

















This topic describes the rule-based path selection mechanism of OceanBase Database.
Currently, the path selection mechanism of OceanBase Database consists of two types of rules: forward rules and Skyline pruning rules. Forward rules directly determine which indexes are used for a query. These rules are highly specific.
Skyline pruning rules compare two indexes. If one index dominates (is better than) another index in certain defined dimensions, the dominated index is pruned. The remaining indexes are then compared based on cost to select the optimal plan.
Currently, the optimizer of OceanBase Database prioritizes forward rules for index selection. If no matching indexes are found, Skyline pruning rules prune some suboptimal indexes, and the cost model selects the path with the lowest cost among the remaining indexes.
The following example shows how the plan display of OceanBase Database includes information about the path selection rules.
Create a table named
t1.obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT, UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d) );View the execution plan for the query condition
b = 1.obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;The result is as follows:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | =========================================== | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | ------------------------------------------- | | |0 |TABLE GET|t1(k1)|1 |10 | | | =========================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([t1.a(0x7f35a049b280)], [t1.b(0x7f35a049b000)], [t1.c(0x7f35a049b410)], [t1.d(0x7f35a049b5a0)], [t1.e(0x7f35a049b730)]), filter(nil), rowset=16 | | access([t1.a(0x7f35a049b280)], [t1.b(0x7f35a049b000)], [t1.c(0x7f35a049b410)], [t1.d(0x7f35a049b5a0)], [t1.e(0x7f35a049b730)]), partitions(p0) | | is_index_back=true, is_global_index=false, | | range_key([t1.b(0x7f35a049b000)], [t1.shadow_pk_0(0x7f35a04c25e0)]), range[1,NULL ; 1,NULL], | | range_cond([t1.b(0x7f35a049b000) = 1(0x7f35a049ad60)(0x7f35a049aeb0)]) | | Used Hint: | | ------------------------------------- | | /*+ | | | | */ | | Qb name trace: | | ------------------------------------- | | stmt_id:0, stmt_type:T_EXPLAIN | | stmt_id:1, SEL$1 | | Outline Data: | | ------------------------------------- | | /*+ | | BEGIN_OUTLINE_DATA | | INDEX(@"SEL$1" "test_db"."t1"@"SEL$1" "k1") | | OPTIMIZER_FEATURES_ENABLE('4.4.2.0') | | END_OUTLINE_DATA | | */ | | Optimization Info: | | ------------------------------------- | | t1: | | table_rows:1 | | physical_range_rows:1 | | logical_range_rows:1 | | index_back_rows:1 | | output_rows:1 | | table_dop:1 | | dop_method:Table DOP | | avaiable_index_name:[k1, k2, k3, t1] | | pruned_index_name:[k2, k3, t1] | | stats info:[version=1970-01-01 08:00:00.000000, is_locked=0, is_expired=0] | | dynamic sampling level:0 | | estimation method:[DEFAULT] | | Plan Type: | | LOCAL | | Parameters: | | :0 => 1 | | Note: | | Degree of Parallelisim is 1 because of table property | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ 50 rows in setView the execution plan for the query conditions
c < 5andORDER BY c.obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;The result is as follows:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | ================================================== | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | -------------------------------------------------- | | |0 |TABLE RANGE SCAN|t1(k3)|1 |5 | | | ================================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([t1.a(0x7f35a239d650)], [t1.b(0x7f35a239d7e0)], [t1.c(0x7f35a239d3d0)], [t1.d(0x7f35a239d970)], [t1.e(0x7f35a239db00)]), filter(nil), rowset=16 | | access([t1.a(0x7f35a239d650)], [t1.c(0x7f35a239d3d0)], [t1.b(0x7f35a239d7e0)], [t1.d(0x7f35a239d970)], [t1.e(0x7f35a239db00)]), partitions(p0) | | is_index_back=true, is_global_index=false, | | range_key([t1.c(0x7f35a239d3d0)], [t1.d(0x7f35a239d970)], [t1.a(0x7f35a239d650)]), range(NULL,MAX,MAX ; 5,MIN,MIN), | | range_cond([t1.c(0x7f35a239d3d0) < 5(0x7f35a239d130)(0x7f35a239d280)]) | | Used Hint: | | ------------------------------------- | | /*+ | | | | */ | | Qb name trace: | | ------------------------------------- | | stmt_id:0, stmt_type:T_EXPLAIN | | stmt_id:1, SEL$1 | | Outline Data: | | ------------------------------------- | | /*+ | | BEGIN_OUTLINE_DATA | | INDEX(@"SEL$1" "test_db"."t1"@"SEL$1" "k3") | | OPTIMIZER_FEATURES_ENABLE('4.4.2.0') | | END_OUTLINE_DATA | | */ | | Optimization Info: | | ------------------------------------- | | t1: | | table_rows:1 | | physical_range_rows:1 | | logical_range_rows:1 | | index_back_rows:1 | | output_rows:1 | | table_dop:1 | | dop_method:Table DOP | | avaiable_index_name:[k1, k2, k3, t1] | | pruned_index_name:[k1, k2] | | unstable_index_name:[t1] | | stats info:[version=1970-01-01 08:00:00.000000, is_locked=0, is_expired=0] | | dynamic sampling level:0 | | estimation method:[DEFAULT, STORAGE] | | Plan Type: | | LOCAL | | Parameters: | | :0 => 5 | | Note: | | Degree of Parallelisim is 1 because of table property | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ 51 rows in set
Prerequisites
Currently, the prerequisites for OceanBase Database are only applicable to simple single-table scans. This is because the prerequisite rules are a strong matching system. Once a rule is matched, the corresponding index is directly selected. Therefore, it is necessary to limit the usage scenarios to avoid selecting the wrong plan.
Currently, OceanBase Database divides the prerequisite rules into three types based on the priority, according to the following two pieces of information: whether the query conditions can cover all index keys, and whether the index needs to be accessed.
If the query conditions match the unique index and do not require a table access (the primary key is treated as a unique index), the corresponding index is selected. If multiple such indexes exist, the one with the fewest index columns is selected.
If the query conditions match the normal index and do not require a table access, the corresponding index is selected. If multiple such indexes exist, the one with the fewest index columns is selected.
If the query conditions match the unique index and require a table access, and the number of rows to be accessed is less than a certain threshold, the corresponding index is selected. If multiple such indexes exist, the one with the fewest rows to be accessed is selected.
Note that index full matching means that there are equality conditions on all index keys (corresponding to get or multi-get).
In the following example, query Q1 matches the index uk1 (unique index full matching, no table access); query Q2 matches the index uk2 (unique index full matching, table access required, and the number of rows to be accessed is less than the threshold).
Create a table named
test.obclient> CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT, UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );Query examples.
Q1:
obclient> SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);Q2:
obclient> SELECT * FROM test WHERE (c = 1 OR c =2) AND (d = 1 OR d = 2);
Skyline pruning rules
The Skyline operator is a new database operator proposed in 2001 by the academic community (it is not a standard SQL operator). Since then, the academic community has conducted extensive research on the Skyline operator, including its syntax, semantics, and execution.
The Skyline operator refers to the marginal points in the search space that represent the optimal solutions. For example, if you want to find a hotel with the lowest price and the shortest distance, you can imagine a two-dimensional space where the x-axis represents price and the y-axis represents distance. Each point in this space represents a hotel. As shown in the following figure, the optimal solution must be on the marginal line of the sky. If point A is not on the Skyline, there must be a point B on the Skyline that is better than A in both dimensions. In this scenario, point B represents a hotel that is closer and cheaper than point A. This is called point B dominating point A. Therefore, the Skyline algorithm can be used when it is impossible to measure the importance of multiple dimensions or when multiple dimensions cannot be quantitatively combined (if they can be combined, you can use the "SQL function + ORDER BY" method to solve the problem).
