

















In addition to the high availability of ODP services, ODP also helps OceanBase Database achieve high availability. ODP is an important part of the high availability system of OceanBase Database. When an issue occurs in OceanBase Database, the database system must be able to recover services in a timely manner. On the other hand, ODP is need to perceive OBServer failures and service changes.
ODP adopts fault detection, the blacklist mechanism, and SQL retries to implement the preceding features. Fault detection identifies faulty nodes. The blacklist mechanism influences ODP routing. SQL retries ensure that SQL statements are successfully executed as much as possible.
Fault detection and blacklist mechanism
Fault detection
ODP faults can be divided into the following two categories:
Server and process failures, including server hardware issues and process issues such as server breakdowns, network failures, and process core dumps.
Business logic issues, including service unavailability caused by logic issues of OceanBase Database, for example, leader service interruption caused by Paxos election failures.
Failures caused by business logic are closely related to the database implementation, and therefore are difficult to define and solve. For example, service unavailability caused dead loop of business logic cannot be solved by using ODP.
Therefore, in addition to OBServer and process failures, ODP deals with some business logic issues according to some known symptoms, for example, specific error codes returned by an OBServer (such as those indicating insufficient machine memory), and no response from an OBServer for a long time.
In a distributed system, fault detection results can be success, failure, or timeout. Among them, timeout is the trickiest one. For example, if an SQL statement has been executed for 100s and no result is returned, it is difficult to determine whether the OBServer executing the SQL statement is normal. The OBServer may execute SQL statements slowly, or the OBServer may be faulty.
On the other hand, detection tasks are generally periodically scheduled. If the status of an OBServer changes during the detection interval, ODP cannot detect the change in real time and may have to make routing choices based on expired information. This may cause slow SQL execution or SQL execution failures.
Fault detection is based on node status definitions. For example, two states are defined: healthy and faulty. However, OBServer status is more complex, because more refined status definition helps achieve more high availability features and offer better user experience. ODP defines the following eight OBServer states:
ACTIVE: The OBServer node is normal and can provide services.INACTIVE: The OBServer node is abnormal and cannot provide services.UPGRADE: The OBServer node is in the progress of database version upgrade.REPLAY: The OBServer node is in the progress of database log playback.DELETING: The OBServer node is being deleted. In this case, operations such as data migration may be in progress.DELETED: The node has been deleted and no longer belongs to the cluster.DETECT_ALIVE: ODP detects the OBServer node and considers the OBServer node normal.DETECT_DEAD: ODP fails to detect the OBServer node and considers the OBServer node abnormal.
Through OBServers have many states, these states essentially reflect the corresponding faults or operations. For example, INACTIVE indicates a core dump, DELETING or DELETED indicates that a node is being deleted or has been deleted, REPLAY indicates that a node is added, UPGRADE indicates a version upgrade, and DETECT_DEAD indicates that the process is hanging.
ODP can get the first six states by accessing an OBServer view. ODP periodically obtains server status information of the cluster from the DBA_OB_SERVERS and DBA_OB_ZONES views at an interval of 20s. ODP determines the OBServer status based on the status, start_service_time, and stop_time fields in the query result. ODP obtains the DETECT_ALIVE and DETECT_DEAD states by using the detection mechanism.
