







How to Make DDL Execution Efficient and Transparent in a Distributed Database?





Image created by New Bing
Looking back at the development of relational databases since its wide application, the shift from standalone to distributed architecture is undoubtedly a key transition, which is driven by emerging business needs and the explosive growth of data volume.
On the one hand, a larger data volume nurtures more possibilities for socioeconomic development. On the other hand, it requires better database performance to curb the O&M costs and possible new faults coming along with the increase of storage nodes. Therefore, making operations on a distributed database transparent as on a standalone database becomes one of the keys to improving user experience.
As frequently performed operations in database O&M, DDL operations should be transparent to both business developers and O&M engineers.
Frontline O&M engineers often say:
“You can only perform DDL operations late at night.”
“It takes a great deal of time, sometimes weeks, to execute DDL statements.”
They might not have such an awkward experience if a database is able to perform efficient and transparent DDL operations, meaning that the execution of DDL statements is fast and does not disrupt other business development or O&M tasks.
In this article, we will describe how OceanBase 4.0 has achieved efficient and transparent DDL operations, and introduce the features and the design ideas of new DDL operations in OceanBase 4.0 from the following perspectives:
1. What DDL operations are more user-friendly?
2. How do we achieve high-performance DDL operations in OceanBase Database?
3. What’s new about the DDL operations in OceanBase Database V4.0?
4. Hands-on testing of new DDL operations in OceanBase Database V4.0
What DDL operations are more user-friendly?
To answer this question, we need to understand the concept of DDL operations.
In addition to DML statements that directly manipulate the data, such as the SELECT, INSERT, UPDATE, and DELETE statements, database O&M also involves other statements, like the CREATE, ALTER, DROP, and TRUNCATE statements, which are intended to change the table schema or other database objects and are related to data definition. Statements of the latter type are referred to as DDL statements. Adding a column to a table and adding an index to a column, for example, are two everyday DDL operations.
In the early days of database development, the execution of DDL statements was considered one of the most expensive database operations, because DDL operations rendered tables unreadable and blocked ongoing tasks at that time. It would hold back database services for a long time to execute DDL statements on a table containing a large amount of data, which was unacceptable for critical businesses that must stay online all the time. Online DDL was therefore introduced to keep user requests alive while executing DDL statements. So far, most Online DDL-based databases on the market have not made DDL operations fully transparent to users.
- Most standalone databases apply transient locks during Online DDL operations. For example, DDL operations in large transactions in a MySQL database may block user requests.
- Online DDL operations in many distributed databases also disturb user requests in some business scenarios due to the limitations of the distributed architecture.
- Developed for standalone databases, Online DDL focuses on addressing the impact of DDL operations on normal user requests. It does not consider the response to exceptions of a node, such as a server crash, in a distributed database.
In this era of data explosion, the execution time of DDL statements is also a limiting factor in speeding up the business upgrade. In standalone databases, parallel sorting is usually used to maximize the execution speed of DDL statements. However, the speed is limited by the performance bottleneck of the standalone architecture. In distributed databases, an industry-wide practice is to complete the data by simulating the insert operation, which cannot make full use of the performance of every single server and ignores the benefits of scalability.
Arguably, the original Online DDL feature alone can no longer catch up with the business needs today.
We believe that the modern DDL feature should provide at least the following two benefits to better meet users’ business needs.
First, the execution of DDL statements does not affect DML or DQL operations on the business side and succeeds despite exceptions such as server crashes in a distributed system.
Second, DDL statements can be executed in parallel in both standalone and distributed systems to help users with rapid business innovation.
How does OceanBase 4.0 achieve high-performance DDL operations?
We hope to build OceanBase Database into a database product that is highly efficient and transparent enough to users.
