

















OceanBase Database implements the shared-storage (SS) model on general-purpose object storage. Unlike the shared-nothing (SN) model, where computing nodes and data storage are integrated, the SS model separates computing nodes from data storage. This allows for on-demand storage resource purchases and flexible scaling of computing nodes, achieving optimal resource elasticity and cost savings.
What is a separation-of-storage-and-compute architecture?
Shared storage forms the foundation for Cloud Native databases. Multiple computing nodes within a cluster utilize shared storage technology to decouple storage and computing, enabling separate layers for each. Full data is stored on object storage, while each computing node caches hot data locally. Typically, the cache hit rate is less than 100%, but for workloads that clearly separate hot and cold data, the hit rate can reach 99-99.9%. Latency for cache hits remains comparable to integrated storage computing architecture, but some requests still access object storage, with delays exceeding 80 ms. Therefore, the architecture is suitable for workloads that tolerate moderate latency jitter but not ultra-sensitive applications. This design reduces storage costs and allows independent scaling of computing and storage layers, providing greater flexibility.
Advantages of the architecture
- Low cost:
- Reducing storage costs by using low-cost object storage as the primary storage medium.
- Separates data storage from computing, enabling high availability based on a single data replica.
- Independent elastic resource management: Storage resources can be expanded and contracted independently of computing resources to optimize hardware resource utilization. Rapid horizontal scaling: Data does not need to be physically migrated when scaling computing resources horizontally.
- High availability: RPO=0, single-replica RTO in minutes, multi-replica RTO <= 8s.
Technical characteristics
- Independent scaling: Compute resources and storage resources can be independently scaled to meet business requirements.
- High availability: Storage layers typically use distributed storage systems that offer better data reliability and disaster recovery capabilities.
- Resource isolation: Computing tasks and storage tasks are independent, reducing resource contention and improving overall system stability.
