
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Beyond Fine-tuning: Solving DABstep's Hard Mode with Versioned Assets

- OceanBase DataPilot tops the DABstep financial reasoning leaderboard — not with a bigger model, but by shifting from prompt engineering to asset engineering: versioned SOPs, validated code templates, and metric definitions managed like code, not disposable context.
- A train-free GRPO mechanism drives iteration: the agent forks competing logic branches, benchmarks them against golden answers, and promotes winners to trunk — solving ambiguity, dirty-data crashes, and timeout failures without retraining.
- The infrastructure requirement is ACID for agents: OceanBase's unified relational + vector + full-text engine ensures knowledge updates are atomic and context assembly is a single hybrid SQL query, eliminating the state-drift risk of stitched-together stacks.
How OceanBase implemented a Train-Free GRPO mechanism to achieve SOTA on real-world financial reasoning
We are witnessing a paradox in the LLM landscape. While models are becoming reasoning giants, their deployment in high-stakes environments—financial analysis, risk control, and DevOps—often hits an invisible wall. The model seems to "understand" the prompt, yet the SQL it generates misses subtle business logic, the Python script it writes crashes on dirty data, and its definition of metrics drifts between conversations.
This reality was quantified in February 2025 by Adyen and Hugging Face with the release of Data Agent Benchmark for Multi-step Reasoning (DABstep). Derived from 450+ real-world financial tasks, it exposes the gap between academic benchmarks and production reality. The result? Even top-tier reasoning models like o3-mini and DeepSeek-R1 hovered around 13%-16% accuracy on the "Hard" subset.
However, on the DABstep Global Leaderboard, OceanBase’s DataPilot agent has secured the top spot, maintaining a significant lead over the runner-up for a month. The secret to our SOTA results wasn't a larger model or more GPU hours. It was a fundamental shift in engineering paradigm: moving from "Prompt Engineering" to "Asset Engineering."
This post details how we built a agent platform that actually resolves the agent gap in real-world financial reasoning.
What is OceanBase DataPilot?
Before diving into the mechanics, it helps to understand the platform: DataPilot is OceanBase's intelligent NL-to-SQL and insight platform. It allows developers to build specific "analysis domains," automates the configuration of semantic layers, and provides natural language-driven analytics. DataPilot wraps these capabilities in granular permission controls and audit trails, moving beyond a simple chatbot to a governed data workspace.
The Challenge: Why "Hard Mode" is Just "Real Mode"
DABstep reveals three distinct constraints that break standard Text-to-SQL or RAG approaches in production:
issuer_country, acquirer_country, and ip_country. A standard model guesses based on probability. In finance, guessing is fatal.NULL. It’s None, [], "", or "N/A". Generated Python scripts often lack the defensive programming to handle these, causing KeyError or TypeError crashes.O(R * T)(R= number of rules, T= number transactions) nested loop might work on a CSV sample but times out on millions of transaction rows.The Solution: From Ephemeral Context to Versioned Asset
To bridge the gap between probabilistic models and deterministic business requirements, we architected DataPilot around a strict separation of concerns: the Asset Plane and the Runtime Plane.
