
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Cross-Cloud DR Networking: Sync Methods & Paths

Cross-cloud database deployments — whether primary-standby DR or active-active replication — share one problem that doesn't appear on architecture diagrams: the networking layer between two clouds that don't share a control plane, a private backbone, or even a consistent API for network interconnection. Bridging them requires specialized network solutions — dedicated lines, public networks, or cloud enterprise networks — each introducing its own complexity around bandwidth, latency, and data transmission security.
Earlier posts in this series on active-active replication and primary-standby DR touched briefly on networking, but stopped short of exploring it in detail. This post breaks down the sync methods, network paths, and latency factors that affect cross-cloud replication, then looks at how OceanBase Cloud handles the common wiring that underpins its DR topology. We'll use primary-standby as the running example since it is the most common starting point.
Primary-Standby: Two Sync Methods and Three Network Paths
Before choosing a network topology, understand that cross-cloud database replication involves two fundamentally different sync methods — and the network path question only applies to one of them.
Direct Network Connection: Real-Time Log Streaming
The direct network connection establishes a live channel between primary and standby. The Log Transport Service (LTS) continuously reads redo logs from the primary and transmits them in real-time to the standby, where the Log Replay Service (LRS) applies them into the standby's MemStore as they arrive. No intermediary storage — sync latency sits at the millisecond level.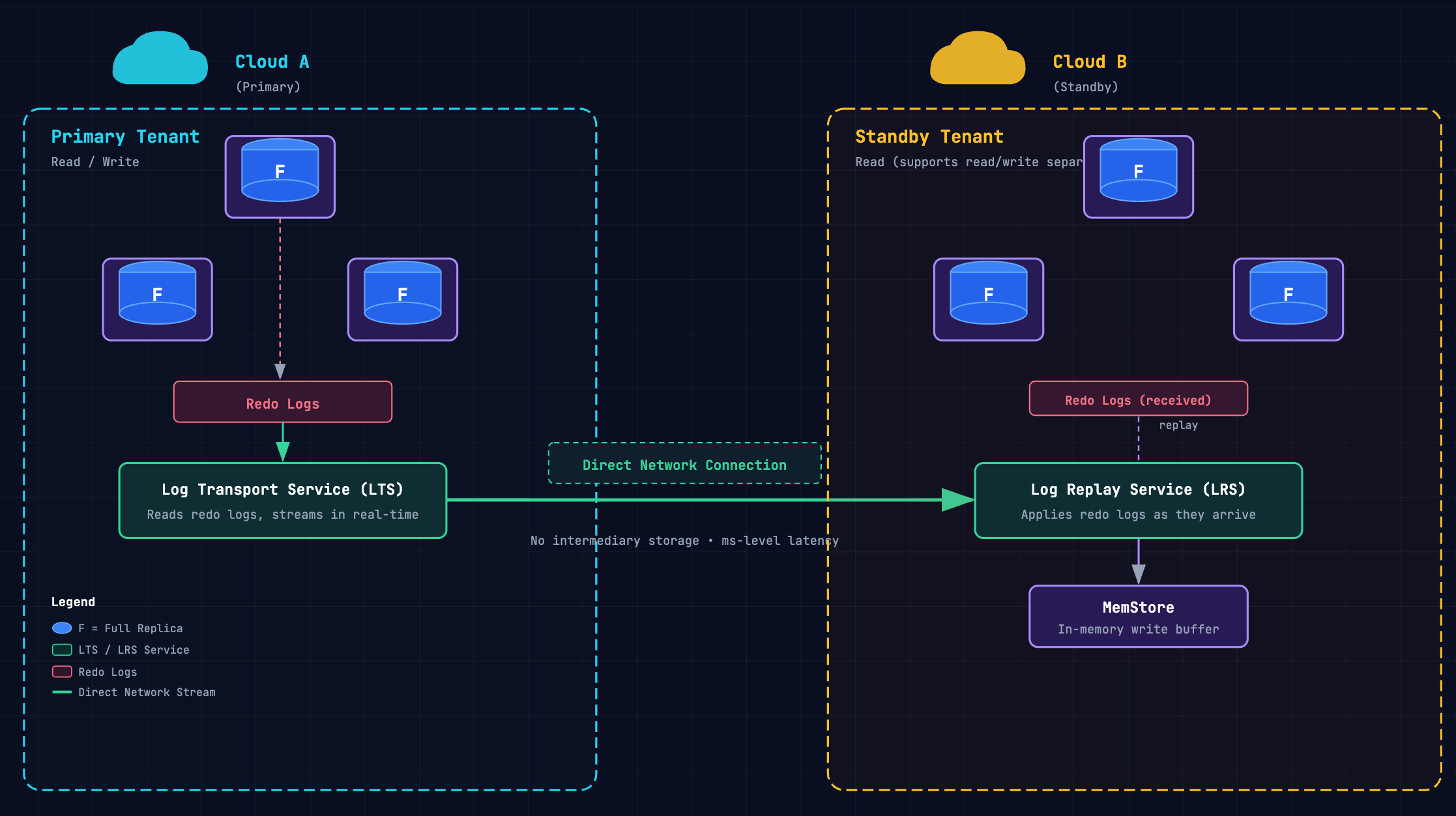
This method supports read/write separation (the standby can serve read traffic), and it's the only option suitable for workloads with strict RPO requirements.
