







OceanBase Community: 2025 in Review & What's Coming in 2026




"Every step forward this community takes is because of the developers and contributors who show up."
— Feng Zhongyan, GM of OceanBase Open Source Ecosystem, at the OceanBase Community Carnival on January 31.
Thanks for Being Part of the Journey
Since 2023, the Community Carnival has been the main get-together for OceanBase contributors and friends. This year we did it in Shanghai under the theme "You're Always with Me." Feng Zhongyan walked us through where the community came from and where we want it to go by 2026: a more open, engaging, and developer-first place to learn and build.

What mattered most in 2025 wasn't just metrics—it was how people started connecting:
- Forums: More devs are pairing up; new questions often get answers in seconds. Deeper technical threads are turning into new ideas and projects.
- Blogging: Nearly 100 new bloggers shared real-world experience and how they use OceanBase, building a practical, community-driven knowledge base.
- City Exchange Events: Community members ran local meetups and shared experience through livestreams and training.
Collective Outcomes and an Open Invitation
Those outcomes are possible only because of the time and effort every participant has put in. Every kind of contribution—questions, answers, posts, events—adds to our shared knowledge base and turns what could be solitary learning into something we explore and inspire each other in.
Building on that same sense of connection, we set up a special segment at the Carnival—Tech Open Mic—and held a small, warm ceremony to say thank you and present honors. That wasn't only about gratitude; it was a celebration of what every participant has achieved and contributed, and at the same time an open invitation to all developers to build with us.
2026: Building Together
In 2026, we'll work with the community on two fronts: taking OceanBase operation and maintenance to the next level, and building a truly usable learning-and-experimentation platform for AI developers around seekdb. Here, growth isn't a task to complete—it's a journey of exploration and co-creation that we want everyone to enjoy.
The community will keep database at its center and will actively embrace the AI developer ecosystem. We want to move forward with you from here: make technical learning engaging, make open source contribution feel natural, and help every good idea find partners so it can be realized together.
Community Carnival: Open Source Philosophy & 2026 Roadmap
Past Carnivals were heavily database-client focused. This year we added AI Coding, an open mic for AI open-source projects, and an open-source community market. Alongside database users, we also welcomed partners from the open-source AI world and developers who are actively exploring AI. That's why our slogan—Open Source, Open Ecosystem, Win-Win—now carries new meaning and new momentum.
For the community, that means clearer paths to contribute, more ways to learn with AI, and more chances to connect with developers worldwide. Here's how we're steering that in 2026:
- Ecosystem collaboration — Work with more partners and the AI ecosystem to build solutions that matter.
- Embrace AI — Train and support developers and explore ways to support AI workloads on top of OceanBase.
- Go global — Move beyond China and discover new use cases with developers worldwide.
OceanBase is also chosen by many enterprises for its adaptability—over 1,500 technology vendors have integrated with it.
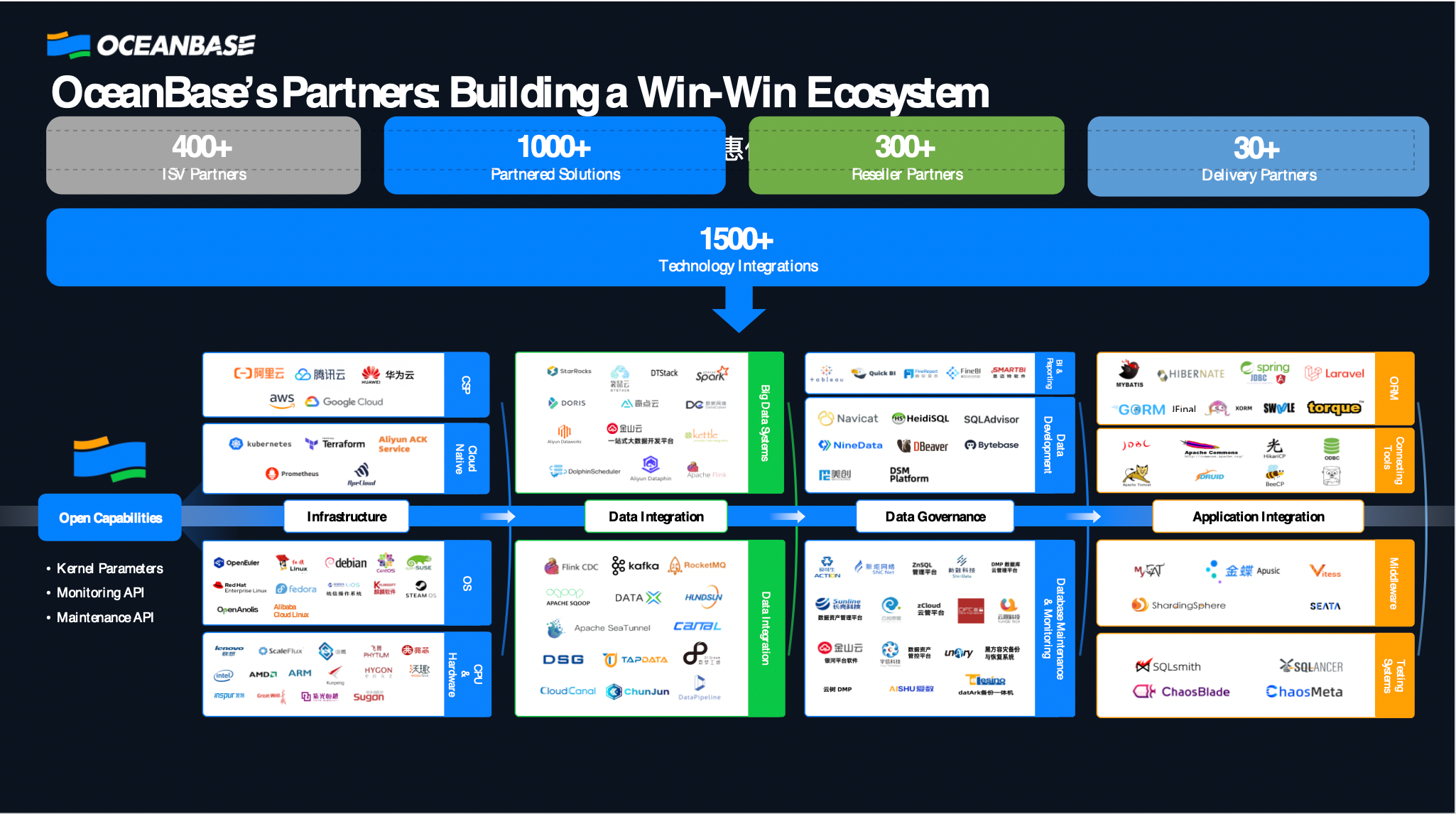
For developers, a few concrete updates:
- seekdb development is moving to GitHub — All seekdb development will happen there.
- Good-first-issue style contributions — We've tagged a set of issues that are easy to get started with; we want to work with more contributors.
