variable, see ob_query_timeout.
Notice
The aforementioned error messages that allow experienced engineers to locate the exact components may vary with the version of each component. We recommend that you build a specific troubleshooting methodology for each version.