







A Game Company‘s Database Transformation: Replace ClickHouse and Hive with OceanBase Database




Author: Big Data Platform Leader form a Leading Game Company
Introduction: A complex architecture is a silent hazard that keeps growing, especially in massive data processing scenarios, and results in system bottlenecks, module interference, data redundancy, and maintenance nightmares. A game company found itself in this exact pickle and partnered with OceanBase to build an integrated data warehouse that supports both data storage and real-time analysis. In this article, the company's big data platform leader walks us through their challenges, solution selection process, and the bumpy road of solution implementation.
Background: Data Analysis, Processing, and Operations Based on a Complex Data Warehouse Architecture
We're a game company that has shifted our priorities from game development to operations. Data analysis is crucial for game companies, so the capabilities of an analytical system are extremely important to us. We primarily use data warehouse tools to analyze user behaviors (downloads, registrations, and payments), advertising and marketing data, and game data such as user levels and battle parameters.
Like most companies, our data warehouse was built in a typical Lambda architecture, as shown in Figure 1. We'd collect data from sources, preprocess it (including data quality control and cleaning), and then cache it in Kafka. Then, some data was sent to a Hive data warehouse for offline processing and some other data was sent to a ClickHouse data warehouse for real-time analysis by scheduled tasks. The analysis results were fed to various application systems, such as the business intelligence system, user system, and marketing system, as well as third-party platforms like Baidu, Tencent, Toutiao, and Douyin.
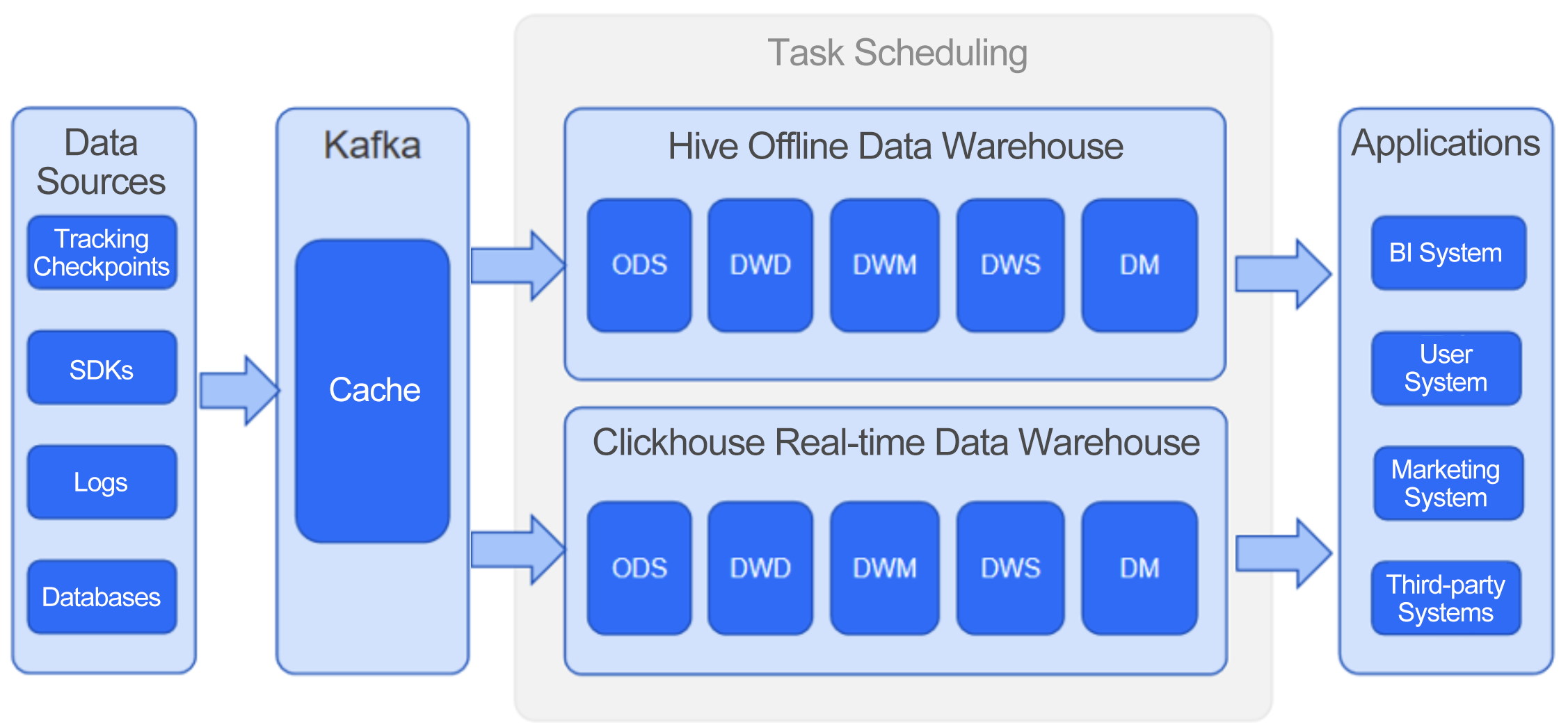
Figure 1 Architecture of our original data warehouse
Our original data warehouse would perform data parsing and quality control after data collection, and then trigger alerts against the collected data with quality issues, such as missing fields and incorrect field types. A unique aspect of data processing in the gaming industry is data attribution, which essentially means to analyze the data collection process in detail to identify the channels and ad slots that generated specific data. Future advertising and marketing strategies depend on data attribution. Our data processing also involved data broadening, a common data warehouse scenario, where IP addresses were parsed to display user location, and other user details such as their mobile device model, age, and gender could be obtained and fed to both offline and real-time data warehouses to support user profiling.