Within this method, you choose a network path:
- VPC peering — A direct peering relationship between the primary and standby VPCs, typically through each cloud provider's cross-cloud interconnection service. Lowest latency, highest reliability, most complex to provision.
- Dedicated line — A leased private circuit (such as Alibaba Cloud Express Connect or AWS Direct Connect) between the two cloud environments. Predictable latency and bandwidth, but requires physical provisioning and ongoing line costs.
- Encrypted public internet — The database connection runs over the public internet with encryption. Simplest to set up, but latency is variable and subject to internet jitter. Suitable for development or staging environments, or as a fallback path.
Log Archiving: Object Storage Relay
The log archiving method takes a completely different approach. The primary writes redo logs to object storage in its own region — OSS on Alibaba Cloud, S3 on AWS — and the standby reads those archived logs and replays them locally. No direct network connection between the two databases.
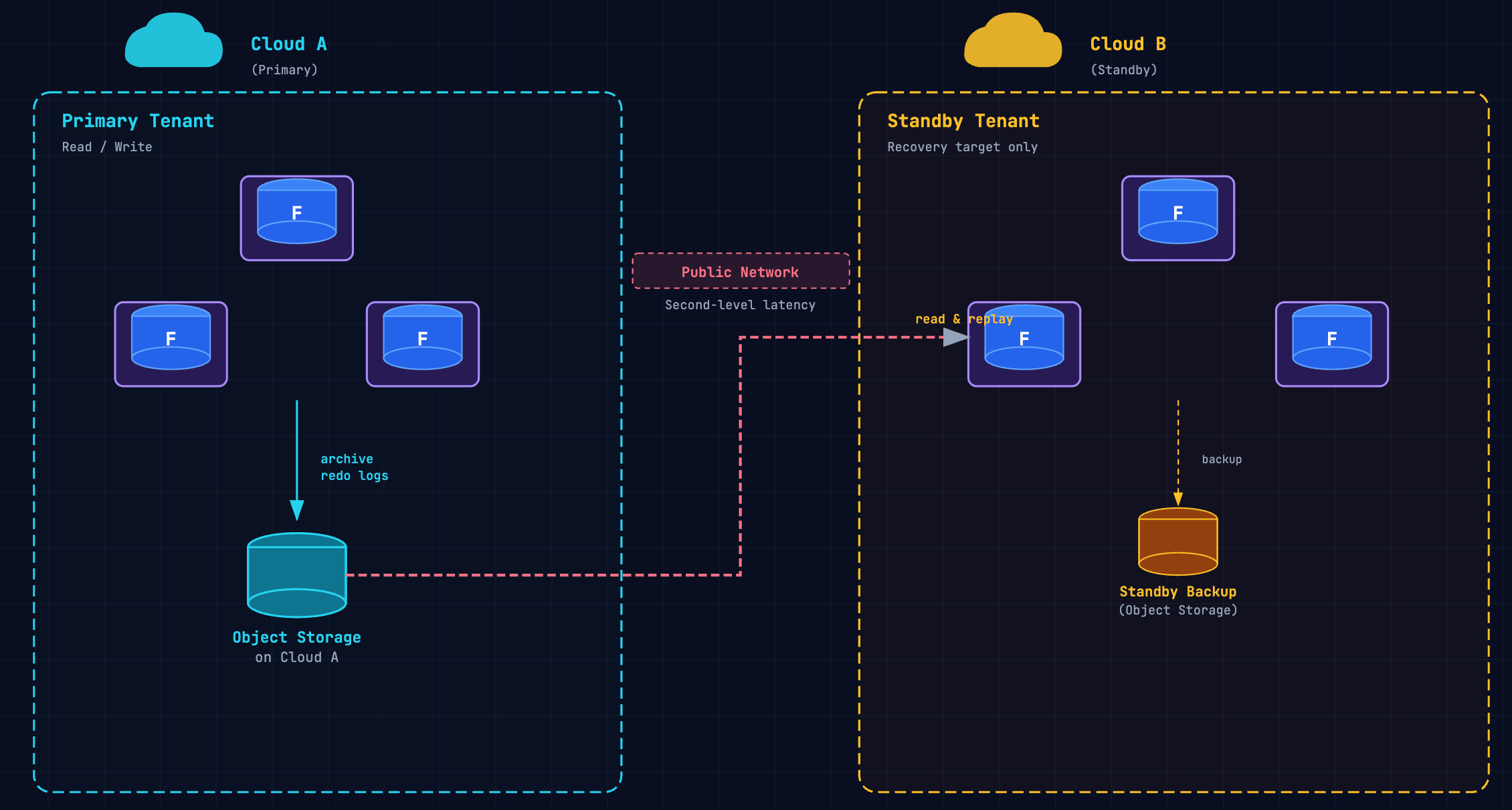
Sync latency is at the second level because data takes an extra hop through object storage. Read/write separation is not supported — the standby is purely a recovery target. But you need zero cross-cloud network infrastructure, and you can set this up on demand without provisioning anything.
Choosing Between Them
| Direct network connection | Log archiving | |
| Sync latency | Milliseconds | Seconds |
| Sync path | Primary → VPC/dedicated line/internet → Standby | Primary → Object storage → Standby |
| Read/write split | Supported (standby serves reads) | Not supported |
| Network infrastructure | VPC peering, dedicated line, or internet | None (object storage API only) |
| Cost | Higher (private channel + line fees) | Lower (storage egress only) |
| RPO suitability | Strict RPO workloads | Tolerant RPO workloads |
