

















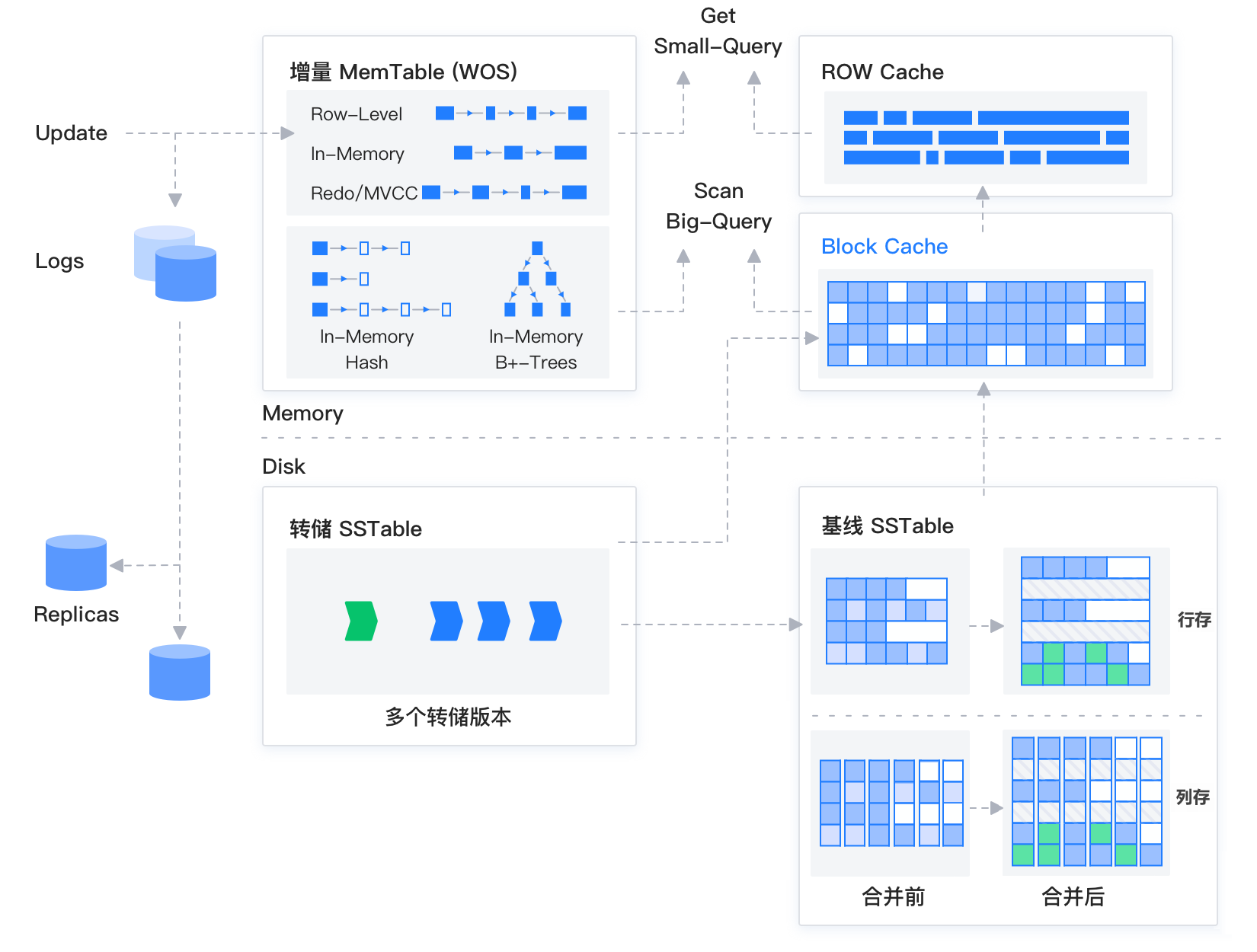
The storage engine of OceanBase Database is based on the LSM-Tree architecture. It divides data into static baseline data (stored in SSTables) and dynamic incremental data (stored in MemTables). The SSTable is read-only and stored on disk; it is generated once and remains unchanged thereafter. The MemTable supports both read and write operations and is stored in memory. When a database performs DML operations such as INSERT, UPDATE, or DELETE, the data is first written to the MemTable. When the MemTable reaches a certain size, it is flushed to disk as an SSTable. During a query, the system queries both the SSTable and the MemTable, merges the query results, and returns the merged result to the SQL layer. Additionally, block cache and row cache are implemented in memory to avoid random reads of baseline data.
When the incremental data in memory reaches a certain scale, a major compaction between the incremental data and the baseline data is triggered to persist the incremental data to disk. Furthermore, the system automatically performs daily major compactions during idle periods each evening.
