
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Exploring OceanBase 4.3: New Features and Enhancements

At the OceanBase DevCon 2024, we introduced the OceanBase 4.3.0 Beta, unveiling a brand new columnar engine. This release achieves near petabyte-scale, real-time analytics in seconds, and enhances the integration of TP and AP capabilities.
Following the debut of OceanBase 4.3.0 Beta at the Developer Conference, the OceanBase 4.3.1 Beta was released on May 17. This version brings significant enhancements to foundational OLAP capabilities, including the full-text indexes, materialized view enhancements (i.e., real-time materialized view and automatic query rewriting) , and external table enhancements (i.e., partitioned table storage in separate directories). As experimental features, incremental direct load capabilities have been introduced to improve the performance of importing multiple times. Furthermore, this version offers extended support for JSON, including multi-value indexes for JSON. Additionally, in this release, compression can be enabled when writing temporary SQL results to disks, addressing disk space issues caused by large OLAP queries.
This article provides an in-depth exploration of the core features, performance improvements, and application scenarios of OceanBase 4.3, and the kernel-level product roadmap.
Better OLTP
Throughout the development journey of OceanBase, from the initial 1.x to the current 4.3, we have been strengthening OLTP (Online Transaction Processing) as a key capability, which has been extensively verified on the critical business load of thousands of customers. In 4.3, we have further improved the functionalities of OLTP, including tenant cloning, optimizer enhancements, transaction log optimizations, and space optimizations for large table DDLs, to name just a few highlights. In fact, we have made improvements in many details. We are continuously optimizing our products and are committed to providing users with a better OLTP experience.
To improve the usability of OLTP, we introduced features such as parameter templates, index usage monitoring, configuration item reset, and local client import. Many of these features are designed to address user pain points. For example, previously, after installing OceanBase, users had to configure a vast number of parameters to achieve optimal performance in their business scenarios. In e-commerce scenarios, what kind of parameter settings are needed for simple OLTP applications with high concurrency? In banking services, what kind of parameter settings are needed for complex queries? In the past, this process required users to explore through trial and error.
In 4.3, we provide a set of parameter templates. Users only need to determine the business type and can then directly apply the corresponding template to set initial parameters, thus obtaining a good experience. Meanwhile, index usage monitoring has been upgraded. In previous versions, it was difficult for users to determine which indexes were being utilized and which could be deleted. Now with index usage monitoring, users can easily determine these situations.
New OLAP
Early versions of OceanBase already provided certain OLAP capabilities. In 2021, OceanBase topped the list in the TPC-H benchmark test with 15.26 million QphH@30,000GB. Even so, there is still much to be done in terms of OLAP. In 4.3, OceanBase complemented the important capabilities of OLAP.

In 4.3, on the basis of existing capabilities, OceanBase supplemented essential features for pure OLAP, such as columnar storage, materialized views, data import, and data processing, etc., to better support the AP ecosystem. The whole OLAP capability puzzle is becoming more complete. Once we complete this puzzle, developers can work with OceanBase more easily, and a single set of architecture can address both OLTP and OLAP requirements for SMEs.
A Simple Demonstration of AP Capabilities: an Ordering System Demo
The OceanBase team has always been contemplating how to present AP capabilities more intuitively. Therefore, at this year's OceanBase Developers Conference, we presented a simple demo, which is divided into two parts: on the left side is the APP, simulating a mobile shopping scenario; on the right side is a dashboard for store managers. After placing an order on the left side, the data on the right dashboard will be refreshed within 2 seconds.

What does 2 seconds mean? In traditional OLAP tools, there's a synchronization process from TP to AP, which accumulates a batch of data for a relatively large transaction to be written into the AP database. Therefore, batching means increased system latency.
OceanBase supports small transactions, allowing for immediate synchronization and writing into the AP database even with just one row of data. This is easy for OceanBase, as it already has the capability for small transactions in the OLTP domain.
To obtain real-time dashboard data, fast table scanning is also required. In the demo, the dashboard query is scanned without any pre-aggregation. The order table contains about 180 million rows of data, which can be scanned and aggregated in about 10 milliseconds. To achieve that, what capabilities do we need?
In this scenario, first, the data should be read quickly. Second, it should be calculated quickly, such as fast aggregation calculations. Third, sync quickly. Data should be quickly transferred from the TP database to the AP database. OceanBase provides several corresponding solutions.
First, read fast. Fast reading relies on the columnar storage introduced in 4.3. OceanBase's columnar storage feature is a bit different from most AP databases in the market: OceanBase's tables are not limited to columnar storage but also support a mix of column-based and row-based storage. If there are both analytical queries and a large number of high-concurrency point queries on a table, this mode can provide the best experience for users. Of course, if there are no point queries, a pure columnstore table would be enough, which saves more storage space.
OceanBase provides users with very flexible table-level choices, allowing them to build different tables according to business needs. In addition, OceanBase also supports column indexes. If a row table needs columnar storage to accelerate computing, users can also build columnstore indexes for the rowstore table, creating columnar storage only for some of the columns, to achieve optimal performance and minimal storage space.
Second, compute fast. Fast computing relies on the new vectorized engine introduced in 4.3. OceanBase's computing engine has been around for years, and by the fourth generation, it has supported columnar formats. This means OceanBase can read the data in columnar format at the storage layer and can directly compute based on this columnar format at the computing layer, without needing a secondary conversion, thus computing faster.
Third, T+0 real-time capability. T+0 fast sync relies on real-time writing capability, which OceanBase has possessed for years and can play a greater role in the AP scenario. This can be further broken down into two parts:

