







OceanBase 4.3: What's New in the Latest Release?




In early 2023, OceanBase 4.1 was released, introducing Stand-alone and Distributed Integrated Architecture. In this version, database RTO (Recovery Time Objective) was reduced to within 8 seconds, ensuring rapid recovery after unexpected failures. The limit on partition replicas was removed to improve the capability for handling large transactions. Furthermore, core features such as arbitration service were introduced to effectively reduce costs.
In September 2023, OceanBase released the first Long-Term Support (LTS) version of the 4.x series, 4.2.1 LTS, which supplemented the main capabilities of 3.x and comprehensively enhanced stability, scalability, small-scale development, and diagnostic usability. Half a year after its release, hundreds of customers had already applied the LTS version to their production, demonstrating stable performance.
To meet the requirements for usability and diverse workloads, this year, OceanBase released 4.3.0 Beta. It provides a columnar engine based on the log-structured merge-tree (LSM-tree) architecture to implement integrated row- and column-based data storage. Powered by a new vectorized engine that is based on column data format descriptions and a cost model that is based on columnar storage, this version supports efficient processing of wide tables. This greatly improves the query performance in analytical processing (AP) scenarios while ensuring the performance in transaction processing (TP) business scenarios. Moreover, the new version includes a materialized view feature, which pre-evaluates and stores view query results to enhance real-time query performance. You can use materialized views for quick report generation and data analytics. The kernel of this version supports online DDL and tenant cloning features, optimizes system resource usage, and improves the ease of use of the system. We recommend that you use this version in hybrid load scenarios such as complex analytics, real-time reports, real-time data warehousing, and online transactions.
Test results have shown that OceanBase 4.3 achieves query performance in wide table processing scenarios comparable to that of mainstream columnar wide table databases in the industry, operating under equivalent hardware environments.
In this article, we will provide a detailed overview of the main features of OceanBase 4.3, including:
● Integrated TP & AP
● Kernel enhancements
● Performance improvements
● Improvements in ease of use
Integrated TP & AP
OceanBase 4.3 enhances the AP capabilities on the basis of version 4.2, maintaining the high-concurrency real-time update of row-level data and the support for point queries with primary key indexes, while possessing scalability, high availability, strong consistency, and geographical disaster-resilience in a distributed architecture. The new columnar engine, enhanced vectorized execution, parallel computation, and distributed plan optimization capabilities allow for a single database to simultaneously support TP and AP business.
Integrated row- and column-based data storage
Columnar storage is crucial for AP databases in scenarios involving complex analytics or ad-hoc queries on a large amount of data. A columnar storage differs from a row-based storage in that it physically arranges data in tables based on columns. When data is stored in columnar storage, the engine can scan only the column data required for query evaluation without scanning entire rows in AP scenarios. This reduces the usage of I/O and memory resources and increases the evaluation speed. In addition, columnar storage naturally provides better data compression conditions to achieve a higher compression ratio, thereby reducing the storage space and network bandwidth required.
However, common columnar engines are implemented generally based on the assumption that the data organized by column is static without massive random updates. In the case of massive random updates, system performance issues are unavoidable. The LSM-Tree architecture of OceanBase can resolve this problem by separately processing baseline data and incremental data. Therefore, OceanBase 4.3.0 supports the columnar engine based on the current architecture. It implements columnar storage and rowstores on the same OBServer node based on a single set of code and architecture, ensuring both TP and AP query performance.
The columnar engine is optimized in terms of optimizer, executor, DDL processing, and transaction processing modules to facilitate AP business migration and improve ease of use in the new version. Specifically, a columnar storage-based new cost model and a vectorized engine are introduced, the query pushdown feature is extended and enhanced, and new features such as the Skip Index attribute, new column-based encoding algorithm, and adaptive compactions are provided.
In OceanBase's MySQL mode or Oracle mode, executing the following command to establish a columnstore table by default. It is recommended for analytical scenarios:
alter system set default_table_store_format = "column";In practical AP business scenarios, users can flexibly configure tables in their systems as rowstore tables, columnstore tables, or hybrid rowstore-columnstore tables based on their specific workload requirements.