The query result is as follows:
MySQL [oceanbase]> select * from DBA_OB_SERVERS\G
*************************** 1. row ***************************
SVR_IP: 10.10.10.2
SVR_PORT: 2882
ID: 1
ZONE: zone1
SQL_PORT: 2881
WITH_ROOTSERVER: YES
STATUS: ACTIVE
START_SERVICE_TIME: 2022-10-31 11:48:38.677315
STOP_TIME: NULL
BLOCK_MIGRATE_IN_TIME: NULL
CREATE_TIME: 2022-10-31 11:48:24.684250
MODIFY_TIME: 2022-10-31 11:48:39.682642
BUILD_VERSION: 4.0.0.0_100000252022102910-df01cef074936b9c9f177697500fad1dc304056f(Oct 29 2022 10:27:50)
MySQL [oceanbase]> select * from DBA_OB_ZONES\G
*************************** 1. row ***************************
ZONE: zone1
CREATE_TIME: 2022-10-31 11:48:29.040552
MODIFY_TIME: 2022-10-31 11:48:29.041609
STATUS: ACTIVE
IDC:
REGION: default_region
TYPE: ReadWrite
Blacklist mechanism
After the status of an OBServer changes, ODP triggers the logic related to high availability based on the status change result. High availability is closely related to the blacklist mechanism.
Specifically, after ODP detects the status of an OBServer, ODP modifies the blacklist and then adds the node to or removes the node from the blacklist. Based on the detection mechanisms, ODP implements three blacklists: status blacklist, detection blacklist, and alive-but-unavailable blacklist.
Status blacklist
The status blacklist depends on the status changes of OBServers. Due to historical reasons, the DETECT_ALIVE and DETECT_DEAD states are not related to the status blacklist. The changes of other states can be obtained from views of OBServers.
When ODP obtains the latest status of an OBServer by using a scheduled task, ODP performs the corresponding operation based on the status of the OBServer.
ACTIVE: ODP removes the OBServer from the status blacklist.INACTIVE/REPLAY: ODP adds the OBServer to the status blacklist.DELETED/DELETING: ODP updates the OBServer list in the memory and no longer forwards SQL requests to this OBServer.UPGRADE: ODP neither adds the OBServer to the status blacklist nor forwards SQL requests to the OBServer. This is equivalent to adding the OBServer to the status blacklist.
Detection blacklist
For the status blacklist, ODP obtains information from the RootServer of OceanBase Database. Such information sometimes may be unable to reflect the conditions between ODP and OBServers. As shown in the following figure, ODP learns from the RootServer that OBServer1 is in the ACTIVE state, but the network between ODP and OBServer1 is disconnected.
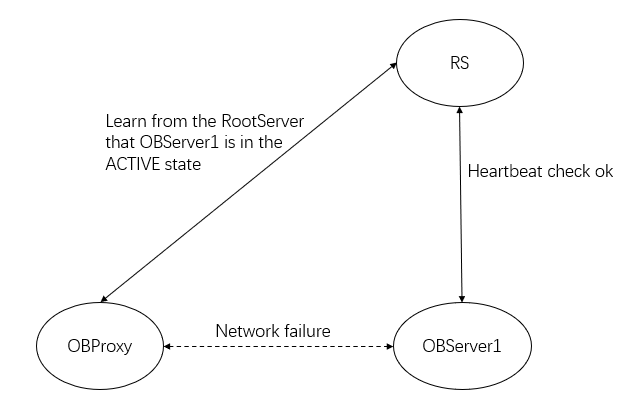
Therefore, ODP implements the detection blacklist based on the status blacklist. ODP sends a detection SQL statement to an OBServer to determine its status. ODP sends a detection SQL statement select 'detect server alive' from dual to the sys tenant of the OBServer and set the timeout period to 5s. If no result is returned within the timeout period, ODP sends a detection statement again. If the detection fails for three consecutive times, ODP sets the status of this OBServer to DETECT_DEAD. If a result is returned, ODP clears the number of detection failures and sets the status of this OBServer to DETECT_ALIVE. After ODP detects a status change, ODP performs the corresponding operation.
DETECT_ALIVE: ODP removes the OBServer from the detection blacklist.DETECT_DEAD: ODP adds the OBServer to the detection blacklist and closes all connections to this OBServer.
Note
If ODP adds an OBServer to the detection blacklist but does not close the connections to the OBServer, the connections are always occupied and no new SQL requests can be sent. The performance data shows that the transactions per second (TPS) of this OBServer is 0 during this period. After the connections to the OBServer are closed, ODP will route subsequent requests based on the blacklist and will not forward requests to this OBServer. Then, the TPS can resume.
