

















What is OceanBase AP
In the database scenario, transaction processing (TP) focuses on high-concurrency and strong-consistency online transactions, while analytical processing (AP) focuses on real-time analysis and complex queries of massive data. Together, they support enterprises' data management and analysis needs. OceanBase has long been a leader in the TP field, serving many core businesses with its self-developed distributed architecture, financial-grade high availability, and extreme elasticity. With the growing demand for enterprise-level real-time analysis, OceanBase extended its capabilities from TP to AP in V4.3. It introduced native columnar and row-based storage, and integrated them. It also added vectorized execution engines. On the optimizer side, it enhanced the cost model and statistics for columnar storage, allowing the system to automatically choose between row and column access paths based on cost. These storage, execution, and optimization capabilities work together, enabling the same engine to handle both transactional workloads and real-time analysis efficiently, delivering integrated data management and real-time analysis value to enterprises.
 Learn about OceanBase Database AP's core capabilities and customer practices through this video.
Learn about OceanBase Database AP's core capabilities and customer practices through this video. Core features
Unified storage foundation supporting row-based, columnar, and hybrid storage: Users can flexibly specify row-based, columnar, or hybrid storage when creating tables to match different business needs. Columnar tables use a baseline columnar and incremental row-based approach. The baseline columnar storage optimizes complex query performance, while the incremental row-based storage supports high-concurrency data writes.
Strong transaction and high-concurrency guarantees for real-time analysis: Continues to use distributed ACID and multi-replica strong consistency architecture, ensuring strong data consistency in analytical scenarios. Supports smooth scaling and dynamic load balancing between nodes, allowing system performance to scale linearly with resource expansion. Supports multi-dimensional resource isolation: isolates resources between tenants and within tenants at the user, SQL, and foreground/background task levels. In a read-only columnar replica deployment, TP and AP traffic can be separated to different replicas, achieving physical strong isolation at the node level.
Vectorized execution engine for faster large-scale data analysis: Processes data in batches using efficient columnar data formats and optimizes operators and expressions for batch iteration. The storage layer aligns with this format, accelerating projection, predicate, and aggregation paths using SIMD and other methods. Supports adaptive batch size adjustment based on workload. Compared to traditional row-based processing (volcano model), analytical query performance can improve by an order of magnitude.
Enterprise-grade query optimizer for enhanced real-time analysis performance: Designed for HTAP and real-time analysis, it performs query rewriting and strategy selection in a larger plan space. Uses one-phase distributed plan generation, considering data distribution and parallelism when enumerating join orders and algorithms, avoiding the issue of single-machine optimal but distributed suboptimal. Automatically chooses between row-based and columnar access paths based on access characteristics and builds cost models and statistics for columnar scans to evaluate mechanisms like SkipIndex. For high-scan-cost queries, enables automatic parallelism (AUTO DOP) to shorten response times. Uses SQL plan management (SPM) to manage plan evolution when data volume, statistics, or versions change, and gray-scale validates to suppress plan rollback, ensuring stable operation.
Smart materialized views with multi-layer precomputation and frequent real-time refreshes: Users define precomputed results using declarative SQL, and OceanBase automatically manages refresh mechanisms and table dependencies, eliminating the need for complex ETL or data pipelines. Supports real-time materialized views and schedules refreshes based on target freshness (e.g., 30 seconds, 5 minutes). Uses automatic incremental view maintenance to perform incremental calculations only for changes since the last refresh, reducing refresh costs while maintaining freshness. When a materialized view is available, the query optimizer automatically rewrites queries from the base table to read from the materialized view, accelerating complex queries without requiring SQL changes.
Multi-modal data types for AI-integrated analysis: Native support for complex types like Array, Roaring Bitmap, Map, JSON, and Vector, along with capabilities like JSON multi-value indexing, vector indexing, and full-text indexing to narrow scan scopes and accelerate retrieval. Supports typical analysis scenarios like tag analysis and audience targeting, and meets AI-related needs like knowledge retrieval and semantic search through unified multi-type storage and hybrid retrieval.