Meanwhile, the optimizer will decide whether to use row storage or columnar storage based on the cost evaluation.
New Vectorized Engine
OceanBase has implemented a vectorized engine based on uniform data descriptions in earlier versions, which obviously improves the performance in contrast to non-vectorized engines but is incompetent in deep AP scenarios. OceanBase 4.3.0 implements vectorized engine 2.0 that is based on column data format descriptions. This avoids memory use, serialization, and read/write overheads caused by ObDatum maintenance. Based on the column data format descriptions, OceanBase 4.3.0 also re-implements more than 10 common operators such as HashJoin, AGGR, HashGroupBy, and Exchange (DTL Shuffle), and about 20 MySQL expressions including relational operation, logical operation, and arithmetic operation expressions. Based on the new vectorized engine, OceanBase will implement more operators and expressions in later 4.3.x versions to achieve higher performance in AP scenarios.
Materialized Views
The materialized view feature is introduced since OceanBase 4.3.0. Materialized views are a key feature for AP business scenarios. By precomputing and storing the query results of views, real-time calculations are reduced to improve query performance and simplify complex query logic. Materialized views are commonly used for rapid report generation and data analysis scenarios.
Because materialized views optimize query performance by storing the query results, and there is a data dependency between materialized views and underlying tables, In OceanBase 4.3.0, a materialized view refresh mechanism is introduced, supporting two strategies: complete refresh and incremental refresh.
Complete refresh is a more direct approach where each time the refresh operation is executed, the system will re-execute the query statement corresponding to the materialized view, completely calculate and overwrite the original view result data. This method is suitable for scenarios with relatively small data volumes.
In contrast, incremental refresh only processes data that has changed since the last refresh. To ensure precise incremental refreshes, OceanBase has implemented a materialized view log mechanism similar to Oracle's Materialized View Log (MLOG), which tracks and records incremental update data of the base table in detail through logs, ensuring that the materialized view can be quickly incrementally refreshed. Incremental refresh is suitable for business scenarios with substantial data volumes and frequent data changes.
Kernel enhancements
OceanBase 4.3 introduces a new cost model, supports Online DDL and tenant cloning, restructures the session management module, renovates the log stream state machine, supports AWS Simple Storage Service (S3) as the backup and restore media, optimizes system resource usage, and improves the database's performance and stability for mission-critical workloads.
Enhancement of the row-based cost estimation system
As the OceanBase version evolves, more cost estimation methods are supported for optimizers. For row-based cost estimation by each operator, a variety of algorithms, such as storage-layer cost estimation, statistics cost estimation, dynamic sampling, and default statistics, are supported. However, no clear cost estimation strategies or control measures are available. OceanBase 4.3.0 restructures the row-based cost estimation system. Specifically, it prioritizes cost estimation strategies based on scenarios and provides methods such as hints and system variables for manually intervening in the selection of a cost estimation strategy. This version also enhances the predicate selectivity and number of distinct values (NDV) calculation framework to improve the accuracy of cost estimation by optimizers.
Enhancement of the statistics feature
OceanBase 4.3.0 improves the statistics feature in terms of functionality, statistics collection performance, compatibility, and ease of use. Specifically, this version restructures the offline statistics collection process to improve the statistics collection efficiency, and optimizes the statistics collection strategies. By default, OceanBase of this version automatically collects information about index histograms and uses derived statistics. This version ensures transaction-level consistency of statistics collected online. It is compatible with the DBMS_STATS.COPY_TABLE_STATS procedure of Oracle to copy statistics and compatible with the ANALYZE TABLE statement of MySQL to support more syntaxes. Moreover, this version provides a command to cancel statistics collection, supports statistics collection progress monitoring, and enhances the ease of maintenance. It also supports parallel deletion of statistics.