When it comes to transparency, unlike their standalone cousins, distributed databases need to overcome node status inconsistency during DDL operations. To address this issue, most peer database vendors follow the “DDL first” principle in their product design, which cannot avoid the impact on user requests in some business scenarios. In contrast, we prioritize business requests in designing OceanBase Database. We have also tried our best to shield users from the impact of distributed execution so that they can execute DDL statements in a distributed database as in a standalone one.
As for execution efficiency, we have accelerated data completion, the most time-consuming DDL operation, by integrating design ideas of a standalone database, rather than using the widely adopted insertion simulation method, and achieved scalable performance of data completion in a distributed database. This makes DDL operations sufficiently efficient in OceanBase Database.
OceanBase 4.0 is optimized based on the native Online DDL framework:
- To improve the usability of DDL operations, we have developed a data synchronization method for bypass writes.
- We have significantly improved the responsiveness of DDL operations by optimizing their performance in a standalone database and scalability for a distributed database.
- More features are supported, such as primary key change, partitioning rule modification, column type modification, and character set modification.
Distributed online DDL: Putting business requests first
Before walking you through OceanBase Online DDL, we have to mention the online asynchronous schema change protocol of Google F1, which was introduced in the paper Online, Asynchronous Schema Change in F1 and has been applied in many distributed databases, such as CockroachDB, to support Online DDL operations. This protocol is complicated. Simply put, since table writes are not supposed to be disabled during the execution of DDL statements, it is likely that the schema version varies with database nodes. This protocol ensures data consistency by introducing multiple schemas in intermediate states.
Further, Google F1 does not have a global list of members. It forces periodical increment of the schema version without taking into account the server or transaction status during DDL execution. Also, it ensures that no more than two schema versions are used at the same time in a cluster. Therefore, Google F1 puts a limit on the execution time of transactions. A node will kill itself and quit if it cannot get the latest schema version, thus affecting the execution of all transactions on it. In a word, Google F1 gives priority to the execution of DDL statements regardless of the impact on transactions. We call it a “DDL first” design.
Unlike Google F1, OceanBase Database has a global list of members and coordinates with the members related to tables to be changed by DDL operations. The schema version is pushed forward only when the transaction status of all nodes meets the requirements for data consistency after a DDL operation. This way, the execution of general transactions is not affected. When a node cannot be refreshed to the latest schema version, instead of killing it, OceanBase Database restricts the execution of transactions related to the table on which DDL statements are being executed on the node. The execution of DDL statements on other tables is not affected. Apparently, the priority is given to business requests in OceanBase Database.
We tested the impact of DDL execution on business requests in Google F1 and OceanBase Database by creating indexes. The following table shows the results:
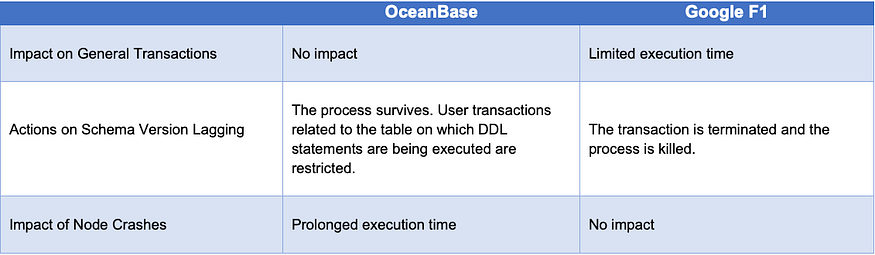
Table 1 Impact of index creation in OceanBase 3.x and Google F1
In addition to giving priority to business requests and transparent DDL execution, OceanBase Database V4.0 also enhances the high availability of DDL operations, so that the DDL execution time may not be prolonged in the case of node exceptions. We will provide more details on this later.
Efficient data completion
Some DDL operations, such as creating indexes and adding columns, require data completion. Since OceanBase Database V1.4, we have classified these DDL operations into two types: instant DDL operations, which modify the schema and complete data asynchronously, and real-time DDL operations, which complete data in real-time.