- Elastic scaling: Decoupling of compute and storage layers, compared with an integrated computing and storage architecture, reduces the storage cost and makes it possible to independently scale compute and storage layers to achieve flexible scalability.
Use Cases
This feature is suitable for big data scenarios where the cold and hot data are clearly separated, and the system is not sensitive to delay jitters.
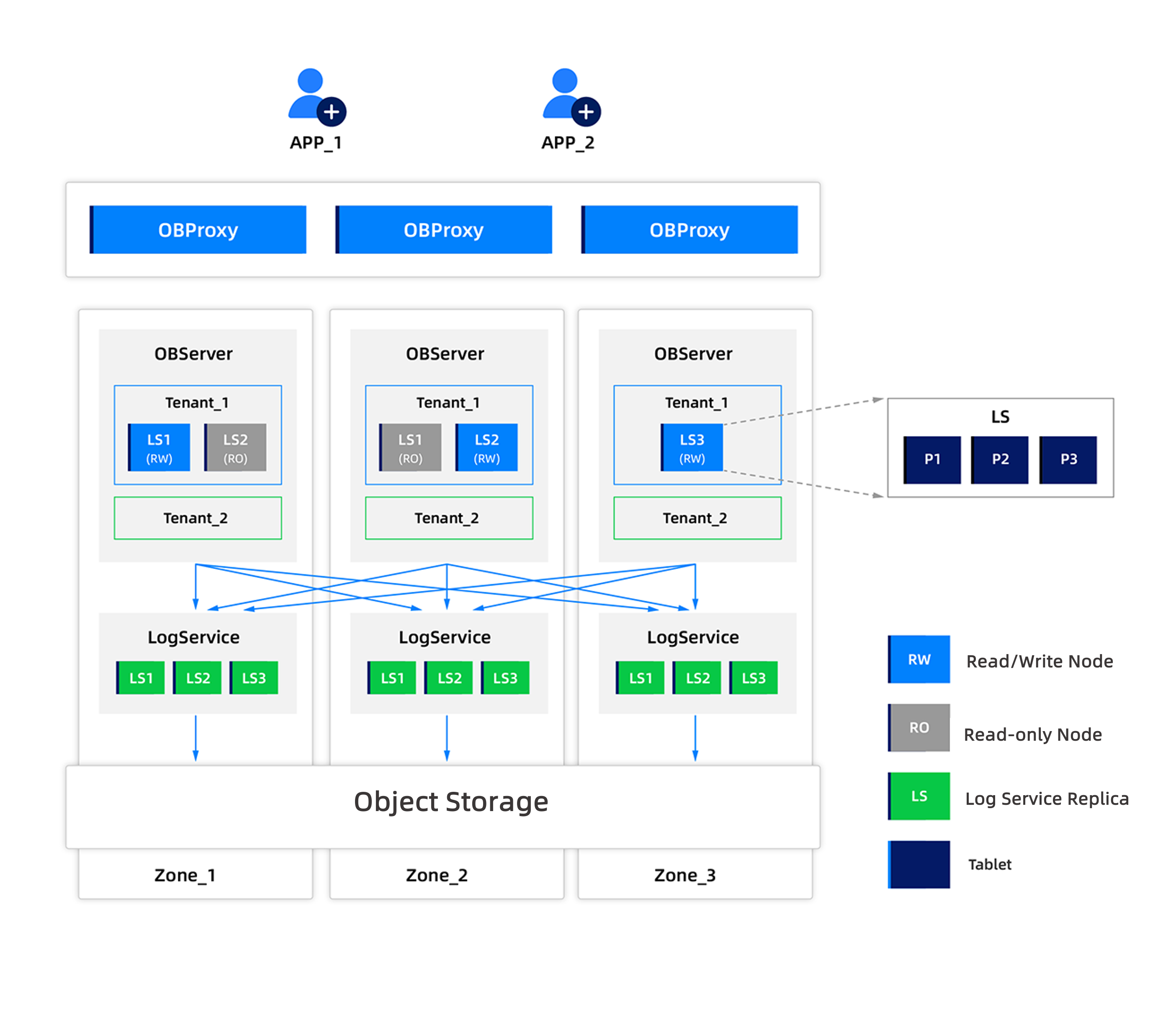
- TP OceanBase Database supports complex query and analysis of historical, backup, order, billing, message, access track, log, and IOT data for regulatory compliance. The bank can manage these data using OceanBase shared storage, significantly reducing storage costs. In this scenario, high availability is required, ensuring lossless disaster recovery, with RPO=0 and RTO<8s when an IDC or AZ fails. Low latency is required for data read operations. The storage primarily consists of cold storage, with hot data stored in local caches. It supports automatic cold-hot separation and manual configuration of hot data rules. Here are the requirements for the use case. You can add links to related features of the cloud. The following figure shows a deployment where the single region has multiple zones, and it is also configured with a separate Log Service.
- AP In the lakehouse scenario, massive data is stored and analyzed at low costs. For example, internet companies and social media platforms generate massive amounts of user behavioral data every day and generate and display rankings in real time. This scenario has low requirements for high availability. If an IDC or AZ fails, the RPO should be greater than 0, and the RTO can be achieved within several minutes. At the same time, it requires high throughput and is not sensitive to query latency. It supports local caching of hot data and manual configuration of hot data rules, including automatic separation of hot and cold data. A single-replica deployment method is as follows. This method uses a single Zone deployment, supporting horizontal scaling by adding or removing tenant units within the same Zone. For object storage, you can choose between intra-city redundancy or local redundancy. In this method, when an OBServer node fails, RPO is 0 and RTO is within a few minutes; if a Zone fails, RPO remains 0 but RTO can extend to several minutes.