Adaptive cost model
In earlier versions of OceanBase, the cost model uses constant parameters evaluated by internal servers as hardware system statistics. It uses a series of formulas and constant parameters to describe the execution overhead of each operator. In actual business scenarios, different hardware environments can provide different CPU clock frequencies, sequential/random read speeds, and NIC bandwidths. The differences may contribute to cost estimation deviations. Due to the deviations, the optimizer cannot always generate the optimal execution plan in different business environments. This version optimizes the implementation of the cost model. The cost model can use the DBMS_STATS package to collect or set system statistics parameters to adapt to the hardware environment. The DBA_OB_AUX_STATISTICS view is provided to display the system statistics parameters of the current tenant.
Fixing of session variables for function indexes
When a function index is created on a table, a hidden virtual generated column is added to the table and defined as the index key of the function index. The values of the virtual generated column are stored in the index table. The results of some built-in system functions are affected by session variables. The evaluation result of a function varies based on the values of session variables, even if the input arguments are the same. When a function index or generated column is created in this version, the dependent session variables are fixed in the schema of the index column or generated column to improve stability. When values of the index column or generated column are calculated, fixed values are used and are not affected by variable values in the current session. In OceanBase 4.3.0, system variables that can be fixed include timezone_info, nls_format, nls_collation, and sql_mode.
Online DDL extension in MySQL mode
OceanBase 4.3.0 supports online DDL operations for column type changes in more scenarios, including:
Conversion of integer types: Online DDL operations, instead of offline DDL operations, are performed to change the data type of a primary key column, index column, generated column, column on which a generated column depends, or column with a UNIQUE or CHECK constraint to an integer type with a larger value range.
Conversion of the DECIMAL data type: For columns that support the DECIMAL data type, online DDL operations are performed to increase the precision within any of the [1,9], [10,18], [19,38], and [39,76] ranges without changing the scale.
Conversion of the BIT or CHAR data type: For columns that support the BIT or CHAR data type, online DDL operations are performed to increase the width.
Conversion of the VARCHAR or VARBINARY data type: For columns that support the VARCHAR or VARBINARY data type, online DDL operations are performed to increase the width.
Conversion of the LOB data type: To change the data type of a column that supports LOB data types to a LOB data type with a larger value range, offline DDL operations are performed for columns of the TINYTEXT or TINYBLOB data type, and online DDL operations are performed for columns of other data types.
Conversion between the TINYTEXT and VARCHAR data types: For columns that support the TINYTEXT data type, online DDL operations are performed to change the VARCHAR(x) data type to the TINYTEXT data type if x <= 255, and offline DDL operations are performed if otherwise. For columns that support the VARCHAR data type, online DDL operations are performed to change the TINYTEXT data type to the VARCHAR(x) data type if x >= 255, and offline DDL operations are performed if otherwise.
Conversion between the TINYBLOB and VARBINARY data types: For columns that support the TINYBLOB data type, online DDL operations are performed to change the VARBINARY(x) data type to the TINYBLOB data type if x <= 255, and offline DDL operations are performed if otherwise. For columns that support the VARBINARY data type, online DDL operations are performed to change the TINYBLOB data type to the VARBINARY(x) data type if x >= 255, and offline DDL operations are performed if otherwise.
Globally unique client session IDs
If OceanBase is of a version earlier than 4.3.0 and OceanBase Database Proxy (ODP) is of a version earlier than V4.2.3, the client session ID of ODP is returned if you execute the SHOW PROCESSLIST statement in ODP to query the session ID, and the server session ID is returned if you query the session ID by using an expression such as connection_id or from a system view. One client session ID corresponds to multiple server session IDs, making it difficult to use a unique ID to identify a session on the entire link. As a result, you can be easily confused when you query session information, which causes inconveniences in user session management. This version restructures the client session ID generation and maintenance process. If OceanBase is of 4.3.0 or later and ODP is of 4.2.3 or later, when you query a session ID by executing the SHOW PROCESSLIST statement, from the information_schema.PROCESSLIST or GV$OB_PROCESSLIST view, or by using the connection_id, userenv('sid')/userenv('sessionid'), or sys_context('userenv','sid')/sys_context('userenv','sessionid') expression, the client session ID is returned. You can manage client sessions by using the KILL statement in SQL or PL. If OceanBase or ODP does not meet the version requirement, the handling method in earlier versions is used.