Architecture Breakdown
This diagram maps DataPilot’s Asset Loop into four executable modules:
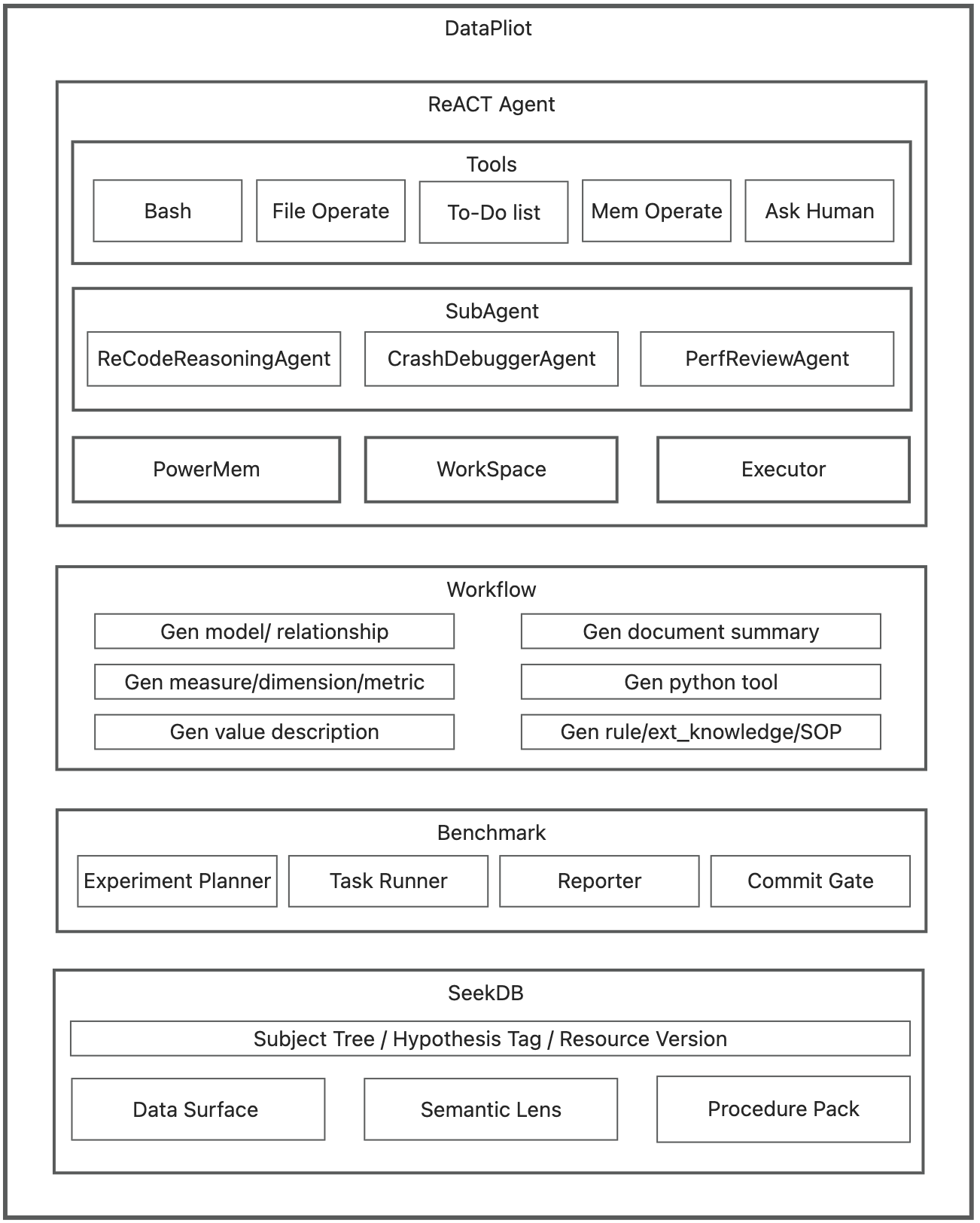
The single entry point for both Build and Runtime phases. It orchestrates tool execution and sandbox environments. When facing ambiguity, it triggers sub-agents to generate competing Hypothesis Implementations (e.g., multiple logic variants for a single metric).
The bridge between conversation and code. It structures loose outputs—conclusions, definitions, and SOPs—into formal resources. Crucially, it applies strict metadata to every asset:
The engine responsible for storage and retrieval. It supports dual-mode access: Precise Recall via tags (to fetch specific versions) and Semantic Assembly via vector search (to build open-ended context).
This component treats Hypothesis Tags as A/B test groups. It executes batch evaluations across different logic branches, calculates a success score, and automatically promotes the winning context to the Trunk (Default Version), ensuring the system self-optimizes over time.
Instead of treating context as disposable text found via RAG, we manage it like versioned code.
The system operates as a continuous loop: Assets are retrieved to form a context, the agent executes the task, and the result is evaluated. Only successful patterns are written back to memory.
