

















OceanBase Database uses the table_scan operator of the pull mode to perform iteration. Each row is iterated and then delivered to the SQL layer after the following steps are performed:
Each SSTable locates the macroblock and corresponding microblocks to be scanned by the query range, opens and scans each microblock, and delivers the requested rows as a whole.
The iterators in the MemTable, minor SSTable, and major SSTable iterate the rows, respectively.
The number of rows to be fused is determined by the number of iterators whose current rowkeys are the same based on the loser tree structure.
The result row after the fusion is generated based on the result of the requirement projection.
The filter callback function of SQL is called to check the result row. If the conditions are met, the result row is returned to the upper layer.
Query pushdown
If you use a storage engine based on the log-structured merge-tree (LSM tree) architecture, you may encounter the following problems during the query process:
Excessive and frequent iterations and primary key comparisons are required. In scenarios such as online analytical processing (OLAP) services, most tables are seldom updated. Data is stored in the baseline major SSTable. The MemTable and minor SSTables store only a small amount of incremental or updated data. In ideal conditions, most paths can be quickly and directly scanned from the major SSTable. Iterator fusion (Major SSTable, MemTable, and Minor SSTable) is required only when primary keys have possible intersections. However, in practice, the storage engine needs to compare each row with the data generated by minor compactions and with the iterators in the MemTable to check whether the primary keys are consistent. This results in low efficiency and eliminates the possibility of scaling for vectorization.
Filter operators cannot perform calculations in a timely manner. To ensure the accuracy of final results, all rows must be fused to make sure that the latest data is used. A check on filter operators is performed at last during the iteration of each row.
Useless projection is excessively performed. The rows delivered by microblock scanning must make sure that all required columns are projected. After multiple iterations and fusion operations, the rows that meet the filter conditions can be directly returned. However, if the rows do not meet the conditions, other projected columns except those required for filtering are unusable.
OceanBase Database pushes the filter operators down to the storage layer to resolve these problems, as shown in the following figure.
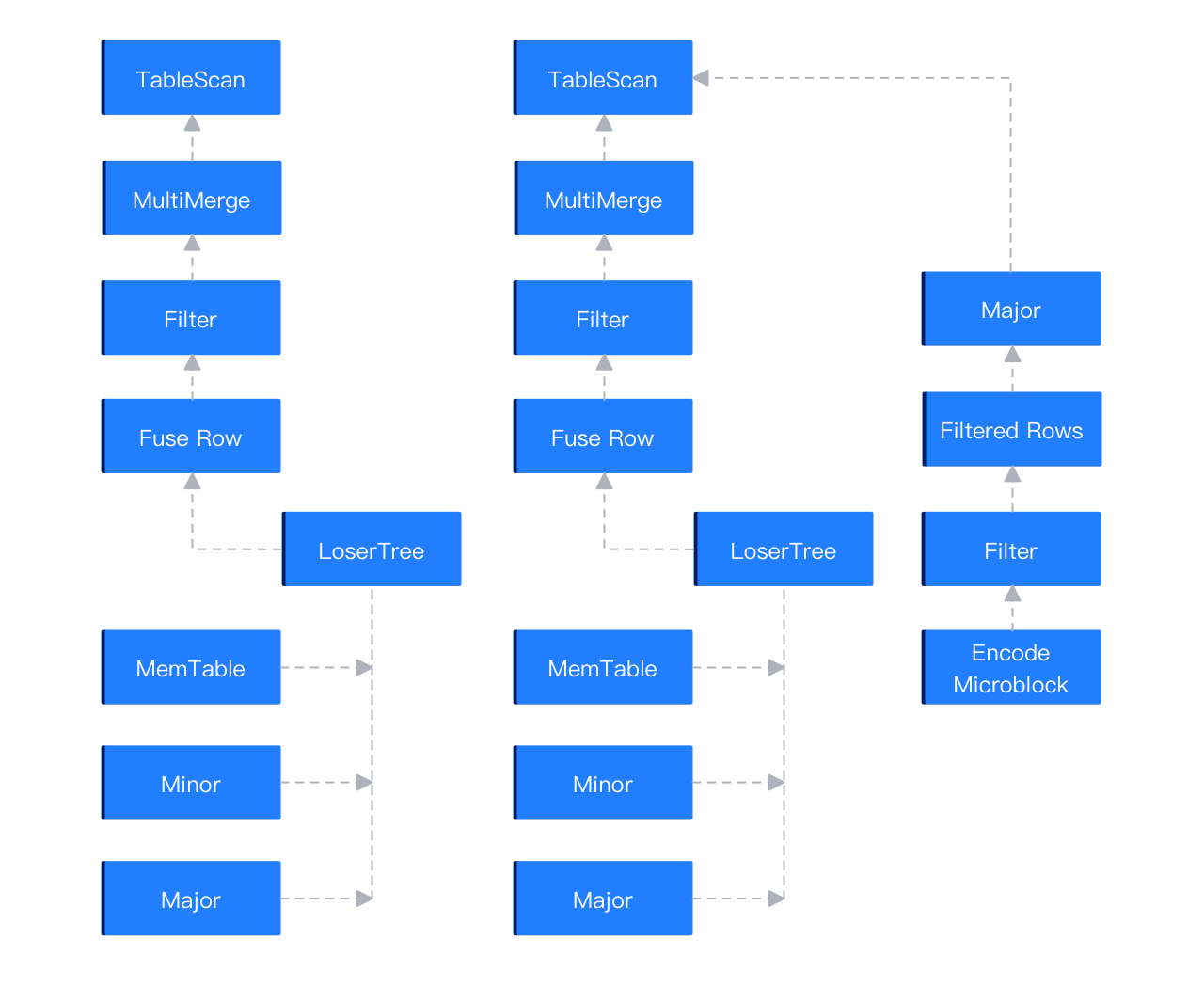
Operator pushdown: OceanBase Database can quickly identify the situation in which no data intersections are involved. To be specific, OceanBase Database can detect the data range without intersections between the data in the major SSTable and the incremental data. For data within this range, OceanBase Database can access the major SSTable to obtain the latest and final status. Therefore, the filter operators can be directly pushed down for this data range.
Operator filtering: OceanBase Database parses and splits each pushed-down filter expression into an expression tree that is comprehensible to the storage layer. The expression tree contains information about corresponding columns and related filter expressions. The filtering operations can be divided into black-box filtering and white-box filtering based on the complexity of filter conditions.
SQL layer-based filtering (black box): The storage layer cannot process filter conditions with a calculation expression such as a * 2 > 3. These filter conditions need to be processed by calling callback functions of the SQL layer. After the operators are pushed to the decoder layer of microblocks, the operators cannot be further pushed down. OceanBase Database needs to project the corresponding columns based on the filter node information and then call callback functions of the SQL layer to generate the results.
Storage-based filtering (white box): For simple and regular filter conditions, such as a > 1 and b = 'abc', the storage layer can comprehend the semantic and process the filter node. The SQL layer then parses the corresponding operators and constant expressions. In this way, the storage layer can push down this filter node to the decoding rule of each column. This allows you to reduce the projection overhead and make full use of encoding information for acceleration.