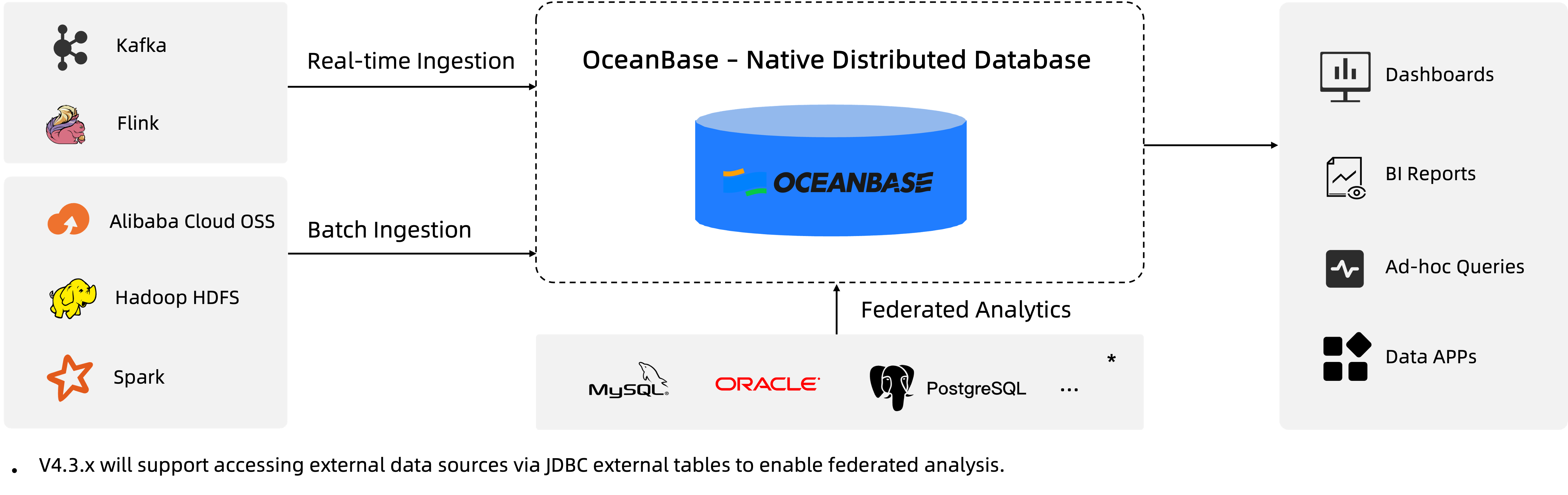
Seamless integration with open ecosystems to empower business innovation: OceanBase can access data from various external systems and collaborates with upstream and downstream tools. Supports real-time data ingestion and processing from streaming systems like Kafka and Flink. Supports migration and synchronization with existing databases or data warehouses using tools like OMS. Supports access to various file and object storage formats through external tables and integrates with catalogs like Hive Metastore and Iceberg for unified metadata access. Highly compatible with MySQL and Oracle at the SQL layer, facilitating BI, ETL, and other analysis tool integrations. Integrates with scheduling systems like DolphinScheduler and Airflow, and supports monitoring, visualization, and analysis tools like Prometheus, Grafana, Tableau, and QuickBI for data pipeline governance and business insights.
Application scenarios
Scenario 1: HTAP hybrid workload scenario
- Unified, minimalist architecture: A single engine and a single data set support both transactional and analytical workloads. You can choose between row-column hybrid storage and columnar storage replicas based on your business requirements.
- Low-cost, massive storage: Based on the LSM-Tree and advanced compression encoding technologies, the storage cost is reduced by 70%-90% compared to traditional solutions.
- High-concurrency computing: The peer-to-peer architecture of OceanBase Database natively supports parallel computing across multiple nodes. It can handle up to PB of data, providing a stable storage foundation for your business's full data set.
- Multi-scenario isolation: Through underlying resource isolation and user resource group technologies, tasks from different scenarios and users can be isolated in terms of resources.