Most distributed databases achieve real-time data completion by simulating the insert operation. The strong point of this method is that it simply completes the data by reusing data write capabilities of DML operations and synchronizes the insert operation to the backups, such as replicas and standby clusters. The problem is, the data writes go through a complex process of SQL execution, transaction execution, and memory ordering, and, if the storage architecture is based on the LSM tree, multiple data compactions are performed, leading to poor performance. Therefore, we have integrated data sorting and bypass writing, two typical features of standalone databases, into the data completion operation in OceanBase Database. However, unlike standalone databases, OceanBase Database performs distributed sorting and optimizes the LSM-tree-based storage architecture to get better performance.
I. Distributed sorting
OceanBase Database V3.x reuses distributed sorting capabilities of the old SQL execution framework in DDL execution, which feature performance scalability but the efficiency of DDL execution on a single server falls short of expectation. OceanBase Database V4.0 performs distributed sorting based on the new SQL execution framework. The execution performance is significantly improved.
II. Optimization of the LSM-tree-based storage architecture
Unlike B-Tree, an update-in-place storage model commonly adopted in conventional databases, an LSM-tree-based storage architecture updates incremental data to incremental MemTables and writes data to persistent SSTables only by performing data compactions. This feature makes it much easier for OceanBase Database to accelerate data completion in DDL operations. On the one hand, operations like adding columns are natural instant DDL operations and the data can be asynchronously completed during compactions. On the other hand, for real-time DDL operations such as creating indexes, OceanBase Database can coordinate DDL and DML operations to get a version number where data completion is finished, and the transaction data of earlier versions is all committed. This way, the completed data is written to SSTables, and the incremental data generated by DML operations are written to MemTables. The incremental data generated during index creation can be maintained in real-time without synchronizing data as in update-in-place storage.
After years of development, OceanBase Database now supports most online DDL operations on indexes, columns, generated columns, foreign keys, tables, and partitions.
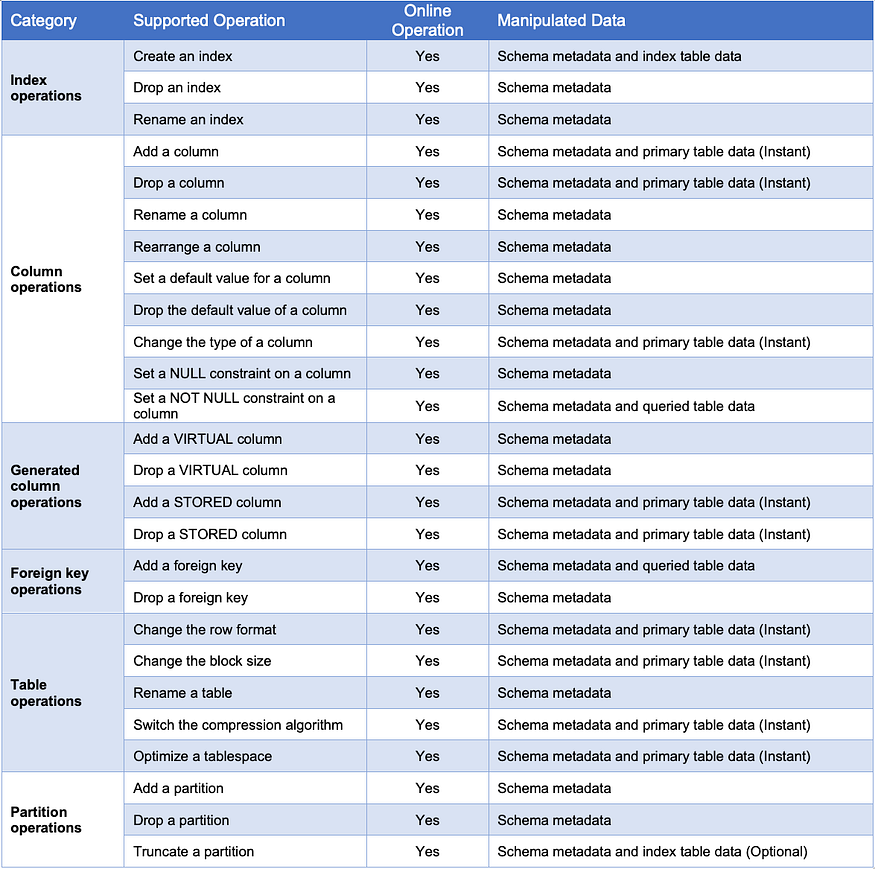
Table 2 Online DDL operations supported by OceanBase Database
What’s new about the DDL operations in OceanBase 4.0?