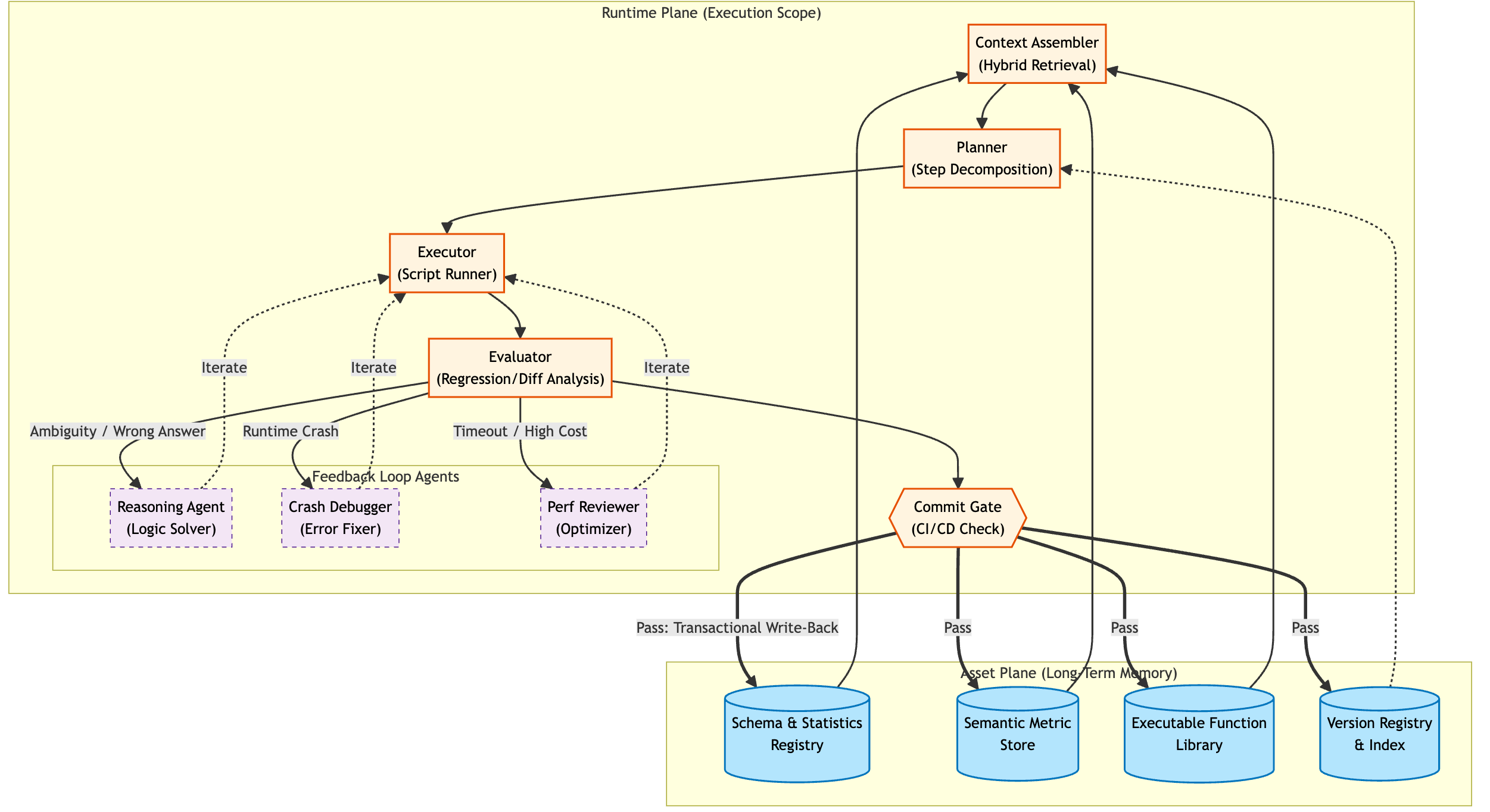
The 3-Layer Asset Structure
We structure knowledge into three distinct layers to handle specific types of failure modes:
Layer 1: Schema & Statistics Registry (The "Data Surface")
Country is misleading; it actually contains IP addresses, not ISO code"Layer 2: Semantic Metric Store (The "Business Logic Layer")
issuer_country == acquirer_country, ignoring IP."Layer 3: Executable Function Library (The "Robustness Primitives")
The Implementation: Train-Free Asset Iteration (GRPO for Context)
As the core of our engineering strategy, we adapted the Group Relative Policy Optimization (GRPO, normally used for model training)—and applied it to Context Engineering rather than model weights.
In standard GRPO, you generate a group of outputs, score them, and update the model's neural parameters. In our Train-Free approach, we update the Asset Plane. This allows the system to "learn" from its mistakes instantly without expensive re-training cycles.
The Feedback Loop: Branch, Bench, Promote
The iteration cycle follows a strict "Branch Generation — Tagged Evaluation — Trunk Promotion" pattern:
1. Branch Generation
When the ReACT Agent encounters ambiguity or missing logic, it explicitly forks the execution path. Sub-agents (like the ReCodeReasoningAgent) generate multiple candidate implementations. These variants are written to seekdb as structured assets, strictly versioned via Subject Tree and Hypothesis Tag metadata.