- Real-time import: importing data into the AP database in real-time, supporting very small transactions.
- Support Flink ecosystem: supporting the synchronization of OceanBase data to Flink, or Flink writing data from other sources into OceanBase in real-time.
In actual business, if data is distributed across multiple databases, you can use Flink to aggregate it into one OceanBase 4.3 AP database for analysis. OceanBase has advanced optimizers, vectorized engines, columnstore tables, rowstore tables, point queries with primary keys, supports Insert or Replace, Insert or Update (UpSert), and secondary indexes, and supports various join algorithms. From v2.x to v4.x, these features have gradually matured and can be well applied in AP analysis.
Materialized Views for Faster AP Real-time Analysis
In the demo mentioned above, the computing time takes about tens of milliseconds. Is it possible to reduce the computing time to 1 millisecond? The answer is yes-through materialized views.

By creating materialized views, users can avoid redundant computation. For example, if an aggregation has already been done on 180 million rows, the new incoming data only needs to be re-aggregated without re-scanning the data, which is the ability provided by the materialized view.
Through experiments, first performing aggregation by color and creating a materialized view, and then conducting a TOP3 query and a total reservation quantity query based on the materialized view, users can reduce the total query time to 1 millisecond. After the materialized view is created, the table only contains dozens of rows, and queries on a table with only dozens of rows are naturally very fast.
Now let's take a look at the roadmap for OceanBase's materialized views.
In 4.3.0, we supported non-real-time materialized views, meaning that after data is inserted into the source table, the data is not automatically queryable in the materialized view and needs to be manually refreshed to synchronize the data. In 4.3.1, we introduced support for real-time materialized views, which means that once data is inserted into the source table, it can be immediately queried. 4.3.1 also supports asynchronous real-time materialized views. Incremental data is written into a structure named mlog. During queries, the baseline materialized view is queried. At the same time, the mlog data is aggregated to derive the final result. From the user's perspective, what they get is a real-time aggregated result.
If there's demand, in future releases, OceanBase may support synchronous real-time materialized views, that is, as soon as a row is inserted into the source table and the transaction is committed, the aggregation on the materialized view layer happens immediately. If there is such a demand, please feel free to give us a feedback.
In 4.3.1, OceanBase also supports automatic query rewriting. In other words, once a materialized view is created, users don't have to change their source table queries. If the optimizer finds that the query can benefit from the materialized view, it will automatically rewrite the query to use the materialized view, allowing users to achieve performance acceleration seamlessly.
If you want to try AP capabilities, the first step is to import data from other databases or files into OceanBase.

The faster you import the data, the better. Users can quickly import data into OceanBase through a bypass import method. Below are the real figures we've obtained from experiments:
- If the table does not have a primary key, the import speed can reach 1 million rows per second;
- If there is a primary key on the table, due to the need for sorting, an import speed of 500,000 rows per second can be achieved.
Rich OLAP Scenarios
We introduced the core features of the 4.3. Now, let's talk about the scenarios.
TP Enhancement Scenarios
If you want to experience AP capabilities in OceanBase TP database, what should you do? Setting up a dedicated AP cluster is quite troublesome. OceanBase offers a method: create an index on the current rowstore table, and specify the storage format of the index as columnar storage, that is, a columnstore index. This enables the existing cluster to gain the capabilities of columnar storage and accelerate queries. For example, the following statement creates a columnstore index for columns c2 and c3 of table t1.
create index idx1 on t1(c2,c3) with column group (each column);
In this case, both row and column stores are in the same cluster, sharing the same set of hardware resources. Naturally, resource isolation is required. OceanBase provides resource isolation within tenants based on Cgroup, as well as IOPS isolation. This can achieve isolation of CPU and I/O, ensuring that AP and TP won't interfere with each other.
ODS & Serving Scenarios
In big data processing, OceanBase can be used in ODS and serving scenarios:

- ODS: The data from the users is first written to the ODS layer. Why is OceanBase suitable for the ODS layer? Because it supports real-time writing, bulk insert, and partial updates, and also provides an HBase mode. Many systems' ODS layers are built with HBase. Users can use the HBase mode on OceanBase or directly store data in table format. After writing data into the ODS layer, the analysis is then performed with third-party ecosystem tools, and the analysis results are used for real-time querying. It's worth mentioning that as early as v3.2, OceanBase has been successfully applied to the ODS scenario of a leading insurance data warehouse.
- ADS: OceanBase can also be used in the data warehouse ADS layer. As ADS will handle both analytical and point queries with high concurrency requirements, OceanBase can provide outstanding ADS query performance based on row and columnar storage capabilities.
Lightweight Data Warehouse Scenarios
In data warehouse scenarios, users can simplify the ETL process by comprehensively using OceanBase. Setting up various materialized views with OceanBase to perform ETL can simplify the operation and maintenance of the data warehouse.