New DDL operations
Before OceanBase Database V4.0, we had learned that some users often needed to change the structure of database objects such as primary keys and partitions to support their new business needs. As such DDL operations rewrite the data of the original tables, we call them data-rewrite DDL operations.
So, what exactly are the purposes of data-rewrite DDL operations?
- Modify the partitioning rules: If the data volume or workload of an originally small business has outgrown the capacity of a single server, and the user needs to specify some table columns in the WHERE clause of a query or update statements, the user can perform data-rewrite DDL operations to partition the original table based on these columns to distribute the data volume or workload to multiple nodes.
- Modify the character set: If the collation of a column was mistakenly set to be case-insensitive, the user can perform data-rewrite DDL operations to change it to be case-sensitive.
- Change the column type: If, for example, a column of the INT type can no longer meet the business requirements, the user can perform data-rewrite DDL operations to change the type to VARCHAR.
- Change the primary key: If the self-defined ID column of a business table was used as the primary key, the user can perform data-rewrite DDL operations to use an auto-increment column as the primary key.
When the business of a user grows, not only the business size gets bigger, but also more database features are profoundly engaged in the business. This means that the DDL operations must grow with the business to support the business development in the long run. We found, however, that it is not the case for most distributed databases on the market today. Some do not support enough features, such as the change of primary keys or partitioning rules; others rewrite data by simulating data reinsertion, where the existing data is exported for new data insertion, which is inefficient and may interrupt other transactions of users.
OceanBase Database of an earlier version usually requires users to perform data-rewrite DDL operations by manually migrating the data in four steps: executing the DDL statements on the original table to create an empty table, exporting the data from the original table, writing the exported data to the new table, and renaming the original table and renaming the new table to the name of the original table. This method has many shortcomings. For example, it involves multiple steps and if a step fails, users must roll back the operations manually or by using external tools; the migration efficiency is low; and a server crash event makes it even harder to deal with idempotence issues when, for example, handling tables without primary keys.
OceanBase 4.0 supports native data-rewrite DDL operations. Users can get their job done, like modifying a partitioning rule or changing a primary key, character set, or column type, by simply executing a DDL statement, without caring about environmental exceptions during the operation.