- Data × AI hands-on training — We're launching a practical course and want your feedback and participation.
We'll also engage more technical communities in 2026 and regularly invite developers to OceanBase (visits, office hours, etc.).
Why seekdb? Why a Lightweight AI-Native Database?
In the AI era, two trends stand out: data is growing and converging, and models are being embedded—including into the data layer—to get more value from data. That raises real questions:
- How do we call AI from SQL?
- How do we make AI understand our data?
We're exploring use cases like coding assistants, travel agents, and intelligent customer service with partners. As we go deeper, data needs aren't just scalars or vectors but mixed types, which touches interfaces, computation, and storage.
For users, this changes how they use the system and opens up new use cases and ways to get value from their data. For companies, it's about lower cost and better efficiency.
We're all early. But looking at Oracle, Databricks, Snowflake, and MongoDB, there's a shared direction: embedding model capabilities into the data foundation—whether in the kernel, SDKs, or tight integration with upper layers (e.g., memory systems in context engineering).
Our 2026 plan centers on seekdb and PowerMem.
seekdb
We recently shipped native macOS support—something OceanBase has wanted for a long time. Why did it take so long? Because OceanBase takes very low-level control of the hardware: it manages memory, I/O, buffers, and even CPU, NUMA, and cgroups itself to squeeze out performance. That approach has always come at the cost of system compatibility, so supporting Mac natively wasn't feasible until we had seekdb (GitHub). We hope you give it a try and share your feedback.
Alongside native macOS support, we're excited to highlight another capability: TableFork. Here are a few common use cases:
- AI coding: Quickly fork a repo/table when working with an AI coding assistant.
- RAG: Multiple versions of the same table for different users or content.
- Rollback: If a DDL change breaks a table in production, you can roll back at the table or database level.
We're also working on end-to-end stress testing, hybrid search, and better retrieval.
PowerMem
PowerMem (GitHub) is a lightweight layer for memory in context engineering. For AI apps to be useful, they need memory: who you are, what you said, what you prefer, and the ability to recall it when it matters.
PowerMem is built for that. It doesn't just store chat logs—it extracts, updates, and deduplicates so the memory store stays accurate and usable. We use the Ebbinghaus forgetting curve so important information is retained longer and less relevant details decay, keeping the system from getting noisy over time.
For developers:
- Access: Python SDK, MCP, HTTP API Server.
- Multi-Agent: Each agent has its own memory space, with sharing and permissions.
- Retrieval: Hybrid of vectors, full-text, and images, with multi-path recall for more stable and accurate results.
- User profiles and multi-modal memory make "long-term memory" something you can actually ship in products.
We're following a clear roadmap: first we'll strengthen capability, stability, and observability; then we'll add a visual control panel and a closed-loop context engineering system. The aim is for every AI application to have memory that is reliable, manageable, and able to evolve over time.
Recognition & What's Next
We announced 5 Community Ambassadors for 2026 and recognized 31 Moderators from 2025. Our CTO, Rizhao, presented the awards at the Carnival.

In 2026, we'll stay committed to open source, expand globally, and work even more closely with the broader community. Our goal is to accelerate innovation in Data + AI and grow the ecosystem—and we'd love you to be part of it.
If you'd like to contribute, learn, or just connect, you can always find us on GitHub—and remember, you're always with us.