OceanBase Database is essentially a storage engine that combines a baseline with incremental data. While retaining the advantages of the LSM-Tree architecture, it also incorporates some features from traditional relational database storage engines.
Traditional databases divide data into many pages. OceanBase Database draws on this concept, dividing data files into macroblocks with a basic granularity of 2 MB, and further splitting each macroblock into multiple variable-length microblocks. During a major compaction, data is reused at the granularity of macroblocks. Macroblocks that remain unchanged are not re-opened for reading, which minimizes write amplification during the compaction process and significantly reduces the cost of major compaction compared to traditional LSM-Tree-based databases.
Because OceanBase Database adopts a baseline-plus-incremental design, with some data in the baseline and some in the incremental data, theoretically, each query requires reading from both the baseline and the incremental data. To address this, OceanBase Database has implemented numerous optimizations, particularly for single-row queries. In addition to caching data blocks, OceanBase Database also caches rows, which greatly accelerates single-row query performance. For "null queries" where no row exists, a Bloom filter is built and cached. Most OLTP business operations involve small queries. Through optimization for small queries, OceanBase Database avoids the overhead of parsing an entire data block in traditional databases, achieving performance close to that of an in-memory database. Moreover, since the baseline is read-only data and uses contiguous storage internally, OceanBase Database can employ relatively aggressive compression algorithms, achieving high compression ratios without affecting query performance, thereby significantly reducing costs.
By integrating and drawing on the strengths of classic databases, OceanBase Database provides a more versatile relational database storage engine based on the LSM-Tree architecture, with the following characteristics:
Low cost: Leveraging the LSM-Tree characteristic that data written once is not updated, and by combining proprietary hybrid row-column encoding with general-purpose compression algorithms, OceanBase Database achieves a data storage compression ratio that is 10x or more higher than that of traditional databases.
Easy to use: Unlike other LSM-Tree databases, OceanBase Database ensures the normal operation or rollback of large and long transactions by supporting the persistence of active transactions to disk, and helps users find a better balance between performance and space through multi-level compaction and minor compaction mechanisms.
High performance: For common point queries, OceanBase Database provides multi-level cache acceleration to ensure extremely low response latency. For range scans, the storage engine leverages data encoding features to support computation pushdown of query filter conditions and provides native vectorized support.
High reliability: In addition to end-to-end data verification, OceanBase Database leverages its native distributed architecture to ensure user data correctness during global major compaction through multi-replica comparison and verification of primary tables against index tables. It also provides background threads to regularly scan for and avoid silent errors.
Features of the storage engine
From a functional module perspective, the storage engine of OceanBase Database can be roughly divided into the following parts.
Data storage
Data organization
Similar to other LSM-Tree databases, OceanBase Database also divides data into two layers: incremental data in memory (MemTable) and static data stored on disk (SSTable). The SSTable is read-only and stored on disk; it is generated once and remains unchanged thereafter. The MemTable supports both read and write operations and is stored in memory. When a database performs DML operations such as INSERT, UPDATE, or DELETE, the data is first written to the MemTable. When the MemTable reaches a certain size, it is flushed to disk as an SSTable.
Furthermore, within OceanBase Database, an SSTable is further subdivided into three types: Mini SSTable, Minor SSTable, and Major SSTable. The MemTable is compacted into a Mini SSTable on disk via a minor compaction. When multiple Mini SSTables reach a certain threshold, a minor compaction is triggered to merge them into a Mini SSTable or a Minor SSTable. When the daily major compaction unique to OceanBase Database begins, the original baseline SSTable (Major SSTable) of each partition is integrated with all Mini SSTables and Minor SSTables to form a new Major SSTable.
Storage structure
In OceanBase Database, the basic storage unit for each partition is an SSTable, and the fundamental storage granularity is the macroblock. When the database starts, the entire data file is divided into macroblocks of fixed size 2 MB. An SSTable is essentially a collection of multiple macroblocks.
Each macroblock is further split into multiple microblocks. The concept of a microblock is similar to that of a page or block in traditional databases. However, leveraging the characteristics of the LSM-Tree, microblocks in OceanBase Database are compressed and variable in length. The pre-compression size of a microblock can be determined by specifying the
block_sizeparameter during table creation.Microblocks can be stored in either encoded format or flat format based on the user-specified storage format. In encoded format microblocks, internal data is stored in a hybrid row-column mode. For flat-format microblocks, all data rows are stored in a flat layout.
Compression encoding
OceanBase Database encodes and compresses the data within microblocks according to the format specified for the user table. When the user table enables encoding, the data within each microblock is encoded column-wise based on the column dimension. Encoding rules include dictionary, run-length, constant, and difference encoding. After encoding each column, inter-column equivalence and substring rules are applied. Encoding not only helps significantly compress the data but also extracts intra-column feature information that further accelerates subsequent query speeds.