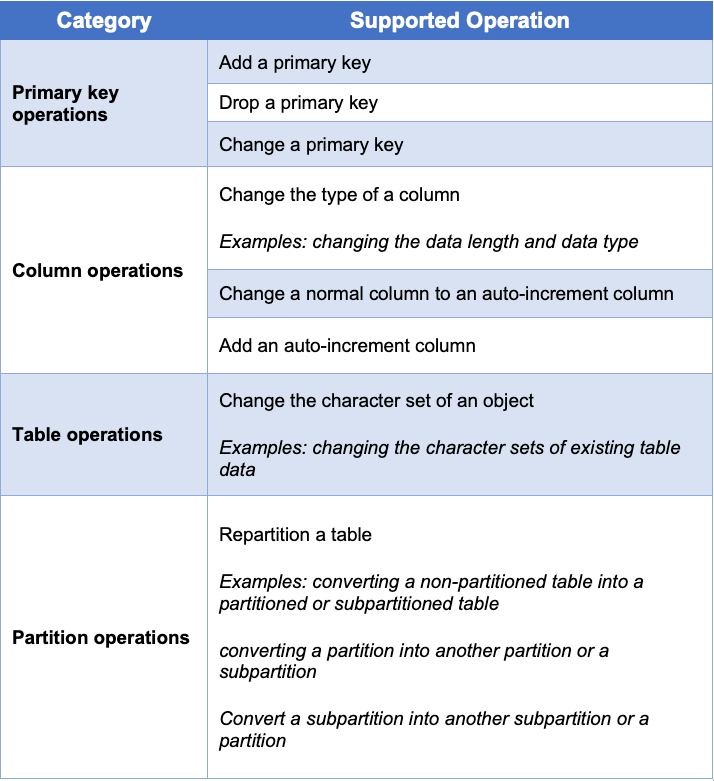
Table 3 New DDL operations supported in OceanBase 4.0
To better support these new operations, we have enhanced the native Online DDL feature by:
- Supporting the atomic change of a table with multiple dependent objects
- Significantly improving the data-completion performance of the native Online DDL
- Supporting the high-availability synchronization of the data generated by bypass imports
- Performing data consistency checks on the data of both a table and the dependent objects of the table to ensure the data consistency of DDL operations.
Atomic change that ensures synchronized data updates
The atomic change feature ensures that users see the updated table schema and data if the DDL operation succeeds, and the original table schema and data if the DDL operation fails. A data-rewrite DDL operation involves two jobs. First, the existing table data is modified based on the new table schema. Second, objects depending on the table, such as indexes, constraints, foreign keys, and triggers, are modified based on the new table schema.
In a distributed database, the data of a table may be distributed on different nodes, which brings two challenges:
- How to ensure the atomic change of the distributed data and dependent objects?
- How to ensure that users see only the updated table schema, given the fact that the latest update time of the table schema is different across nodes after the update is completed?
In response, we have designed a table schema change process to ensure the atomic change of the data and multiple dependent objects in a distributed environment, and users can query and perform DML operations on the table based on the latest table schema after a DDL operation.
The reason to ensure the atomic change is that unexpected database kernel exceptions may occur during a DDL operation. For example, we have a table with an INT-type column, which is used as a unique index. If we modify the column type to TINYINT and several values of the column exceed the range of the TINYINT type, all values of the rows where these invalid values reside will be truncated to the upper bound of the TINYINT type, resulting in duplicate values in the column, which does not meet the UNIQUE constraint. At this point, the data has been partially rewritten, and the DDL operation rolls back. The atomic change feature ensures that the user sees the original data rather than a messed-up table.
Parallel execution that improves data completion speed
Most distributed databases migrate data by simulating the insert operation. This method has two drawbacks. First, the operation may contend with general business requests for row locks. Second, the performance is significantly lower in comparison with a conventional standalone database due to the control of transaction concurrency, the control of thread safety of in-memory indexes, and multiple data writes.
To reduce the business impact of DDL operations and improve the DDL statement execution efficiency, OceanBase Database migrates data from the original table to the new table by using a method with distributed sorting and bypass writing, much like creating an index. Distributed sorting incurs less CPU overhead because fewer transactions are involved, the memory structure is maintained in order, and multiple compactions are avoided in the process. Bypass writing avoids data writes to MemTables and multiple compactions, which saves the memory and I/O overhead.
We have redesigned the distributed execution plan for data completion during DDL operations in OceanBase Database V4.0 based on the new parallel execution framework. The new plan has two parallel sub-plans. One consists of sampling and scanning operators and the other consists of sorting and scanning operators.

Figure 1 Distributed execution plan for data completion in OceanBase 4.0
This plan makes full use of distributed and standalone parallel execution capabilities:
The two parallel sub-plans may be scheduled at the same time based on the new framework and executed on multiple servers in a pipeline where the parallel sub-plan 1 returns rows to the parallel sub-plan 2 and then the rows are processed.