2. Tagged Control Evaluation
The Benchmark engine executes a controlled A/B test. It runs the identical regression suite against each Hypothesis Tag. By injecting specific tags during the retrieval phase, we isolate the variable: same task, same logic, different context. This produces an explainable, comparative score for every branch.
3. Trunk Promotion
Based on multi-objective metrics (Accuracy, Robustness, Cost), the system selects the optimal branch. The associated assets are promoted to the Default Trunk, making them the standard for future queries. Lower-scoring branches are archived—inactive but retained for traceability and rollback.
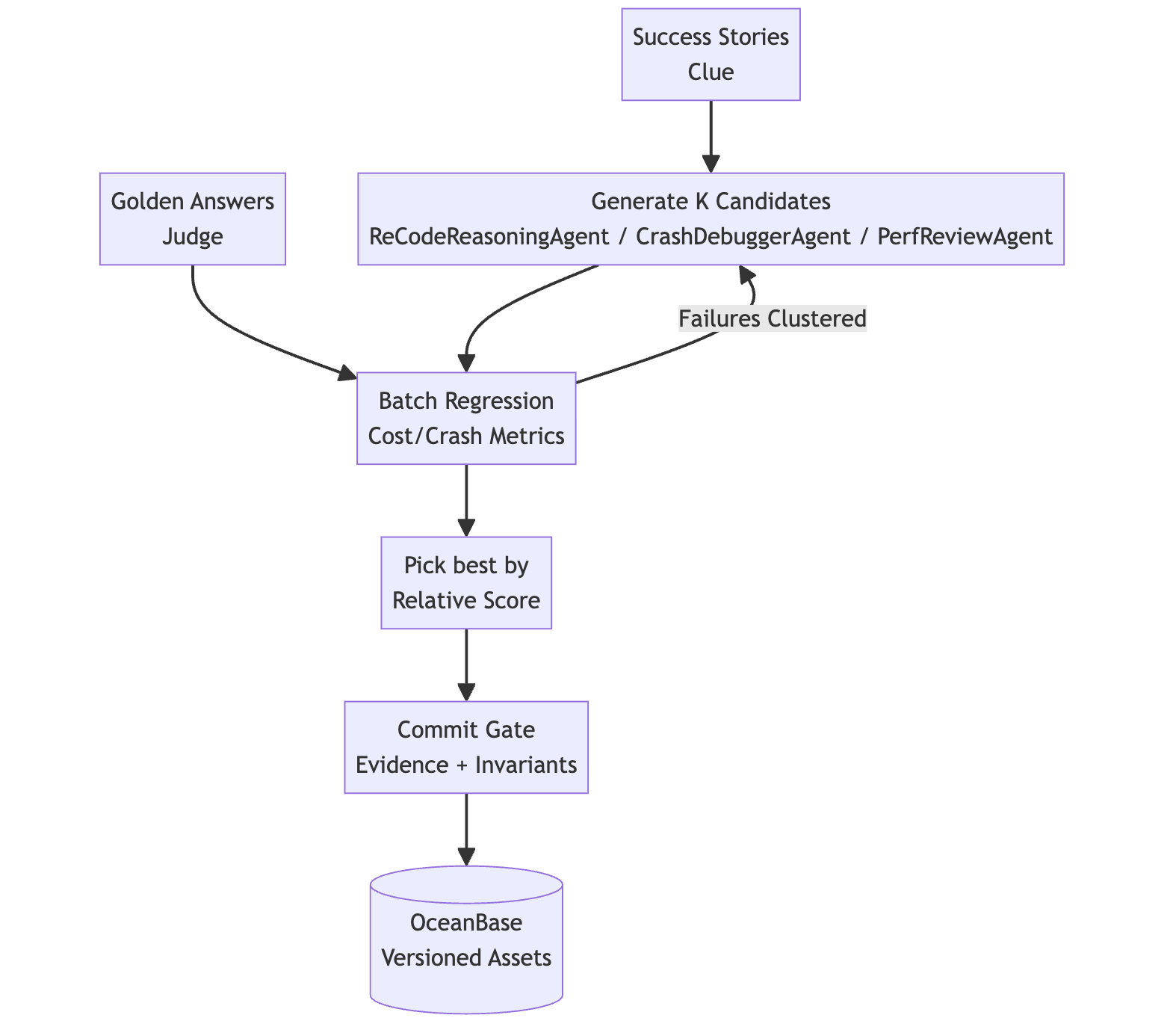
To prevent "brain damage" (regressions) in the long-term memory, the Commit Gate strictly enforces three invariants before any write to OceanBase.