Challenges: Real-time Performance, Data Consistency, Maintainability, and Query Efficiency
Our original data warehouse architecture consisted of multiple layers, such as the operational data store (ODS) layer, data warehouse detail (DWD) layer, data warehouse middle (DWM) layer, data warehouse service (DWS) layer, and data mart. After quality checks, raw data was written into the ODS layer of the Hive and ClickHouse data warehouses. Kafka and the ODS layer contained the same data, and Kafka was technically a part of the ODS layer. Then, the task scheduling system would perform data broadening, store data details in the DWD layer, and carry out metric aggregation in the DWM and DWS layers before sending the results to data marts built on PostgreSQL and Redis. The in-house task scheduling system was quite powerful. It could perform, for example, source dictionary and data quality management, task rerunning, task priority adjustment, and quality issue alerting. The original architecture was quite advanced back then. However, we encountered significant challenges.
Challenge 1: real-time performance. While many companies adopted the T+1 data warehouse strategy, we optimized the Hive data warehouse, and could get analysis results 30 minutes after data generation. In other words, we would load the data once every 30 minutes, write it to Hive, and then execute the INSERT OVERWRITE statement to store the data to the partition of that day. This method could reduce data fragmentation. The real-time ClickHouse data warehouse, on the other hand, could output results within 1 minute after data generation. However, we needed to see results in milliseconds in some scenarios, which was far beyond what Hive or ClickHouse could achieve.
Challenge 2: data consistency. Lambda architecture users know that ClickHouse and Hive often generate inconsistent data. The same issue bothered us despite our data deduplication measures. As a result, we used the data from ClickHouse for real-time queries, and that from Hive for final data consumption.
Challenge 3: maintainability. Apparently, it's not that easy to maintain two code systems in the same architecture.
Challenge 4: query efficiency. Hive took about 10 minutes or more to return query results, while ClickHouse took from a few seconds to a few minutes. Such performance was fine in most cases, but would be unacceptable in the following two scenarios:
- Federated queries for user identity. Users may associate their accounts with their identity card numbers. For queries of accounts by identity card number, the query results should be returned in a few milliseconds. We stored user information in a MySQL database, which had no problem meeting that response time if a small amount of data was queried. However, the MySQL database became sluggish or even unavailable if millions or billions of data records were involved.
- Federated queries for advertising channels. In this scenario, we needed to perform federated queries on the order data, user data, and advertising information. The original architecture took 30 minutes to generate the advertising result, while we wanted to view the result within 1 second.
These challenges pushed us to explore new data warehouse solutions.
Database Selection: A Significant Performance Boost Brought by OceanBase Database
We researched Hudi and Doris. From data writes to returning the result of a JOIN query, Hudi took at least 60 seconds, while Doris took 10-60 seconds. Compared to ClickHouse, which took about 66 seconds to return the query result, as shown in Figure 2, the performance of Hudi or Doris was not a remarkable improvement, and could hardly meet our business needs.

