







What is OceanBase's Multi-Model Capability, and Why Should You Try It?




In today's diverse business environment, different industries have different demands for database systems. For example, financial risk management requires efficient transaction processing (TP) and analytical processing (AP) databases; the video game industry is more concerned with the flexibility and performance of document databases; and businesses based on location services have a particularly strong demand for GIS spatial databases. The complexity of business scenarios leads to many challenges in database operation and maintenance, including backup and recovery, live network inspection, security and regulatory compliance, troubleshooting, maintenance and upgrades, and performance tuning.
Traditional single-model database systems are difficult to fully meet the diverse business requirements. In the maintenance process, the diverse demands of multiple database systems not only increase the workload of database administrators (DBAs), but also place higher demands on their skills. As a company introduces more and more database systems, the complexity of maintenance increases exponentially.
In this situation, the multi-model capability of the database becomes particularly important, as it can effectively manage and process different types of data, improve efficiency, and simplify the technology stack, thus meeting complex and changing business requirements.
This article will introduce the multi-model integration functionality of OceanBase and its application scenarios.
OBKV: the core component of OceanBase's multi-model capability
OBKV is the core component of OceanBase's multi-model integration capability, designed to support low-cost storage of massive structured and semi-structured data, and to ensure outstanding access performance through simple interfaces. In terms of technical implementation, OBKV does not need to interact with the SQL layer. Instead, it can directly support various multi-model KV types based on OceanBase's distributed storage. Currently, it supports three product forms: OBKV-HBase, OBKV-Redis, and OBKV-Table, which are compatible with HBase APIs, open source Redis protocol, and table-based data respectively. Between the distributed storage engine and model layer, OBKV introduces the TableAPI server framework, which provides packaged storage and transaction invocation capabilities for the model layer.

In OceanBase's architecture, the SQL engine and the multi-model KV are built on top of the distributed storage engine. Many users may wonder why data types such as GIS, JSON, and XML are placed in the SQL engine rather than in the multi-model KV. This is primarily for business considerations. Most of the GIS services are using the PostGIS database. Oracle's XML database is powerful and has been widely used. JSON, as a standard format for document types, is supported comprehensively by various mainstream relational databases. From a business perspective, these users are already accustomed to SQL. Therefore, OceanBase incorporates these multi-model data types into the SQL engine in order to better meet user habits and business requirements.