| Setup complexity | Weeks to months (provisioning required) | On-demand, no network changes |
Most production deployments needing cross-cloud DR for compliance or business continuity use the direct network connection. Log archiving fits cost-sensitive environments where second-level lag is acceptable — development/staging DR, reporting replicas, or regulatory data residency where the standby exists for jurisdictional reasons rather than fast failover.
What Actually Affects Sync Latency
Once you've chosen the direct network connection method, your sync latency depends on several factors — some you can control, some you can't.
- Network round-trip between clouds. This is the dominant factor and the one you have least control over. Same-city inter-datacenter latency typically sits at 0.5–2 ms. Cross-cloud latency between providers in the same region will be higher, and it varies by cloud pair and region. There are no universal benchmarks here — you need to measure your specific cloud pair with sustained traffic, not just ping tests.
- Component placement. Cross-cloud network traffic and latency directly affect transmission performance — but not all data needs to cross the cloud boundary. OceanBase provides RPC compression via the
log_transport_compress_allconfiguration parameter, which applies lz4 or zstd compression to log transport with minimal CPU overhead. This is recommended for all workload types in bandwidth-constrained scenarios. For dedicated arbitration services, the minimum bandwidth requirement is 20 Mbps, scaling at approximately 20 Mbps per 32 additional single-unit tenants. - Public internet jitter. If you chose the encrypted public internet path, latency will be unpredictable. Internet routing between cloud providers can shift, causing latency spikes that directly translate to sync lag spikes. This is why the public internet path is unsuitable for production workloads with strict RPO requirements — worst-case latency is unbounded.