Scenario 2: Real-time data analysis scenario
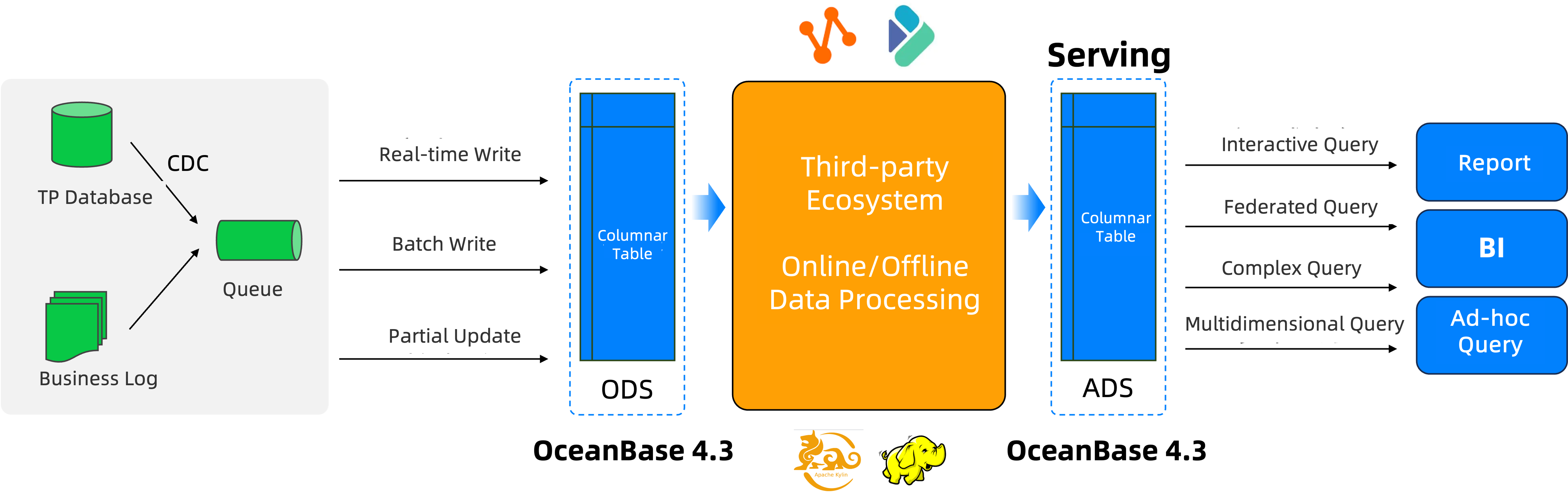
- Real-time data updates: Based on the LSM-Tree architecture, OceanBase Database supports efficient real-time writes. Incremental data is stored in rows, and baseline data is stored in columns. Regular or adaptive major compactions generate new columnar baseline data. Once data is written, it can be queried externally, ensuring real-time data availability.
- High accuracy and strong consistency: The Multi-Paxos protocol ensures data consistency across replicas. The MVCC model supports non-blocking reads and writes and guarantees transaction consistency for read data. It also supports strong reads from the primary replica and weak reads from other replicas. The WAL mechanism ensures data persistence and atomicity.
- High-performance computing: Columnar storage, query processing on compressed data, and data pushdown enable high-performance data queries. The optimizer's query rewriting and rule/ cost-based plan selection capabilities, combined with parallel execution and vectorized execution engines, optimize execution for high computational performance. Materialized views further support query and analysis on massive data.
- High availability: Inheriting the high availability capabilities of TP systems, OceanBase Database offers RPO=0 and RTO<8s. It supports flexible deployment from a single IDC to three regions with five IDCs, and automatic disaster recovery. Cloud Database OceanBase also supports a single-replica architecture with shared storage and independent log services, reducing costs while ensuring high availability.
- Smooth scaling: You can smoothly scale horizontally or vertically without interrupting services. During horizontal scaling, the built-in data dynamic balancing mechanism ensures even distribution of data and service loads across nodes.
- Multi-model integration: OceanBase Database fully supports various data models, including B-tree indexes, JSON multi-value indexes, full-text indexes, and vector indexes.
- Separation of storage and computing: Multiple computing nodes can access the same storage data. Combined with local persistent caching and object storage, this enables a high-performance, cost-effective separation of storage and computing.


Scenario 3: PL/SQL batch processing scenario
- Extreme performance improvement, breaking processing bottlenecks. OceanBase Database's columnar storage engine is designed for analytical scenarios. Data is stored in columns, resulting in higher compression ratios and reduced I/O. Combined with the vectorized execution engine, the CPU can perform calculations on a batch of data (instead of a single row) in memory, significantly improving CPU cache hit rates and computational efficiency. For typical batch processing tasks, performance can be improved by 10 times or more, meeting or even shortening business batch processing windows, enabling near-real-time analysis.
- Seamless, risk-free migration. OceanBase Database is highly compatible with Oracle, not only supporting common SQL syntax and data types but also PL/SQL stored procedures. This means you can migrate business logic-rich stored procedures from Oracle to OceanBase with minimal changes. Application code remains unchanged, minimizing migration risks, costs, and time, making system modernization possible.
- Unified architecture for cost efficiency. Traditional architectures separate OLTP databases from data warehouses or big data platforms, requiring maintenance of two systems and complex ETL/CDC synchronization, leading to high costs. OceanBase Database's unified architecture handles online transactions and batch processing analysis with a single system. Its built-in resource isolation ensures that analytical tasks on columnar storage do not conflict with transactional tasks on row storage. This simplifies the technology stack, reduces O&M complexity, avoids data redundancy, and eliminates cross-system synchronization overheads, significantly lowering the total cost of ownership (TCO).
Technical architecture
- For more information about the technical architecture of OceanBase Database, see OceanBase system architecture.
- For more information about the technical principles of OceanBase Database, see OceanBase system principles.