Figure 2 ClickHouse took about 66 seconds to return the query result
During our tool research, we learned about OceanBase Database, a database system that is capable of hybrid transaction and analytical processing (HTAP), and tested its query speed of retrieving user account IDs by identity card number. We only created indexes on the tables under test instead of creating partitions, and we performed a total of 120 million queries on 3.4 billion data rows. As shown in Figure 3, the first test returned the query results in 0.23 seconds, meaning that the performance was improved by 286 times. The query results were returned even in 0.01 seconds after the data was preloaded. A quite thrilling performance boost, right?

Figure 3 OceanBase Database returned the query result within a few milliseconds
The test result immediately convinced us to deploy OceanBase Database for our key business needs, such as user account ID retrievals by identity card number, user ID-based advertising information retrievals, and real-time tracking of marketing results.
Production Deployment: Data Write Optimization and Challenges to Data Import
We manage historical and real-time data separately in OceanBase Database.
- Historical data: Using DataX, we exported historical data into CSV files, and then imported the CSV files into OceanBase Database.
- Real-time data: Expecting a query response in milliseconds, we selected Flink SQL to extract real-time data. We performed a test and the test result showed that Flink SQL can deliver data to OceanBase Database within 1 second from data generation.
As a first-time user, we encountered some difficulties during historical data import, and many were resolved with the assistance of OceanBase technical experts on DingTalk (group ID: 33254054). Personally, I suggest connecting to OceanBase Database directly through port 2881 if you export data into CSV files. If you use port 2883, OceanBase Database is connected through OceanBase Database Proxy (ODP), which may distribute commands to a server where DataX is not deployed and CSV files are not stored.
We considered using Spark for real-time data writes. Spark writes data in micro-batches with an inter-batch latency of up to 300 ms, while Flink supports real-time data writes to OceanBase Database. So, we selected Flink SQL to do the job.
The following three screenshots show how Flink performs the extract-transform-load (ETL) process and writes data to OceanBase Database.
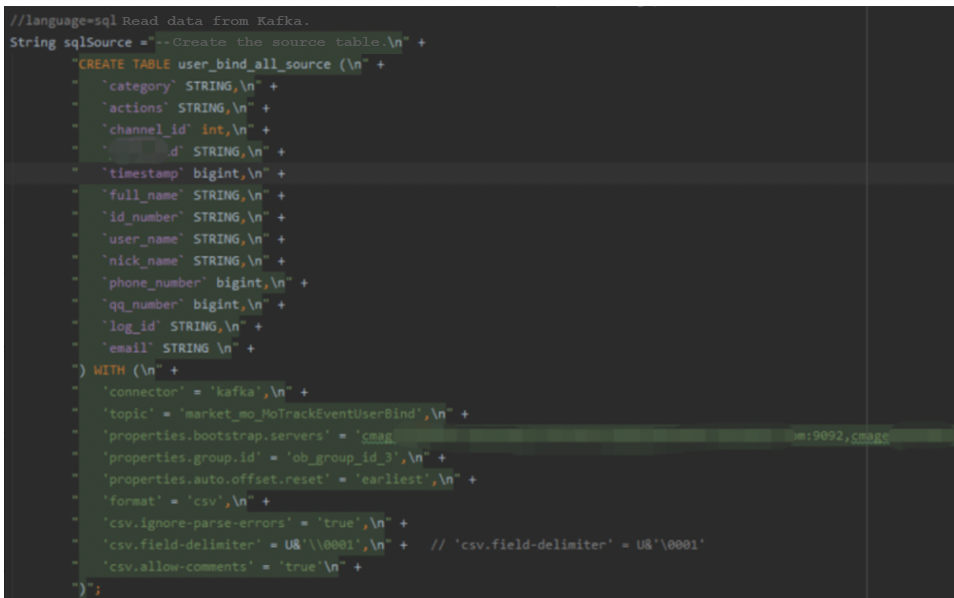
Figure 4 Extracting real-time data from Kafka
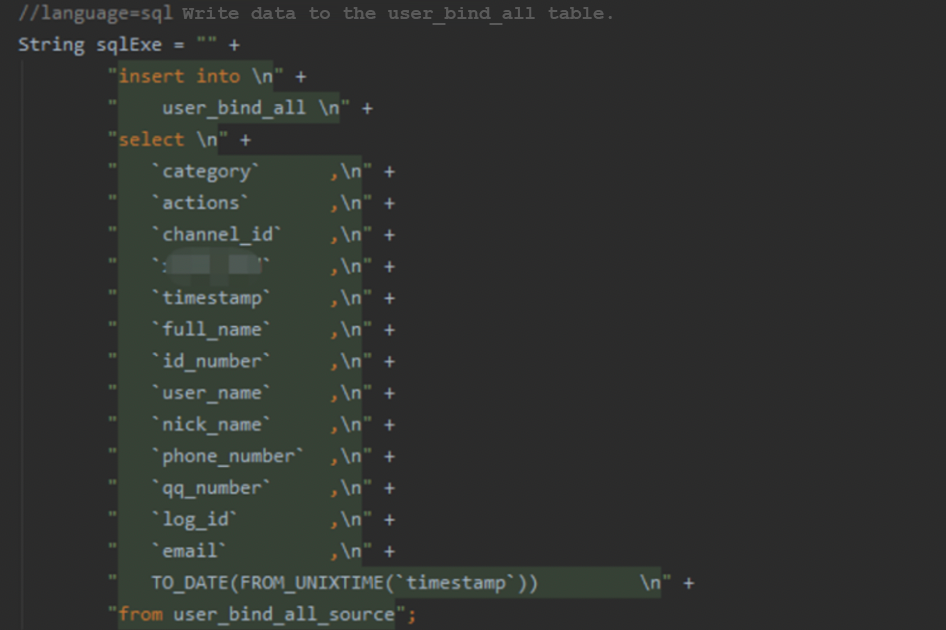
Figure 5 Performing the ETL process of real-time data
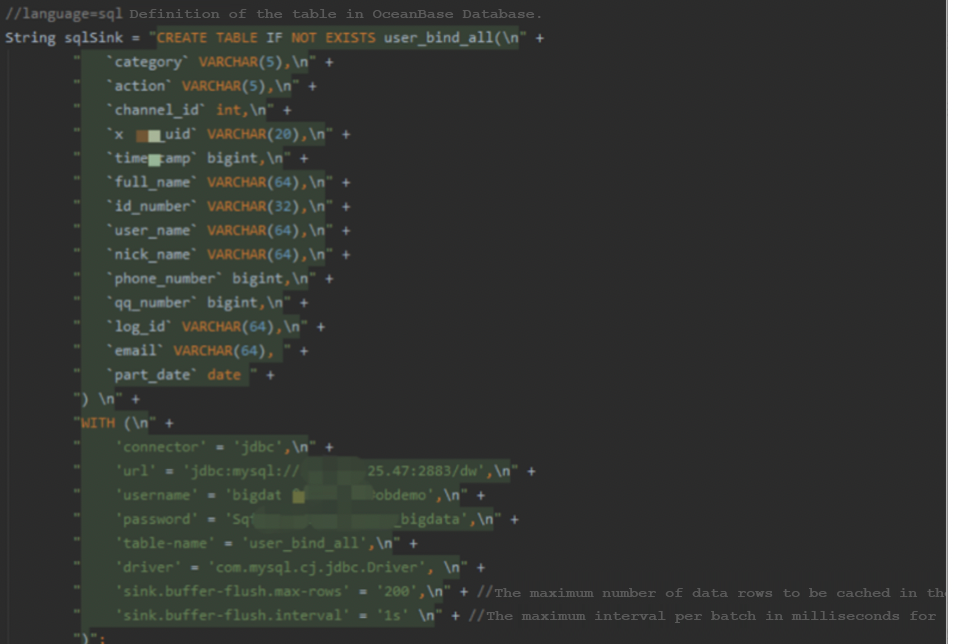
Figure 6 Loading processed data into OceanBase Database in real time
I converted the process into a batch commit script, which enables Flink to synchronize data to our new real-time data warehouse based on OceanBase Database from multiple sources, such as Kafka, MySQL, Oracle, OceanBase Database, MongoDB, PostgreSQL, and SQL Server.
The preceding code has been implemented in our production environment to support two scenarios: user account ID retrievals by identity card number, and data attribution, so that we can learn about, for example, the advertising channel that attracted a user. The following figure shows the position of OceanBase Database in our business system.