Lightweight Real-time Data Warehouse Scenarios

4.3 supports both Flink-CDC and Flink Connector. In lightweight real-time data warehouse scenarios, Flink can use OceanBase as a storage option and can also conduct queries in OceanBase to accelerate computing.
As shown in the figure, Flink can subscribe the change logs at the ODS layer of OceanBase, conduct real-time stream computing, and finally write the results to the ADS layer through the Flink Connector to provide services such as interactive queries, federated queries, complex queries, and multi-dimensional queries.
Real-time AP Performance
We've briefly introduced the OLAP functionalities and typical scenarios of OceanBase. In practical use, users also care about the real-time AP performance.
TPC-H 1T performance increased by 25%

OceanBase v4.2 already had certain data analysis capabilities. At a 1TB data scale, compared to v4.2, OceanBase 4.3 saw a performance increase of 25% in the TPC-H benchmark test. It is worth mentioning that the TPC-H benchmark model does not involve scenarios with large, wide tables, which does not take full advantage of the columnar storage engine. Thus, in these scenarios, the performance improvement in 4.3 did not see a multiple-fold change.
TPC-DS 1T Performance Increased by 112%

The figure below shows the 100 queries of TPC-DS, with each data point representing the performance improvement of 4.3 compared to v4.2. On the horizontal axis, 0 indicates that the performance of 4.3 is the same as that of v4.2, the dashed line represents the performance improvement of 4.3 reaching or exceeding 1 time, and the top line indicates that in the current query performance test, the performance improvement of 4.3 reaches/exceeds 10 times.
Taking query Q37 as an example, the performance improvement of 4.3 reached more than tenfold, thanks to improvements in columnar storage, as well as optimizer and execution abilities.
Roadmap and Future Prospects
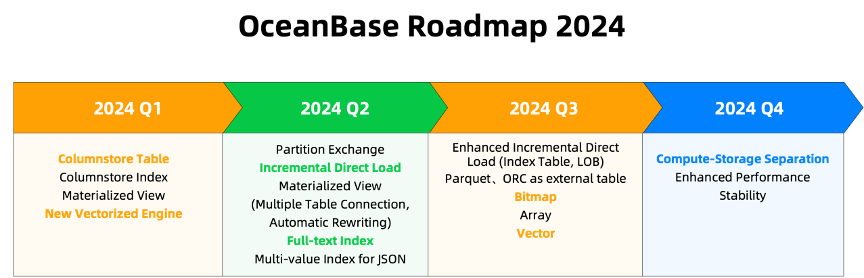
📢1Q24: We have released columnstore tables, columnstore indexes, materialized views, and the brand-new vectorized engine, which have equipped OceanBase with the fundamental capabilities for AP real-time analysis. AP is not a simple project; to truly excel in AP real-time analysis workloads, there is still much to be done. Therefore, we will continue to optimize OceanBase's AP real-time analysis capabilities to meet users' growing demands.
📢2Q24: We will continue to refine materialized views to support real-time reading, automatic rewriting, etc. Recognizing that users' AP scenarios are not limited to basic data types but also need to handle complex scenarios like full-text indexes, we are introducing full-text indexes and multi-value indexes for JSON to meet users' expectations for broader data processing needs.
📢3Q24: In the upcoming versions, we plan to introduce three important capabilities:
- Parquet, ORC: With the continuous evolution of data processing requirements, data is not limited to a single database but stored in data lakes, S3, OSS, and other environments. To fully leverage analytical capabilities, OceanBase needs the ability to interact with external environments. Parquet and ORC are two typical external storage formats, and OceanBase will support the analysis of Parquet and ORC in the form of external tables.
- Bitmap: Bitmap is widely used in crowd selection, real-time advertising, and marketing scenarios, and can achieve millisecond-level responses to related queries. With the introduction of Bitmap, we will further help users improve query performance and efficiency.
- Vector: Supporting vector databases, OceanBase will support the vector storage format, vector distance calculation functions, and provide plug-in vector indexes for the vector index layer. This will enable OceanBase to offer a broad range of index services, providing users with more flexible options.
📢4Q24: We will continue to focus on the storage cost, supporting compute-storage separation based on S3 to further reduce the storage costs of TP and AP, thereby helping users reduce operating costs and improve efficiency.



Keep Reading
View all posts
How seekdb M0 Gives OpenClaw Persistent Memory and Shared Experience
OpenClaw's memory degrades over time—an architectural limitation, not a configuration issue. seekdb M0 solves this with cloud-based memory that persists across sessions and shares learned experience across agents.



OceanBase 4.4.2 LTS: Integrating Transactions, Analytics, and AI in One Unified Database
V4.4.2 delivers comprehensive kernel improvements in data management, compatibility, security, and operational diagnostic. It has been extensively tested and is recommended for production use across TP, AP, HTAP, and AI workloads.


Start Small, Scale Big: Inside OceanBase's Distributed Architecture
OceanBase's integrated standalone-distributed architecture lets you start small, scale big — without repeated migrations.