To prevent data skew among partitions, we split each partition into multiple slices, which are processed by different SORT operators. Each SORT operator will process the data of multiple partitions. As a sample division algorithm is applied, the split partition slices are roughly equal in size, so that the sorting workload is balanced across operators.
We have also adopted some techniques to improve the execution efficiency on a single server. For example, the vectorized engine is used for batch processing in the data completion process where possible; data writes to the local disk and data synchronization with other nodes are performed in parallel; more efficient sampling algorithms are applied; and a new framework is used for the static data engine to avoid the repeated copy of the row metadata. Those techniques help improve the performance of all operations involving data completion, such as index creation and data-rewrite DDL operations.
More stringent availability requirements
Distributed sorting and bypass writing significantly improve the performance of data completion. The question is, how to synchronize the bypass writes to backup follower replicas and standby clusters? OceanBase Database V4.0 supports the synchronization of bypass writes to SSTables to backup follower replicas and standby clusters over the Paxos protocol. During the data replay, only the data address and metadata of macroblocks in SSTables are replayed in the in-memory state machine. This solution has the following benefits:
- Bypass writes are highly available and the DDL execution is not affected when a minority of nodes crash.
- Bypass writes are compressed by data encoding and general-purpose compression algorithms. The data size is much smaller than the original table, leading to fast data synchronization.
- The data synchronization to the backup follower replicas and standby clusters is based on the same logic. No special coding is required.
Enhanced data consistency check
During a data-rewrite DDL operation, the data is migrated from the original table to a new table. The user data is expected to be consistent after the operation. OceanBase Database V4.0 performs consistency checks after a successful DDL operation to ensure data consistency and rolls back the DDL operation when an unexpected error occurs. Specifically, OceanBase Database V4.0 checks not only the new table, but also all of its dependent objects such as indexes, constraints, and foreign keys. A DDL operation succeeds only if the data of both the table and its dependent objects are consistent.
Hands-on testing of new DDL operations in OceanBase 4.0
Testing of new features
Perform primary key operations: Add/Drop/Change a primary key.
1. Add a primary key
OceanBase(admin@test)>create table t1(c1 int);
Query OK, 0 rows affected (0.18 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 add primary key(c1);
Query OK, 0 rows affected (1.28 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)2. Drop a primary key
OceanBase(admin@test)>create table t1(c1 int primary key);
Query OK, 0 rows affected (0.19 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 drop primary key;
Query OK, 0 rows affected (1.39 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)3. Change a primary key
OceanBase(admin@test)>create table t1(c1 int, c2 int primary key);
Query OK, 0 rows affected (0.18 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 drop primary key, add primary key(c2);
Query OK, 0 rows affected (1.38 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) NOT NULL,
PRIMARY KEY (`c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)Modify partitioning rules:
1. Convert a non-partitioned table into a partitioned table
-- Sample code
OceanBase(admin@test)>alter table t1 partition by hash(c1) partitions 4;
Query OK, 0 rows affected (1.51 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) DEFAULT NULL,
`c2` datetime DEFAULT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by hash(c1)
(partition p0,
partition p1,
partition p2,
partition p3) |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)2. Convert a non-partitioned table into a subpartitioned table
OceanBase(admin@test)>create table t1(c1 int, c2 datetime);
Query OK, 0 rows affected (0.18 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (1.96 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) DEFAULT NULL,
`c2` datetime DEFAULT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by range(c1) subpartition by key(c2) subpartition template (
subpartition p0,
subpartition p1,
subpartition p2,
subpartition p3,
subpartition p4)
(partition p0 values less than (0),
partition p1 values less than (100)) |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.04 sec)3. Convert a partition into another partition
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2))
-> partition by hash(c1) partitions 4;
Query OK, 0 rows affected (0.20 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 partition by key(c1) partitions 10;
Query OK, 0 rows affected (1.84 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` datetime NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by key(c1)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4,
partition p5,
partition p6,
partition p7,
partition p8,
partition p9) |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)4. Convert a partition into a subpartition
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2))