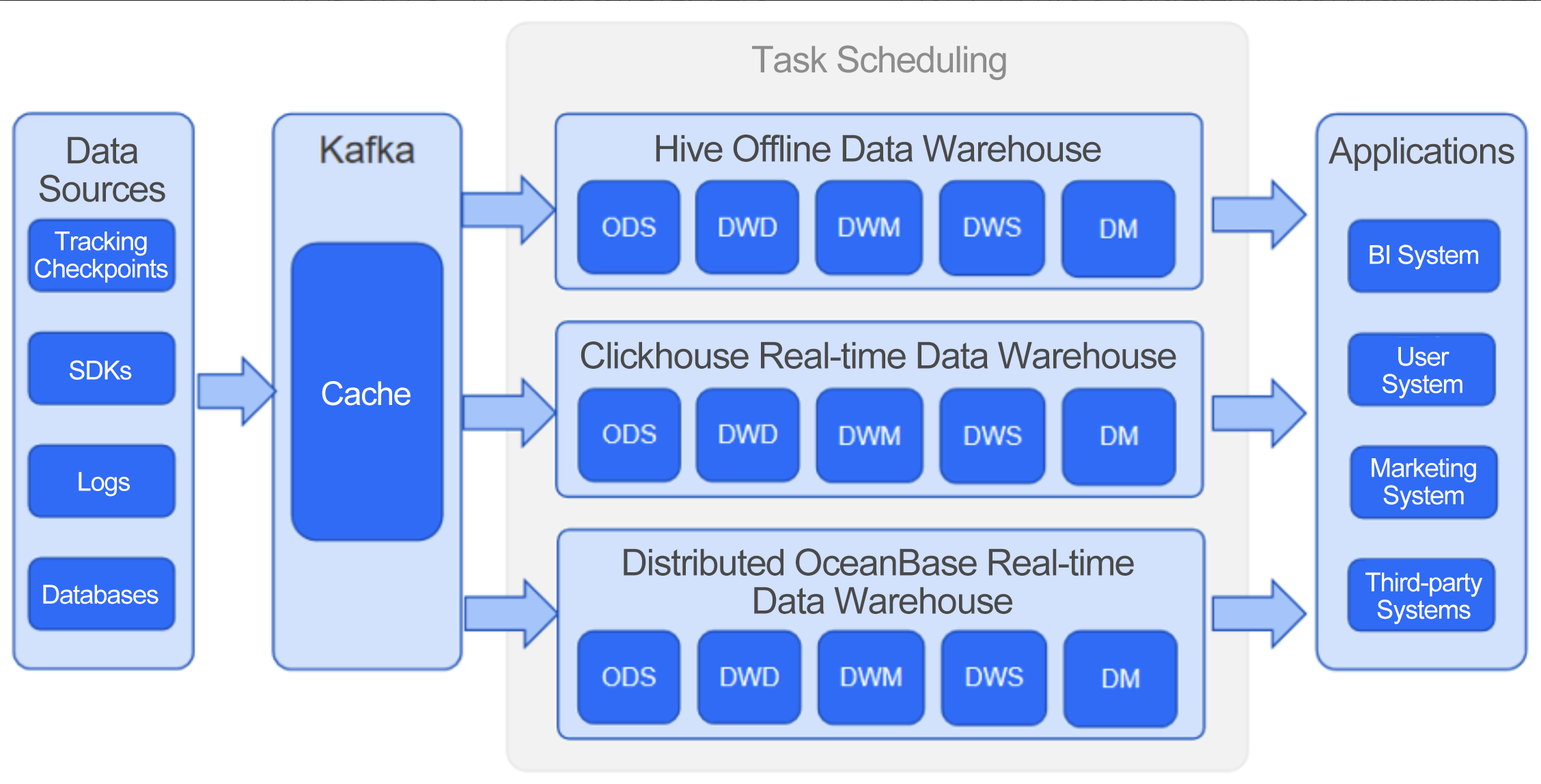
Figure 7 Architecture of our data warehouse with OceanBase Database
Summary: An All-in-one System Supporting Both TP and AP
OceanBase Database has solved the aforesaid challenges to our business systems.
- Real-time performance: The real-time performance of data write and export is no longer a problem. Flink SQL extracts real-time data from Kafka and writes it into OceanBase Database in real time. We hope OceanBase can offer better versions of the OceanBase Change Data Capture (obcdc) tool and improve the flink-sql-connector-OceanBase-cdc tool to better support the reprocessing of historical data. We are also looking forward to an OceanBase-specific Flink connector, which writes data to OceanBase Database efficiently without data duplication or loss. This way, we can process data in the second and third layers of the data warehouse and extend the OceanBase ecosystem to big data, achieving storage/computing splitting in a big data environment.
- Data consistency: OceanBase Database has been working greatly with all historical and real-time data of our business system with zero data duplication and loss.