Renovation of the log stream state machine
In this version, the status of a log stream is subject to the memory status and persistence status. The persistence status indicates the lifecycle of the log stream. After the log stream is restarted upon a server breakdown, the presence status and memory status of the log stream are determined based on the persistence status. The memory status is the running status of the log stream. It indicates the overall status of the log stream and the status of key submodules. Based on the explicit status and status sequence of the log stream, underlying modules can determine which operations of the log stream are safe and whether the log stream has changed from one state to another and then changed back to the original state. The working status and performance of a log stream after it is restarted upon a server breakdown are optimized for backup and restore processes and migration processes. This improves the stability of log stream features and enhances the concurrency control over log streams.
Tenant cloning
OceanBase 4.3.0 introduces the tenant cloning feature. You can clone a specified tenant in the sys tenant efficiently. The cloned tenant is a standby tenant. You can switch the cloned tenant to the PRIMARY role to provide services. The cloned tenant and original tenant share the physical macroblocks. However, new data changes and resource usage are isolated by tenant. If you want to perform temporary data analysis or other risky operations with high resource consumption on an online tenant, you can clone the tenant and perform analysis or verification on the cloned tenant to avoid affecting the online tenant. You can also clone a tenant for disaster recovery. When an unrecoverable misoperation is performed on the original tenant, you can use the cloned tenant for data rollback.
AWS S3 supported for backup and restore
OceanBase supports Network File System (NFS), Alibaba Cloud Object Storage Service (OSS), and Tencent Cloud Object Storage (COS) as the storage media for the backup and restore feature in earlier versions. OceanBase 4.3.0 further supports AWS S3 as the storage media for backup and restore. You can use AWS S3 as the destination for log archiving and data backup, and use the backup data on AWS S3 for physical restore.
Proactive broadcasting/refreshing of tablet locations
OceanBase provides the periodic location cache refreshing mechanism to ensure that the location information of log streams is updated in real time and is consistent. However, tablet location information can only be passively refreshed. Changes in the mappings between tablets and log streams can trigger SQL retries and read/write errors with a certain probability. OceanBase 4.3.0 supports proactive broadcasting of tablet locations to reduce SQL retries and read/write errors caused by changes in mappings after transfer. This version also supports proactive refreshing to avoid unrecoverable read/write errors.
Active transaction transfer
In the log stream design in OceanBase 4.x, data is managed in the unit of tablet and logs are managed in the unit of log stream. Tablets are aggregated in a log stream to avoid two-phase commit of transactions in the log stream. To achieve a balance of data and traffic among different log streams, OceanBase allows you to flexibly transfer tablets among log streams. However, during the transfer, an active transaction may still be operating data, which may compromise the atomicity, consistency, isolation, and durability (ACID) capability of the transaction. For example, if the data of an active transaction at the source is not fully transferred to the destination, the atomicity of the transaction cannot be ensured. In versions earlier than 4.3.0, OceanBase will terminate active transactions during the transfer. This affects normal execution of transactions. To resolve this issue, OceanBase 4.3.0 supports the transfer of active transactions. This allows parallel execution of active transactions and avoids transaction rollback or inconsistency caused by the transfer.
Memory throttling mechanism
In OceanBase of a version earlier than 4.x, only a few modules require freezes and minor compactions to release the memory, and most of the modules are MemTables. Therefore, a memory limit is set for MemTables and throttling logic is used to ensure that the memory usage smoothly approaches the upper limit, avoiding write stop in the system caused by sudden OOM errors. In OceanBase 4.x, more modules, such as the TxData module, require freezes and minor compactions to release the memory. More refined means are provided to control the memory usage of modules. The memory for the TxData and Multi Data Source (MDS) modules is limited. The two modules share the memory with MemTables. When the memory usage reaches the value of Tenant memory × _tx_share_memory_limit_percentage% × writing_throttling_trigger_percentage%, overall throttling is triggered. This version also supports triggering freezes and minor compactions for transaction data tables by time. By default, a freeze is triggered for transaction data tables every 1,800 seconds to reduce the memory usage of the TxData module.