Three Evolutionary Loops: Solving the "Real-World" Triad
We apply this methodology to solve the three specific pain points identified in DABstep.
Loop 1: The Logic Loop (Solving Ambiguity)
Loop 2: The Robustness Loop (Solving Crashes)
Loop 3: The Efficiency Loop (Solving Timeouts)
merge or SQL JOIN).These three loops reveal the essence of the DataPilot architecture: we stop the LLM from reasoning from scratch.
By solidifying "What data looks like" (Layer 1), "How business is defined" (Layer 2), and "How code is executed" (Layer 3) into assets, we ensure that every new query starts with a highly informed context.
The Implementation Pattern
Crucially, this system generalizes:
safe_in establishes a pattern for handling other edge cases, such as division-by-zero or type casting errors.Ultimately, our top ranking on DABstep isn't because our model is smarter; it's because we built a mechanism to make the model smarter. Through three-layer asset management, we transform implicit reasoning into explicit rules. Through "Success Stories" and "Golden Answers", we persist ephemeral success into long-term memory. And through Hybrid Search and Transactional Write-back, we systematize fragmented knowledge. The result is a system that doesn't just answer a single question correctly—it learns how to solve a class of questions.
The Infrastructure: Why We Need "ACID for Agents"
Managing this architecture requires more than a simple Vector Database. A fragmented stack (MySQL for metadata + Pinecone for vectors + Redis for cache) introduces a fatal flaw for Agents: State Drift.
If you update a metric definition in the vector index but fail to update the corresponding SQL schema in the relational DB, the Agent hallucinates.
We utilized OceanBase because it offers a unified engine for Relational Data + Vector + Text, with the following benefits:
Unified Multi-Model Architecture
Startups often stitch together a "Franken-stack" (e.g., MySQL for metadata, Elasticsearch for docs, Milvus for vectors). This causes latency and consistency nightmares. OceanBase is a converged engine that handles relational tables, unstructured text, and vector embeddings in a single process. This ensures physical consistency across all data modalities without network overhead.
Native Hybrid Search via SQL
For an agent, context retrieval is never just vector similarity; it’s a complex composite query. OceanBase unifies various data types (relational, vector, text, JSON, and GIS) within a single engine and allows developers to combine vector search, full-text search and relational query in a single SQL statement. It eliminates complex application-level merge-sorting, achieving millisecond-level latency for context assembly.
Transactional "Memory" Commit (ACID)
Updating an Agent's long-term memory is a multi-step operation: updating the registry, storing the new code snippet, and logging the regression evidence. If these happen in separate systems, a partial failure leads to a "corrupted state" (e.g., the index points to code that doesn't exist). OceanBase enforces ACID transactions on knowledge updates. Either the entire knowledge package acts atomically, or it rolls back completely, ensuring the Agent's memory is always in a valid, traceable state.
Conclusion: The Shift to Asset Engineering
The DABstep results prove a critical lesson for the industry: in specialized, high-stakes domains, generalization comes from Architecture, not just Scaling.
OceanBase’s victory validates three specific technical decisions that transform the probabilistic nature of LLMs into a deterministic engineering workflow:
We are currently integrating this entire "Agent Engineering" stack—including the 3-Layer Asset Manager, Hybrid Search Engine, and Automated Regression Runner—directly into the upcoming release of OceanBase DataPilot. Stay tuned.



Keep Reading
View all posts
From Complex to Simple: How We Built seekdb for the AI Era
AI era doesn't need another heavy, complex enterprise database. It needs agility. It needs flexibility. We went back to the drawing board to understand what an AI application actually needs from a database. Our answer is OceanBase seekdb



Use OceanBase in Node.js: Build a CRM with Sequelize and Express
Welcome to the latest episode in our series of articles designed to help you get started with OceanBase, a next-generation distributed relational database. Building on our previous guides where we connected OceanBase to a Sveltekit app and built an e-commerce app with Flask and OceanBase, we now ...


Permanent Server Offline in OceanBase: How the Cluster Heals After a Node Is Gone
How OceanBase distinguishes a transient outage from a permanent loss, and why operators should intervene rather than wait for the automatic re-replication timer.