- Query efficiency: In the database selection test, we only created indexes on the tables under test without creating table partitions. A test that involved 120 million queries on 3.4 billion data rows returned the results in 0.23 seconds, meaning that the performance was improved by 286 times. After the data was preloaded, the query results were returned even in 0.01 seconds.
- Maintainability: We will phase out ClickHouse and Hive and gradually migrate all our core systems to OceanBase Database, making use of both TP and AP capabilities in a simplified architecture.
Next, we will migrate our user system, advertising system, data analysis system, and marketing and channel management system to OceanBase Database, as shown in Figure 8. We have already started code development and data adaptation. The ideal solution is to preserve and analyze all business data in OceanBase Database, handling all needs in one database system.
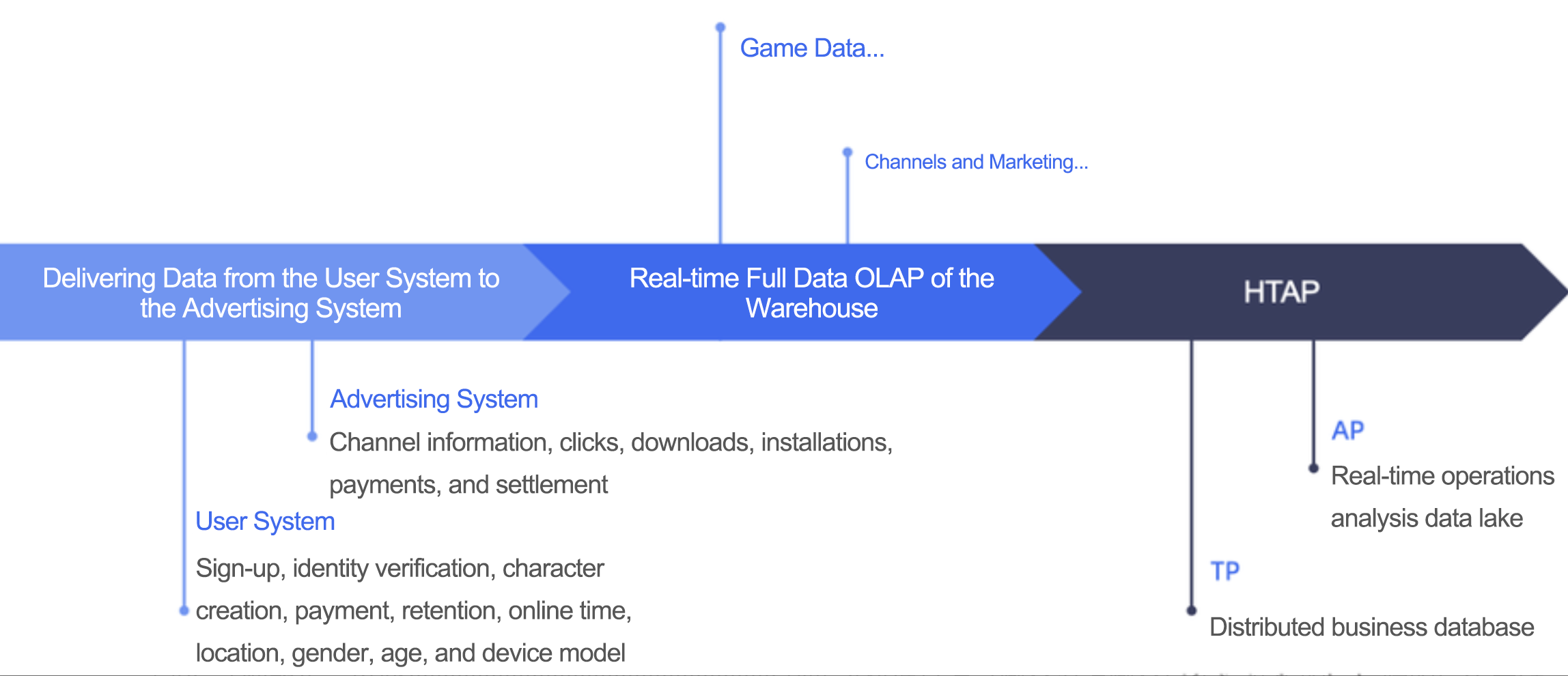
Figure 8 Migrating more business systems to OceanBase Database
This journey with OceanBase Database has brought numerous surprises. As the saying goes, "A journey of a thousand miles begins with a single step." Only by constantly trying can we reach ambitious goals previously thought impossible. To conclude, we sincerely wish OceanBase Database a better future.