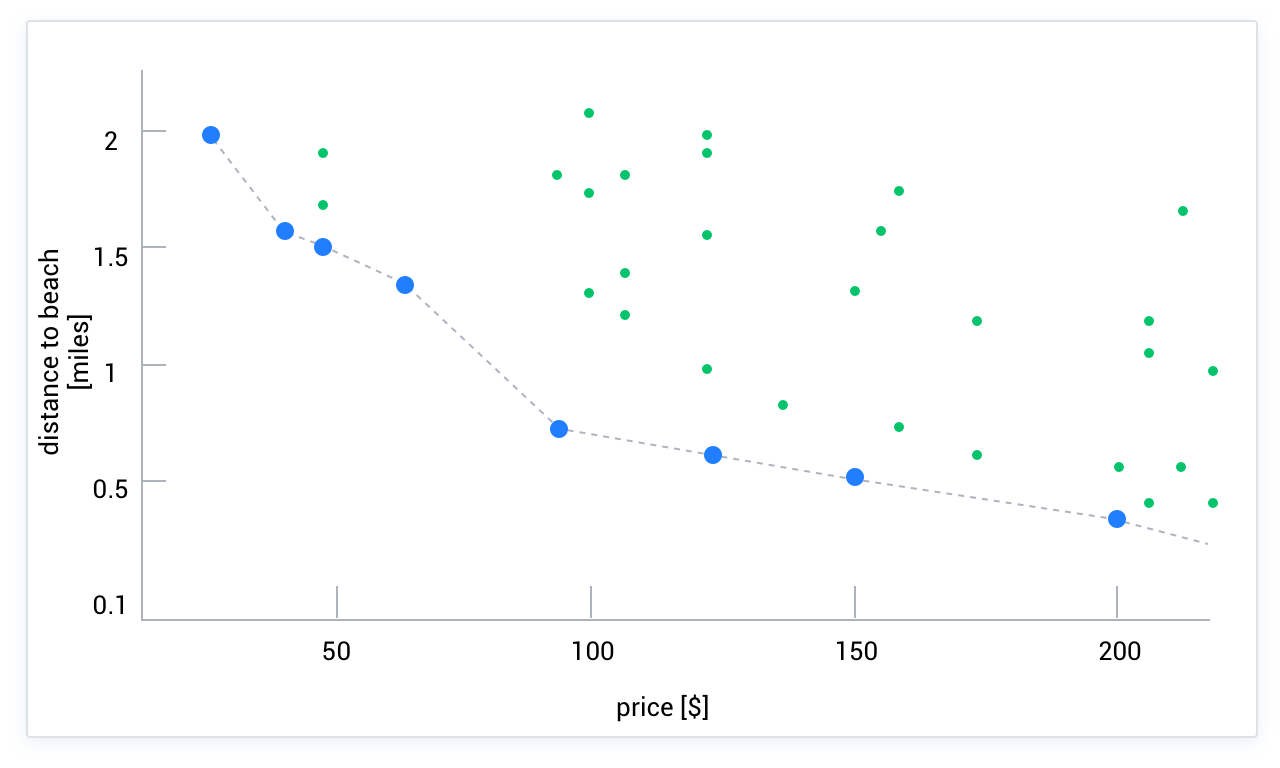
The principle of the Skyline operator is to find the set of objects in the given object set O that are not dominated by any other objects. If object A is not dominated by object B in any dimension and dominates B in at least one dimension, then A is said to dominate B. Therefore, the selection of dimensions and the definition of the dominance relationship in each dimension are crucial in the Skyline operator. Suppose there are N paths of indexes <idx_1, idx_2, idx_3...idx_n> available for the optimizer to choose from. For a query Q, if index idx_x dominates index idx_y in the defined dimensions, index idx_y can be pruned in advance and will not participate in the final cost calculation.
Dimension definition
Skyline pruning rules define the following three dimensions for each index (including the primary key as an index):
Whether to access the base table
Whether there is an Interesting Order
Whether the index prefix can extract the Query Range
Let's analyze this with an example:
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
KEY idx_a_b(a, b),
KEY idx_b_c(b, c),
KEY idx_c_a(c, a)
);
Accessing the base table: Whether the query needs to access the base table.
/* If the query uses the idx_a_b index, it needs to access the base table because the index idx_a_b does not contain the c column*/ obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;Interesting Order: Whether there is a suitable order to use.
/* The index idx_b_c can eliminate the ORDER BY statement*/ obclient>SELECT pk, b FROM skyline ORDER BY b;Whether the index prefix can extract the Query Range.
/* Using the idx_c_a index can quickly locate the required row range without a full table scan*/ obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
Based on these three dimensions, Skyline defines the Dominate relationship between indexes. If index A is not worse than index B in all three dimensions and at least one dimension is better, we can infer that the plan generated based on index B will not be better than the plan generated based on index A. Therefore, we can directly prune index B. The judgment criteria are as follows:
If index
idx_Adoes not need to access the base table, while indexidx_Bdoes, then indexidx_Adominates indexidx_Bin this dimension.If the Interesting Order extracted from index
idx_Ais the vectorVa<a1, a2, a3 ...an>, and the Interesting Order extracted from indexidx_Bis the vectorVb<b1, b2, b3...bm>, andn > m, withai = bi (i=1..m), then indexidx_Adominates indexidx_Bin this dimension.If the set of columns used to extract the Query Range from index
idx_AisSa<a1, a2, a3 ...an>, and the set of columns used to extract the Query Range from indexidx_BisSb <b1, b2, b3...bm>, andSais a superset ofSb, then indexidx_Adominates indexidx_Bin this dimension.