Optimization of the space for temporary results of DDL operations
Many DDL operations store temporary results in materialized structures. Here are two typical scenarios:
In an index creation scenario where data is scanned from the data table and inserted into the index table, the data scanned from the data table needs to be sorted. If the memory is insufficient during the sorting, the current data in the memory will be temporarily stored in materialized structures to release the memory space for subsequent scanning. Then, the data in the materialized structures will be merged and sorted. This practice is particularly effective in the case of limited memory but requires extra disk space.
In a columnar storage bypass import scenario, the system temporarily stores the data to be inserted into column groups in materialized structures, and then reads the data from the materialized structures when inserting data into each column group. These materialized structures can be used in the SORT operator to store intermediate data required for external sorting. When the system inserts data into column groups, it can cache the data to avoid extra overheads caused by repeated table scanning. This practice can prevent repeated scanning from compromising the performance, but increases the disk space occupied by temporary files.
To resolve these issues, this version optimizes the data flow of DDL operations. Specifically, it eliminates unnecessary redundant structures to simplify the data flow. It also encodes and compresses the temporary results before storing them in the disk. In this way, the disk space occupied by temporary results during DDL operations is significantly reduced, facilitating efficient use of storage resources.
Performance improvements
OceanBase 4.3.0 significantly enhances the OLAP capabilities, leading to notable performance improvements in TPC-H 1T and TPC-DS 1T. Additionally, the new version optimizes the parallel DML (PDML) and OBKV read/write, and improves the bypass import efficiency for data of large object (LOB) types, and the restart speed of OBServer node.
TPC-H 1T performance increased by 25%
Under the 80C 500GB tenant specifications, the performance comparison of TPC-H 1T across different versions is as follows:

OceanBase 4.3.0 shows an overall improvement of around 25% compared to OceanBase 4.2.0.
TPC-DS 1T Performance Increased by 112%
Under the 80C 500GB tenant specifications, the performance comparison of TPC-DS 1T across different versions is as follows:
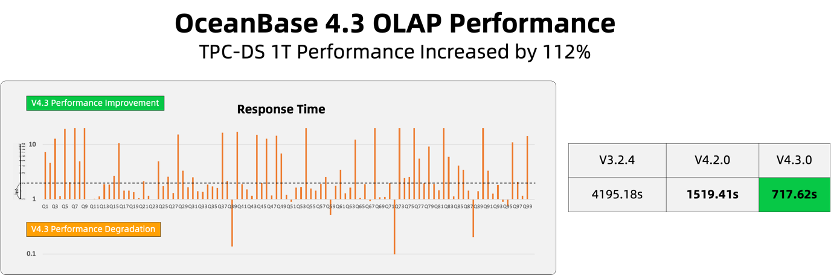
OceanBase 4.3.0 shows an overall improvement of around 112% compared to OceanBase 4.2.0.
OBKV Performance Optimization
Compared to OceanBase 4.2.1, the performance of single-row read/write operations in OBKV has improved by approximately 70%. Batch read/write performance has also seen an improvement ranging from 80% to 220%.
PDML transaction optimization
This version supports parallel commit and log replay at the transaction layer, and provides partition-level rollback inside transaction participants, which helps significantly improve the DML execution performance in high concurrency scenarios in contrast to earlier 4.x versions.
Optimization of I/O usage in loading tablet metadata
OceanBase 4.x supports millions of partitions on a single server and on-demand loading of metadata because the metadata of millions of tablets cannot be all stored in the memory. On-demand loading is supported at the partition and subcategory levels. Metadata in a partition is divided into different subcategories for layered storage. When a background task requires metadata of a deep level, reading the data results in a high I/O overhead. A high I/O overhead is acceptable for a local solid-state disk (SSD) but may compromise the system performance in scenarios where a hard disk drive (HDD) or a cloud disk is used. This version aggregates the frequently accessed metadata for storage, reducing the number of I/O times required for accessing the metadata to 1. This greatly decreases the I/O overhead in the case of no load and prevents the I/O overheads of background tasks from affecting the query performance in the foreground. The process of loading metadata upon an OBServer node restart is also optimized. Specifically, tablet metadata is batch loaded based on macroblocks. This significantly reduces discrete read I/O operations and increases the restart speed by multiple times or even dozens of times.