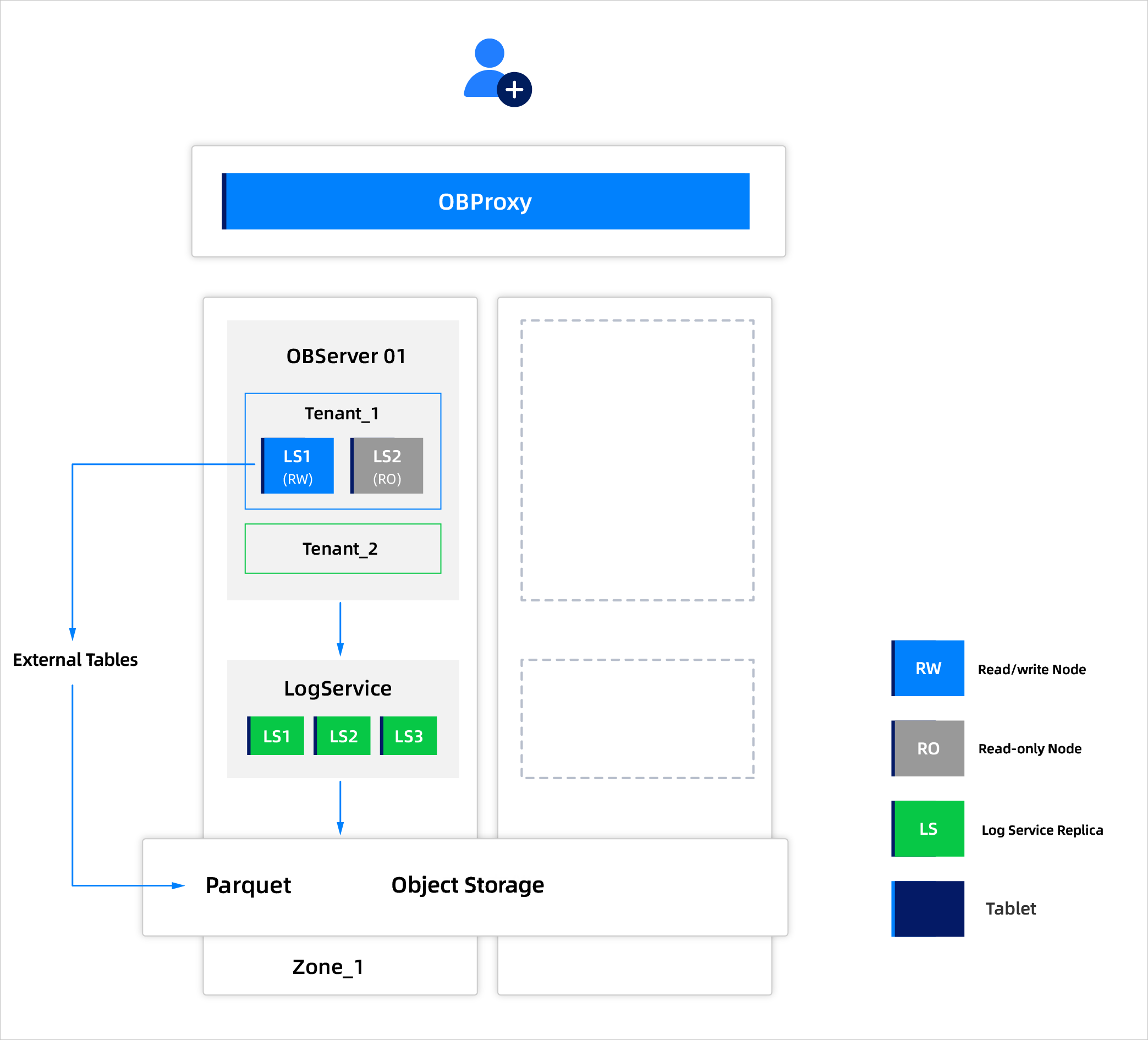
- KV It supports massive data storage and query scenarios. For example, user behavior logs can be stored and analyzed to collect click, browsing, and search behavior data. In this scenario, high availability is not a major concern. When an IDC or AZ failure occurs, the RPO can be greater than 0, and the RTO can be within a few minutes. The storage requirements involve multiple writes and few queries, and the query latency is not critical. Hot data requires local caching, and automatic hot/cold data separation is supported. Manual rules can also be configured for hot data in this scenario. This approach allows for a more cost-effective solution for storing wide tables and key-value (KV) type data. This section describes how to deploy OceanBase Database in a single-replica manner. In this deployment mode, you can horizontally scale the database up or down by adding or removing tenant units in a single zone. For object storage, you can select intra-city or local redundancy. If a single OBServer node fails in this deployment mode, the RPO is 0 and the RTO is in the minutes level. If a zone fails, the RPO is 0 and the RTO is in the minutes level.