💡 Measure before you commit
Deploy test instances on both clouds in your target regions. Run sustained write workloads for at least 72 hours and measure p50, p95, and p99 sync latency across your candidate network paths. Weekend and weeknight traffic patterns differ from business hours — capture both.
How OceanBase Cloud Handles the Wiring
That's the data plane — what moves between clouds, how, and what affects performance. But there's still a layer that doesn't appear on architecture diagrams: the managed infrastructure that provisions and maintains those cross-cloud pipes. OceanBase Cloud handles this through three infrastructure primitives that underpin every cross-cloud topology, whether primary-standby or active-active.
- Cloud gateway: cross-cloud network connectivity. You specify the source and target cloud providers and regions; the system provisions network connection instances that bridge each cloud vendor's VPC. OceanBase Cloud handles construction, monitoring, and maintenance behind the scenes. This is the connectivity layer — it replaces the weeks-to-months of manual VPC peering or dedicated-line provisioning described earlier in this post.
- Global endpoint: topology-aware traffic routing. The global endpoint is a single connection address that routes traffic through those network connection instances. What it routes to depends on your topology:
- Primary-standby: routes to the current primary. On failover, the endpoint reroutes to the new primary.
- Active-active: routes to the nearest active instance.
Note:
In both cases, this is not DNS-based failover: routing updates happen at the endpoint layer rather than waiting for DNS TTL propagation. Applications never change their connection strings.
- Localized transmission components: source-side filtering, target-side writing. For bidirectional sync in cross-cloud active-active mode, network traffic and latency directly affect data transmission performance. OceanBase Cloud addresses this by deploying log parsing components on the source cloud and data writing components on the target cloud. Filtering and parsing happen locally at the source, so only relevant log data crosses the cloud boundary. Writes happen with local latency at the target. This minimizes cross-cloud data volume and removes one round-trip from the critical path.
Encryption and Cost
Two operational concerns that cut across everything above.
- Encryption is always on. Cross-cloud replication data is encrypted with AES-128-GCM — the same standard used by AWS and Google Cloud for internal data transport. Session keys between cloud gateways are transmitted via secure private tunnels and rotated periodically. Beyond replication, OceanBase supports SSL/TLS (TLSv1 through TLSv1.3) for client connections and SSL-encrypted RPC for node-to-node communication. Encryption overhead is negligible relative to cross-cloud network latency — there's no "disable encryption for performance" trade-off.
- Network costs scale with write throughput. This is often the largest variable in a cross-cloud DR budget, and it scales in ways that compute and storage costs don't. Direct network connections carry the highest cost — dedicated lines require provisioning contracts and monthly fees; VPC peering involves data transfer charges that scale with replication volume. Log archiving is dramatically cheaper: the only cross-cloud cost is object storage egress. For organizations where second-level sync latency is acceptable, this cost difference can be the deciding factor. Budget networking separately from compute and storage.
Conclusion
Cross-cloud networking is the layer that makes or breaks a multi-cloud database deployment, and it's the layer most teams underestimate until they're debugging replication lag at 2 a.m. The sync method, network path, and infrastructure automation decisions covered here should be made before you provision your first cross-cloud instance — not after.
Download The Multi-Cloud DR Playbook to see how network paths, sync modes, global endpoints, and DR topologies fit into a complete architecture.
Further Reading



Keep Reading
View all posts
From Complex to Simple: How We Built seekdb for the AI Era
AI era doesn't need another heavy, complex enterprise database. It needs agility. It needs flexibility. We went back to the drawing board to understand what an AI application actually needs from a database. Our answer is OceanBase seekdb



Beyond Fine-tuning: Solving DABstep's Hard Mode with Versioned Assets
On the DABstep Global Leaderboard, OceanBase DataPilot agent has secured the top spot, maintaining a significant lead over the runner-up for a month. The secret to our SOTA results was a fundamental shift in engineering paradigm: moving from "Prompt Engineering" to "Asset Engineering."


Permanent Server Offline in OceanBase: How the Cluster Heals After a Node Is Gone
How OceanBase distinguishes a transient outage from a permanent loss, and why operators should intervene rather than wait for the automatic re-replication timer.