Alive-but-unavailable blacklist
ODP can properly handle server and process faults based on the status blacklist and detection blacklist. However, ODP wants to further perceive the cause of each failed SQL statement execution so as to handle complex situations. The alive-but-unavailable blacklist is implemented for this purpose.
In the alive-but-unavailable mechanism, ODP defines the status of an OBServer based on the execution results of business SQL statements and adds the OBServer to or removes it from the blacklist based on the status. ODP is more cautious about adding an OBServer to or removing an OBServer from the alive-but-unavailable blacklist than with the status blacklist and the detection blacklist. This aims to avoid misjudgments that are made based on a single SQL execution result. The operation performed by ODP on an OBServer vary with the actual situation:
ODP will record a failure event in any of the following cases:
ODP sends a detection SQL statement to the OBServer and does not receive any response after the timeout period specified by the
ob_query_timeoutparameter expires.The OBServer returns the OB_SERVER_IS_INIT, OB_SERVER_IS_STOPPING, OB_PACKET_CHECKSUM_ERROR, or OB_ALLOCATE_MEMORY_FAILED error code.
ODP fails to connect to the OBServer, parse packets, or transmit data.
If the OBServer has five alive-but-unavailable records within 120s, ODP will add it to the alive-but-unavailable blacklist.
ODP will attempt to resend a detection SQL statement to the OBServer 20s later after it adds the OBServer to the alive-but-unavailable blacklist.
If the detection SQL statement is successfully executed, ODP will remove the OBServer from the blacklist.
Note
You can run the
show proxycongestion [all] [clustername]command to view the blacklists in a cluster. Thedead_congestedandalive_congestedfields respectively indicate the status blacklist and the alive-but-unavailable blacklist.After an OBServer is added to the alive-but-unavailable blacklist, no requests will be forwarded to this OBServer within the period specified by
congestion_retry_interval. A detection statement will be sent to this OBServer again after the period specified byretry_interval. The OBServer cannot be removed from the blacklist within the period specified bymin_keep_congestion_interval.
These three blacklists can help resolve issues from different dimensions. Exceptions may fail to be handled with the absence of any of these blacklists. These blacklists have no precedence over one another. An OBServer in any blacklist cannot receive requests. In other words, an OBServer can receive requests only if it is not in any blacklist.
Proxies such as HAProxy only implement a detection mechanism to check the health status of backend servers. This type of detection can resolve only simple issues. ODP provides various features based on the features of OceanBase Database, such as perception of version upgrades, log replay, and SQL execution errors. This far exceeds regular proxies.
SQL retries
The SQL retry feature can be implemented based on blacklists. SQL retries aim to ensure the execution of SQL statements instead of simply throwing an error to the client.
The prerequisite for retrying an SQL statement is that unexpected behavior must not happen. For example, if the OBServer does not respond a long time after you execute the insert into t1 values (c1 + 1, 1) statement, you cannot send this statement to another OBServer. Otherwise, c1 may change to c1 + 2. An incorrect retry is more harmful.
ODP may perform a retry before or after forwarding to the OBServer.
Retries before forwarding
This section describes retries before forwarding based on the ODP architecture diagram. In the following figure, the part marked red indicates the position where a retry before forwarding occurs.