After encoding and compression, OceanBase Database also supports further lossless compression of microblock data using user-specified general compression algorithms to further improve data compression ratios.
Minor compaction and major compaction
Minor compaction
Minor compaction consists of two processes: Mini Compaction and Minor Compaction. When the size of the MemTable in memory exceeds a certain threshold, data in the MemTable is flushed to disk into Mini SSTables to free up memory. This process is called Mini Compaction. As user data is written, the number of Mini SSTables increases. When the number of Mini SSTables exceeds a certain threshold, the background automatically triggers Minor Compaction.
Major compaction
Major compaction, also known as daily compaction in OceanBase Database, has a concept that differs slightly from other LSM-tree-based databases. As the name suggests, this concept was initially designed to perform a comprehensive compaction operation for the entire cluster around 02:00 every morning. Major compaction is generally scheduled and initiated by the RS of each tenant based on write status or user settings. Each major compaction for a tenant selects a global snapshot point. All partitions within the tenant then perform a major compaction using the data from this snapshot point. Thus, all tenant data generated after each major compaction is based on this unified snapshot point to produce the corresponding SSTable. This mechanism not only helps users regularly integrate incremental data and improve read performance but also provides a natural data verification point. Through this globally consistent point, OceanBase Database can perform multi-dimensional physical data verification internally across multiple replicas and between primary tables and index tables.
Query read and write
Insertion
In OceanBase Database, all data tables can be considered index clustered tables. Even for heap tables without a primary key, a hidden primary key is maintained internally. Therefore, when a user inserts data, before writing the new user data to the MemTable, it first checks whether data with the same primary key already exists in the current data table. To accelerate this duplicate primary key query performance, for each SSTable, background threads asynchronously schedule the construction of Bloomfilters based on the frequency of deduplication for different macroblocks.
Update
As an LSM-tree-based database, each update in OceanBase Database also involves inserting a new row of data. Unlike a Clog, the updated data written to the MemTable contains only the new values of the updated columns and the corresponding primary key column. That is, an updated row does not necessarily contain data for all columns of the table. Through continuous background compaction, these incremental updates are continuously merged to accelerate user queries.
Deletion
Similar to an update, a deletion operation does not act directly on the original data either. Instead, it writes a row of data using the deleted row's primary key and marks the deletion with a header flag. A large number of deletions is not friendly to LSM-tree-based databases because it causes the database to still need to iterate through all rows marked with deletion within a data range and perform merging before confirming the deletion status even after the range is completely deleted. For this scenario, OceanBase Database provides an inherent range deletion marking logic to avoid this situation. It also supports allowing users to explicitly specify table modes, enabling special minor compactions and major compactions to reclaim these deleted rows in advance and accelerate queries.
Query
Due to the incremental update strategy, when querying each row of data, all MemTables and SSTables must be traversed from the latest version to the oldest, and the data corresponding to the primary key in each Table is merged together and returned. Data access uses caches as needed to accelerate performance. For large query scenarios, the SQL layer pushes filtering conditions down to the storage layer, leveraging the characteristics of stored data for fast filtering at the underlying level, and supports batch computation and result return for vectorized scenarios.
Multi-level caching
To improve performance, OceanBase Database supports a multi-level caching system, providing Block Cache for data microblocks in queries, Row Cache for each SSTable, Fuse Row Cache for query fusion results, and Bloomfilter cache for null check insertion. All caches under the same tenant share memory. When the write speed to the MemTable is too fast, memory can be flexibly reclaimed from various cache objects for write use.
Data verification
As a financial-grade relational database, OceanBase Database always prioritizes data quality and security. Data verification protection is added to every part of the data link involving persistence. Additionally, leveraging the inherent advantage of multi-replica storage, inter-replica data verification is added to further verify overall data consistency.
Logical verification
In common deployment modes, each user table in OceanBase Database has multiple replicas. During daily major compaction for a tenant, all replicas generate consistent baseline data based on a globally unified snapshot version. Utilizing this feature, the data checksums of all replicas are compared upon completion of the major compaction to ensure complete consistency. Furthermore, based on the indexes of the user table, the checksums of the index columns are also compared to ensure the final data returned to the user does not contain errors due to inherent program issues.
Physical verification
For data storage, OceanBase Database records corresponding checksums starting from the smallest I/O granularity of microblocks. These checksums are recorded for each microblock, macroblock, SSTable, and partition. Data verification is performed during each read. To prevent underlying storage hardware issues, data is re-verified immediately after writing macroblocks during minor compaction and major compaction. Finally, regular data inspection threads run in the background on each server to scan and verify the overall data, helping to detect silent data corruption on disks in advance.