-> partition by hash(c1) partitions 4;
Query OK, 0 rows affected (0.19 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (1.88 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` datetime NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by range(c1) subpartition by key(c2) subpartition template (
subpartition p0,
subpartition p1,
subpartition p2,
subpartition p3,
subpartition p4)
(partition p0 values less than (0),
partition p1 values less than (100)) |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)5. Convert a subpartition into a partition
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2)) partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (0.23 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 partition by key(c1) partitions 10;
Query OK, 0 rows affected (1.98 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` datetime NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by key(c1)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4,
partition p5,
partition p6,
partition p7,
partition p8,
partition p9) |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)6. Convert a subpartition into another subpartition
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2)) partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (0.24 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 partition by hash(c1) subpartition by key(c2) subpartition template(subpartition sp0, subpartition sp1, subpartition sp2) PARTITIONS 5;
Query OK, 0 rows affected (2.07 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` datetime NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by hash(c1) subpartition by key(c2) subpartition template (
subpartition sp0,
subpartition sp1,
subpartition sp2)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4) |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)Change the type of a column: Users can change the data length and data type of a column, change a normal column to an auto-increment column, and change the character set of a column.
1. Shorten the data length of a column
OceanBase(admin@test)>create table t1(c1 varchar(32), c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.19 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 modify c1 varchar(16);
Query OK, 0 rows affected (1.47 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` varchar(16) NOT NULL,
`c2` int(11) NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)2. Increase the data length of a column
OceanBase(admin@test)>create table t1(c1 varchar(32), c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.17 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 modify c1 varchar(48);
Query OK, 0 rows affected (0.17 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` varchar(48) NOT NULL,
`c2` int(11) NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)3. Change the data type of a column
OceanBase(admin@test)>create table t1(c1 int, c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.17 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 modify c1 varchar(48);
Query OK, 0 rows affected (1.38 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` varchar(48) NOT NULL,
`c2` int(11) NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)4. Change a normal column to an auto-increment column
OceanBase(admin@test)>create table t1(c1 int, c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.18 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 modify c1 int auto_increment;
Query OK, 0 rows affected (0.58 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL AUTO_INCREMENT,
`c2` int(11) NOT NULL,
PRIMARY KEY (`c1`, `c2`)
) AUTO_INCREMENT = 1 AUTO_INCREMENT_MODE = 'ORDER' DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)5. Change the character set of a column
OceanBase(admin
@test
)>create table t1 (c1 int, c2 varchar(
32
), c3 varchar(
32
), primary key (c1), unique key idx_test_collation_c2(c2));
Query OK, 0 rows affected (0.24 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 modify column c2 varchar(32) charset gbk;
Query OK, 0 rows affected (2.12 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` varchar(32) CHARACTER SET gbk DEFAULT NULL,
`c3` varchar(32) DEFAULT NULL,
PRIMARY KEY (`c1`),
UNIQUE KEY `idx_test_collation_c2` (`c2`) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.05 sec)Change a character set
- Change the character sets of existing table data
OceanBase(admin@test)>create table t1 (c1 int, c2 varchar(32), c3 varchar(32), primary key (c1), unique key idx_test_collation_c2(c2));
Query OK, 0 rows affected (0.23 sec)
-- Sample code
OceanBase(admin@test)>alter table t1 CONVERT TO CHARACTER SET gbk COLLATE gbk_bin;
Query OK, 0 rows affected (2.00 sec)
-- Operation check
OceanBase(admin@test)>show create table t1;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` varchar(32) COLLATE gbk_bin DEFAULT NULL,
`c3` varchar(32) COLLATE gbk_bin DEFAULT NULL,
PRIMARY KEY (`c1`),
UNIQUE KEY `idx_test_collation_c2` (`c2`) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = gbk COLLATE = gbk_bin ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.05 sec)Performance testing
We have tested the performance of DDL execution by creating indexes. In the test, a number of data rows are imported into a table and the time consumption of index creation is measured. As a large part of the time is consumed for data completion, we can evaluate the data completion performance of the tested databases.