In addition, HBase is widely used in big data analysis scenarios and Redis in caching or rich data type scenarios. The open-source ecosystems of HBase and Redis are very active. From a business perspective, users prefer to access these data engines with native APIs. Therefore, OceanBase's multi-model database is divided into two parts based on user behavior: the SQL engine supporting JSON, GIS, XML, and vector data types in the future, and the multi-model KV aligning with the user habits of mainstream NoSQL databases.
The multi-model KV and the SQL engine operate in parallel. The multi-model KV interacts directly with the distributed storage engine without going through the SQL layer. As a result, in simple KV scenarios, the multi-model KV offers approximately 30% higher performance than the SQL interface. The multi-model KV and SQL engine do not interfere with each other. For normal business scenarios, such as replacing HBase, we recommend that users employ a dedicated HBase service within an OceanBase cluster.
In addition to the data engine itself, the ecosystem tools are also crucial. Alongside the introduction of the data engine, OceanBase has introduced a series of monitoring and maintenance tools. Through an integrated system, OceanBase allows for the use of a single set of tools for both SQL and KV maintenance. DBAs only need to manage a single engine, while the service departments can choose the appropriate model according to their requirements, thereby achieving greater efficiency and flexibility.
Why does multi-model integration matter?
Many databases in the industry offer multi-model functionality as a set of solutions, wherein each engine is separate, meaning each model needs an independent database and can not interact with each other.
OceanBase, however, takes a different approach. In OceanBase, the SQL engine and the multi-model KV share the same distributed storage engine, which inherit OceanBase’s basic capabilities of high performance, transaction processing, distributed architecture, multi-tenant, and high availability. Due to this architecture, users no longer need to worry about the ecosystem and evolution of every single model. It can achieve multi-model integrated computation, multi-model integrated storage, and multi-model integrated operation, and the benefits brought by the evolution of the underlying engine will be multiplied.
What can you do with the multi-model integrated computation?
Finding the optimal execution path
Imagine a scenario of location-based services where a query needs to find the top 10 positive comments of the nearest tea shop that is rated above 4 stars. This requirement involves multiple aspects:
Firstly, filter tea shops with a rating score exceeding 4 stars. It is a typical process for structured relational databases, using "rating above 4 stars" as a filter condition.
Secondly, find the closest tea shop. It is a typical spatial query, which spatial databases handle well.
Third, find the top 10 positive comments, which are generally textual data, making it difficult to determine if the content is positive. Therefore, semantic extraction on the textual content and vector retrieval would be required to make an accurate judgment.
How to combine these queries and choose the optimal execution path? Through the multi-model integrated engine and optimizer, OceanBase can select the best execution path, thus providing users with better query results, response time, and resource consumption.
Seamless Transformation & Computation of Heterogeneous Data
Integrated computation can also enable seamless transformation and computation of heterogeneous data. With the increase of semi-structured and structured data. Relational data needs to be queried with JSON and GIS data seamlessly. Regular relational engines apply SQL queries and optimizations that cater to the relational model. However, when semi-structured and unstructured data are introduced, how to leverage these types of data effectively and achieve optimal results?
Here are some examples:
Example 1: Underlying tables are both structured and semi-structured. Take JSON as an example, document databases feature models with nested structures and are at a disadvantage in computation when compared to relational databases. With multi-model integration, OceanBase provides model conversion capabilities, such as JSON Table and XML Table. It can transform the JSON into relational two-dimensional tables, and then execute calculations with other relational data.
Example 2: Underlying tables are structured, but the services need semi-structured data. A typical scenario lies in video game services, where user data often comprises nested JSON data. For instance, players may have game item attributes and personal information attributes, and game items can further be divided into different categories. Although storing JSON directly in a relational database is a good approach, it comes with a drawback: JSON is self-explanatory, and all content referenced by the JSON object needs to be fully stored within the JSON object, leading to redundant storage. Consequently, when designing table structures, it is common to extract common portions to minimize redundancy between multiple tables. In this scenario, OceanBase supports converting relational tables to semi-structured data. For example, conducting relational calculations using the unified execution engine, and then aggregating the results using the respective model's aggregation capabilities (such as XML or JSON AGG functions) to return the data to the services.

What can you do with the multi-model integrated storage?
In semi-structured data, encoding can be difficult because its level of structuration is not high, and most databases do not compress and encode JSON data. They simply store it in a text or binary format. OceanBase can address this issue and, furthermore, its encoding capabilities have a notable cost advantage compared to databases such as MySQL.