Accessing the base table
Accessing the base table refers to whether the required columns for the query are present in the index. Special considerations are needed for certain scenarios, such as when neither the base table nor the index table has an Interesting Order and cannot extract the Query Range. In such cases, accessing the base table may not always be the optimal solution.
obclient> CREATE TABLE t1(pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
v1 VARCHAR(1000),
v2 VARCHAR(1000),
v3 VARCHAR(1000),
v4 VARCHAR(1000),
INDEX idx_a_b(a, b)
);
obclient>SELECT a, b,c FROM t1 WHERE b = 100;
Index |
Index Back |
Interesting Order |
Query Range |
|---|---|---|---|
| primary | no | no | no |
| idx_a_b | yes | no | no |
Since the base table is wide and the index table is narrow, from a dimensional analysis, the base table dominates the index idx_a_b. However, the cost of scanning the index and accessing the base table may not necessarily be higher than the cost of a full table scan on the base table. In other words, the index table may only need to read one macroblock, while the base table may need to read ten macroblocks. In such cases, the rules need to be relaxed, and the specific filtering conditions should be considered.
Interesting Order
The optimizer can utilize the underlying order through Interesting Order, eliminating the need to sort the rows scanned from the underlying table. It can also eliminate ORDER BY, perform MERGE GROUP BY, and improve the pipeline (without materialization).
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
v1 INT,
v2 INT,
v3 INT,
v4 INT,
v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4)
);
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
obclient> (SELECT DISTINCT v1, v3 FROM skyline JOIN tmp
WHERE skyline.v1 = tmp.c1
ORDER BY v1, v3)
UNION (SELECT c1, c2 FROM tmp);

From the execution plan, we can see that the ORDER BY statement has been eliminated, and MERGE DISTINCT is used. The UNION statement does not perform a SORT. This indicates that the order from the underlying TABLE SCAN can be utilized by the upper-level operators. In other words, retaining the row order from the index idx_v1_v3_v5 allows subsequent operators to perform more optimal operations while preserving the order. The optimizer can generate a more optimal execution plan by recognizing these orders.
Therefore, Skyline pruning must thoroughly consider the maximum usable orders of each index when evaluating Interesting Order. For example, in the previous example, the largest order is actually (v1, v3) rather than just v1. The order (v1, v3) from the MERGE JOIN can be passed to the MERGE DISTINCT operator and then to the final UNION DISTINCT operator.
Query Range
Extracting the Query Range allows the underlying layer to directly locate specific macroblocks based on the extracted range, reducing I/O operations at the storage layer.
For example, SELECT * FROM t1 WHERE pk < 100 AND pk > 0 can directly locate specific macroblocks based on the primary index information, accelerating the query. The more precise the Query Range, the fewer rows the database needs to scan.
obclient> CREATE TABLE t1 (pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
KEY idx_b_c(b, c),
KEY idx_a_b(a, b)
);
obclient> SELECT b FROM t1 WHERE a = 100 AND b > 2000;
The index prefix that can extract the Query Range for index idx_b_c is (b), and the index prefix that can extract the Query Range for index idx_a_b is (a, b). Therefore, in this dimension, index idx_a_b dominates index idx_b_c.
Example
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
v1 INT,
v2 INT,
v3 INT,
v4 INT,
v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4)
);
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
obclient> SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;
Index |
Index Back |
Interesting order |
Query range |
|---|---|---|---|
| primary | Not need | No | No |
| idx_v1_v3_v5 | Not need | (v1) | (v1, v3) |
| idx_v3_v4 | Need | No | (v3) |
The index idx_v1_v3_v5 is not worse than the primary index or the index idx_v3_v4 in any of the three dimensions. Therefore, according to the Skyline pruning rules, the primary index and the index idx_v3_v4 will be pruned. The reasonable definition of dimensions determines whether Skyline pruning is reasonable. Incorrect dimensions can cause the index to be pruned prematurely, potentially preventing the generation of the optimal plan.