Configuration
1. Table schema: create table t1(c1 int, c2 varchar(755)) partition by hash(c1) partitions 10
2. Data volume: 10 million rows
3. Resource configuration: one server, with the degree of parallelism set to 10 and the memory for sorting to 128 MB
4. Test scenarios:
create index i1 on t1(c1) global;
create index i1 on t1(c2) global;
create index i1 on t1(c1,c2) global;
create index i1 on t1(c2,c1) global;
5. Test metric: time consumption of index creation, in seconds
6. Tested databases: a standalone MySQL database, a distributed database A, and OceanBase 4.0
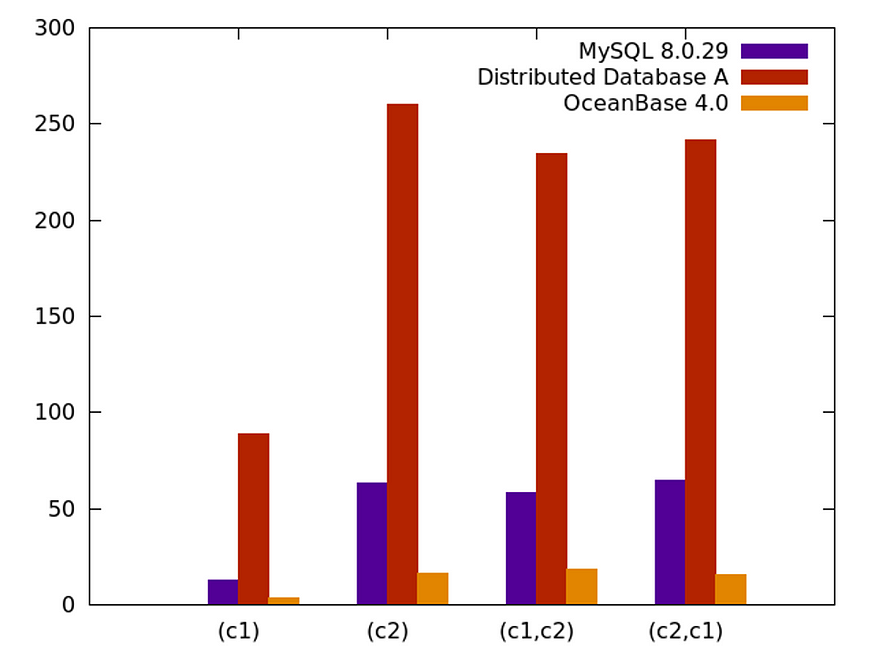
Figure 2 Performance comparison
As shown in the figure above, OceanBase Database creates the index 10–20 times faster than database A, and 3–4 times faster than MySQL. Note that data completion is performed by simulating the insert operation in database A. Apparently, data completion by sorting and bypass writing significantly improves the performance of index creation. On the other hand, we have optimized the single-server performance of OceanBase 4.0, which therefore finishes data completion much faster than MySQL.
OceanBase 4.0 supports common data-rewrite DDL operations, such as changing primary keys, column types, and character sets, and modifying partitioning rules. We hope that the atomic change feature, enhanced data consistency check, and high-availability data synchronization can help users complete the required change by simply executing a DDL statement, without worrying about exceptions in the distributed environment. We have also improved the distributed and standalone parallel execution capabilities to speed up data completion during DDL operations.
Hopefully, the DDL optimizations of OceanBase 4.0 can help users cope with changing business challenges with ease.