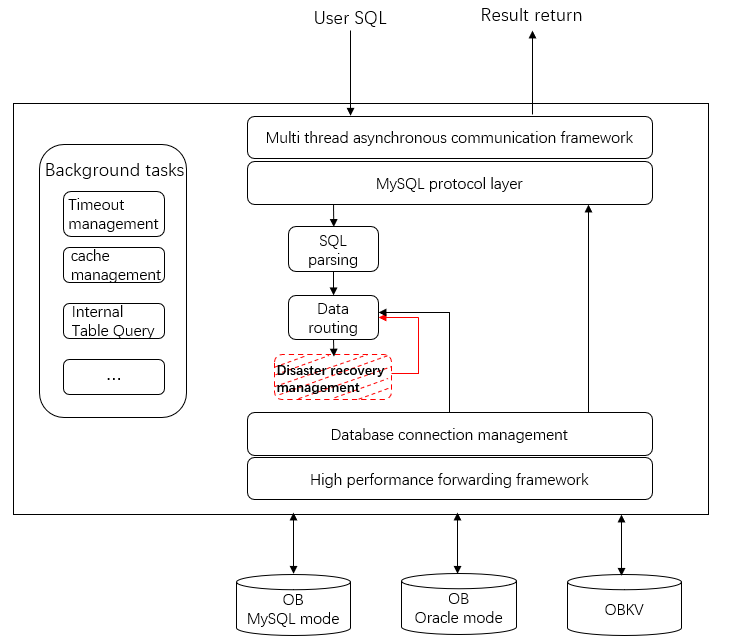
In the following example, a regular SQL statement select * from t is used to describe the logic of a retry before forwarding.
Assume that t is a partitioned table and the leader is located on OBServer1. After RootService detects a core dump in the observer process of OBServer1, RootService sets the status of OBServer1 to INACTIVE.
ODP selects OBServer1 in the data routing phase, and then performs a disaster recovery check and finds that OBServer1 is in the status blocklist. In this case, a retry is required. ODP uses intra-tenant routing to select another OBServer node in the server list of the tenant and then performs a disaster recovery check. If the selected OBServer node passes the check, ODP forwards the request to the node.
Earlier detection of an issue facilitate faster rectification of the issue. A retry before forwarding occurs only within the ODP. Therefore, rapidly rectified issues are imperceptible to business systems.
Retries after forwarding
A retry before forwarding is efficient but depends on the accuracy of blacklists. In a distributed system, an ODP cannot perceive the server status in real time. Therefore, the ODP may not know that an OBServer is faulty before the ODP performs forwarding. In this case, a retry can be performed based on the forwarding result.
Two forwarding results are commonly seen:
The TCP connection fails because the OBServer is faulty.
In this case, ODP can select another OBServer if no special restrictions, such as transaction routing, are involved.
The OBServer encounters an execution failure and returns an error code.
For more information about error codes, see the open-source code
ObMysqlTransact::handle_oceanbase_server_resp_errorof ODP. For example, if the OBServer returns the error codeREQUEST_SERVER_INIT_ERROR, the OBServer initialization fails. In this case, reforwarding can be performed and the logic is similar to the logic of a retry before forwarding.
With retries before forwarding and retries after forwarding, ODP can handle most OBServer issues. The entire process is transparent to users and users may not perceive the faults. A retry before forwarding is efficient but depends on the blacklist mechanism. A retry after forwarding is a supplement to the retry before forwarding and aims to shield backend exceptions as much as possible.
In short, fault detection, blacklists, and SQL retries are three important features to ensure high availability for ODP. They are also mutually related. Both the retry after forwarding and the alive-but-unavailable blacklist depend on the feedback from OBServers. Retries before forwarding depend on the blacklist mechanism.
With these three features, ODP can handle most OBServer exceptions such as network failures, observer process exceptions, and server breakdowns. Moreover, ODP can identify logic exceptions in OceanBase Database such as version upgrade and log replay, to improve the performance of OBServers.
Correlation with the high availability of OceanBase Database
Unlike ODP, OceanBase Database uses the Paxos algorithm to ensure high availability. When the majority of nodes in OceanBase Database are normal, services can still be provided properly and exceptions of a minority of nodes can be tolerated. However, the high availability feature of OceanBase Database may cause the leader role to be switched from Node A to Node B. Therefore, ODP must find the normal service nodes more efficiently and accurately. In this way, the high availability feature of ODP and that of OceanBase Database work together to provide stable services.