For example, consider the display of a user's trajectory on a map application. At every specific time interval, a point is collected and further forms the trajectory, which is essentially an array of doubles representing latitude and longitude coordinates. While a database can easily compress individual double-type data, compressing semi-structured data like trajectories is comparatively more challenging. However, by decomposing the trajectory array into two double arrays, OceanBase can leverage its existing double encoding technology, significantly improving the compression ratio of trajectory data.
Similarly, we know that JSON does not require a predefined schema, and it is typically stored in a text or binary format in databases. Its compression ratio is generally lower compared to regular data types. However, in most cases, the structure of JSON data in the same column is usually quite similar. Leveraging this feature, the database can extract common parts, which include a structured portion and a semi-structured portion, maximizing the encoding capabilities of the storage engine. In this way, even if there is semi-structured data in the database, it can also achieve storage costs similar to those of relational databases.
Two NoSQL Models of OBKV
Currently, OBKV supports two NoSQL models: OBKV-HBase and OBKV-Redis.
OBKV-HBase
Pros and Cons of HBase in Big Data Processing
HBase is a popular distributed KV database, known for its excellent horizontal scalability and high performance in simple read and write. It can support distributed storage and processing of massive data. In big data processing scenarios, HBase is widely used, such as for storing massive amounts of raw business logs, messages, and data, importing batch data from offline data warehouses for rapid queries, and serving as storage for dimension tables in real-time data warehouses, providing extreme point and range query capabilities. In such scenarios, users typically use HBase as a KV database and focus on basic KV operations like write, query, and storage.HBase, as a KV database, primarily provides simple data access capabilities and does not support secondary indexing and data calculations. To address these limitations, the open-source community has introduced Phoenix, which builds common SQL and secondary indexing capabilities on top of HBase, enhancing HBase's ability to handle structured data.
OBSQL vs. OBKV-HBase
For standard HBase scenarios, OceanBase's OBKV-HBase can easily meet the requirements and provide higher performance. For structured data scenarios, OBSQL can be used to achieve higher compression rates and greater flexibility.
| Schema | API | Flexibility | Performance | Compression Rate | Replaced product | |
|---|---|---|---|---|---|---|
| OBSQL | Structured data | Standard SQL | Index & Flexible operators | OceanBase TP baseline performance | Several times higher than open source HBase | Apache Phoenix |
| OBKV-HBase | Schemaless | Compatible with HBase interfaces | Simple Get/Put, etc. | +30% OceanBase TP baseline performance 1x Open source HBase Put 4x Open source HBase Get | +25% Open source HBase | Open source HBase |
OBKV-Redis
A Persistent database compatible with the open source Redis protocol
Redis excels in scenarios demanding extreme RT and high throughput. For example, in cash flow services such as advertising and video games, the access latency directly affects revenue when there are multiple interactions with Redis. However, some users comment that in scenarios where they combine RDS and Redis, the costs are typically high, and the service architecture is complex. It is because services need to be aware not only of Redis but also of RDS, and ensure consistency between them. Furthermore, in most scenarios, a latency of 200-500 microseconds is not necessary.
We conducted a series of tests, as shown in the figure below. By keeping the latency of OceanBase within 1 millisecond and observing the throughput of the database under different data volumes, the final results were still satisfactory.
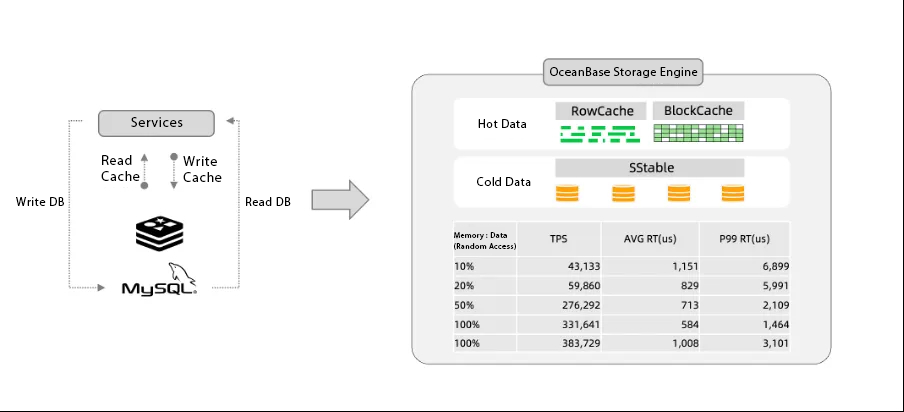
In addition, in scenarios involving hot and cold data, Redis poses certain challenging issues. For instance, in video game scenarios, while there are numerous players in the system, only a few have high engagements, with others barely logging in. It results in a clear separation between hot and cold data. Storing all data in memory would lead to high costs.
OceanBase addresses the problem of consistency between databases and caching, allowing users to use Redis as a database. Additionally, OceanBase reduces costs for 80% of "RDS + Redis" architecture scenarios by distinguishing between hot and cold data, and storing hot data in cache and cold data on disk.
Summary
OceanBase's multi-model capability allows users to manage and process different types of data using just a single database and a single engine. OceanBase natively supports various data models, including SQL and NoSQL, providing users with the convenience of choosing the appropriate data model according to their needs.