Improvements in ease of use
The new version supports index monitoring to easily identify and delete useless indexes to reduce the system load, as well as local data import from the client to improve the working efficiency in scenarios where a small amount of data needs to be imported. Additionally, it provides INROW storage threshold for LOBs, RPC security certificate management, and parameter resetting to enhance system usability.
Index monitoring
Indexes are usually created to improve the performance in querying data from a database. The number of indexes created on a data table increases as business scenarios and operation personnel increase over time. Unused indexes will waste the storage space and increase the overheads of DML operations. In this case, constant attention is required to identify and delete useless indexes to reduce the system load. However, it is difficult to manually identify useless indexes. Therefore, OceanBase 4.3.0 introduces the index monitoring feature. You can enable this feature for a user tenant and set sampling rules. The index uses information that meets the specified rules is recorded in the memory and updated to the internal table every 15 minutes. You can query the DBA_INDEX_USAGE view to verify whether indexes in a table are referenced and delete useless indexes to release the space.
Local import from the client
OceanBase 4.3.0 provides the local import feature (LOAD DATA LOCAL INFILE statement) for loading data from local files on the client in streaming mode. In this way, developers can directly use local files for testing without the need to upload the files to the server or object storage service, improving the working efficiency in scenarios where a small amount of data needs to be imported.
Notice: To use this feature, make sure that the following conditions are met:
● The version of OceanBase Client (OBClient) is 2.2.4 or later.
● The version of ODP is 3.2.4 or later, if ODP is used for connection to OceanBase. If you directly connect to an OBServer node, ignore this requirement.
● The version of OceanBase Connector/J is 2.4.8 or later, if Java and OceanBase Connector/J are used.
In addition, you can directly use a MySQL client or a native MariaDB client of any version.
The SECURE_FILE_PRIV variable specifies the privileges for accessing paths on the server. It does not affect the local import feature and therefore does not need to be specified.
INROW storage threshold for LOBs
A large object (LOB) less than or equal to 4 KB in size is stored in INROW (in-memory storage) mode. A LOB greater than 4 KB is stored in the LOB auxiliary table. The row-based storage feature of INROW storage provides higher performance than auxiliary table-based storage in some scenarios. Therefore, OceanBase 4.3.0 supports dynamic configuration of the LOB storage mode. You can dynamically adjust the INROW storage size as needed provided that the size does not exceed the maximum row size allowed.
RPC security certificate management
After remote procedure call (RPC) authentication is enabled for a cluster, when a client, such as an arbitration service client, primary or standby database, or OceanBase Change Data Capture (CDC) client, initiates an access request to the cluster, you need to first place the root CA certificate of the client to the deployment directory of each OBServer node in the cluster and then complete related settings. This process is complex. OceanBase 4.3.0 supports the internal certificate management feature. You can call the DBMS_TRUSTED_CERTIFICATE_MANAGER system package in the sys tenant to add, delete, and modify root CA certificates trusted by a cluster. You can query the DBA_OB_TRUSTED_ROOT_CERTIFICATE view in the sys tenant for the list of root CA certificates added to the cluster, as well as information about the certificates, such as the expiration time.
Parameter resetting
In earlier versions, if you want to reset a modified parameter to its default value, you must first query the default value of the parameter and then manually set the parameter to the default value, delivering poor ease of use. In OceanBase 4.3.0, the ALTER SYSTEM [RESET] parameter_name [SCOPE = {MEMORY | SPFILE | BOTH}] {TENANT [=] 'tenant_name'} syntax is provided for resetting a parameter to its default value. The default value is obtained from the node that executes the statement. You can reset cluster-level parameters and the parameters of a specified user tenant from the sys tenant. You can reset the parameters of only the current tenant from a user tenant. The implementation of the SCOPE option is consistent across different versions of OceanBase. For parameters whose modifications take effect statically, the system only stores their default values in the disk but does not update their values in the memory. For parameters whose modifications take effect dynamically, the system updates their values in the memory and stores their default values in the disk.

