
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Cross-Cloud Disaster Recovery on OceanBase Cloud: How Primary-Standby Replication Works


In a typical high availability setup, Multi-AZ handles rack failures. Multi-region handles data center outages. But when the failure is the cloud provider itself — a global routing misconfiguration, a control plane bug, or an infrastructure-wide incident — multi-region buys you nothing. Every replica, every failover target, every backup sits behind the same control plane that just went down.
Cross-cloud DR eliminates this by placing standby infrastructure on a completely independent cloud provider, with its own control plane, networking, and failure domains. This is architecturally impossible for cloud-native databases like Aurora, Cloud Spanner, or AlloyDB — they're built on proprietary infrastructure that doesn't exist outside their provider. OceanBase Cloud, as a cloud-neutral database service running on AWS, Alibaba Cloud, Huawei Cloud, and Google Cloud, makes cross-cloud replication a natural extension of its deployment model rather than a bolt-on.
This post explains how OceanBase Cloud's cross-cloud primary-standby architecture works: the two sync methods and their trade-offs, architecture patterns, failover mechanics, and how to choose between primary-standby and active-active.
Two Sync Methods: Direct Network vs. Log Archiving
OceanBase Cloud offers two mechanisms for keeping the standby synchronized with the primary. They solve the same problem — streaming redo logs from primary to standby — but take fundamentally different paths to get there.
Direct Network Connection (Hot Standby)
The primary connects to the standby through a dedicated cross-cloud channel — VPC peering, a dedicated line, or an encrypted public internet link. Two internal services handle the data flow:
Because the data path is direct — no intermediary storage — sync latency sits at the millisecond level. The standby is continuously replaying the primary's write stream, which means it can serve read traffic (read/write separation is supported in this mode). Data in transit is encrypted with AES-128-GCM with periodically rotated session keys.
The trade-off is cost and network complexity. You need a cross-cloud private network channel, and someone has to manage VPC peering or dedicated lines between two cloud providers.
Log Archiving (Cold Standby)
The primary writes its redo logs to object storage in its own region, for example, OSS on Alibaba Cloud, S3 on AWS. The standby on the other cloud reads those archived logs over the public internet and replays them locally.
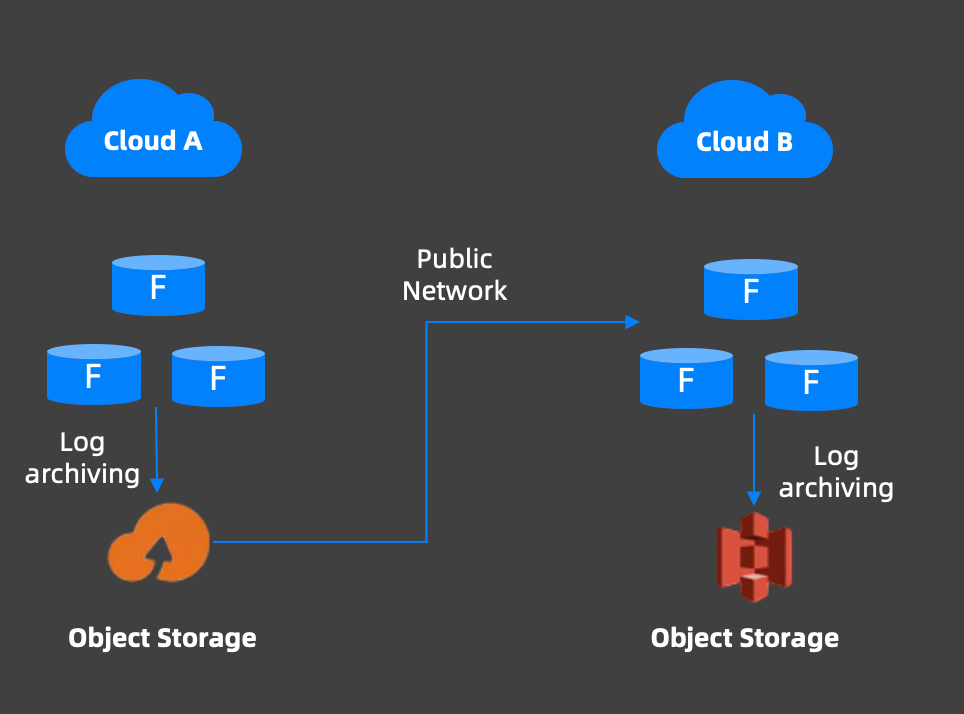
Sync latency is at the second level rather than milliseconds, because the data takes an extra hop through object storage. Read/write separation is not supported — the standby is purely a recovery target, not serving live reads.
Choosing Between Them
Direct network | Log archiving | |
|---|---|---|
| Sync latency | Milliseconds | Seconds |
| Sync path | Primary → VPC/dedicated line → Standby | Primary → Object storage → Standby |
| Read/write split | Supported (standby serves reads) | Not supported |
| Network requirement | Cross-cloud private channel | Public internet only |
| Cost | Higher | Lower |
| RPO sensitivity | Suitable | Not suitable for strict RPO |
| Setup complexity | VPC peering or dedicated line required | On-demand, no network changes |
Most production deployments that need cross-cloud DR for compliance or business continuity reasons use the direct network connection. Log archiving is a good fit for cost-sensitive environments where second-level lag is acceptable — development/staging DR, reporting replicas, or regulatory data residency requirements where the standby is more about having data in another jurisdiction than about fast failover.
Architecture Patterns: 1:1 and 1:n
Cross-cloud primary-standby supports two topology patterns, depending on how much redundancy you need at the DR layer.
One-Primary-One-Standby (1:1)
The baseline topology: a primary instance on Cloud A, a single standby on Cloud B. The standby syncs from the primary using either method above. If the primary fails, the standby gets promoted and begins accepting read-write traffic.
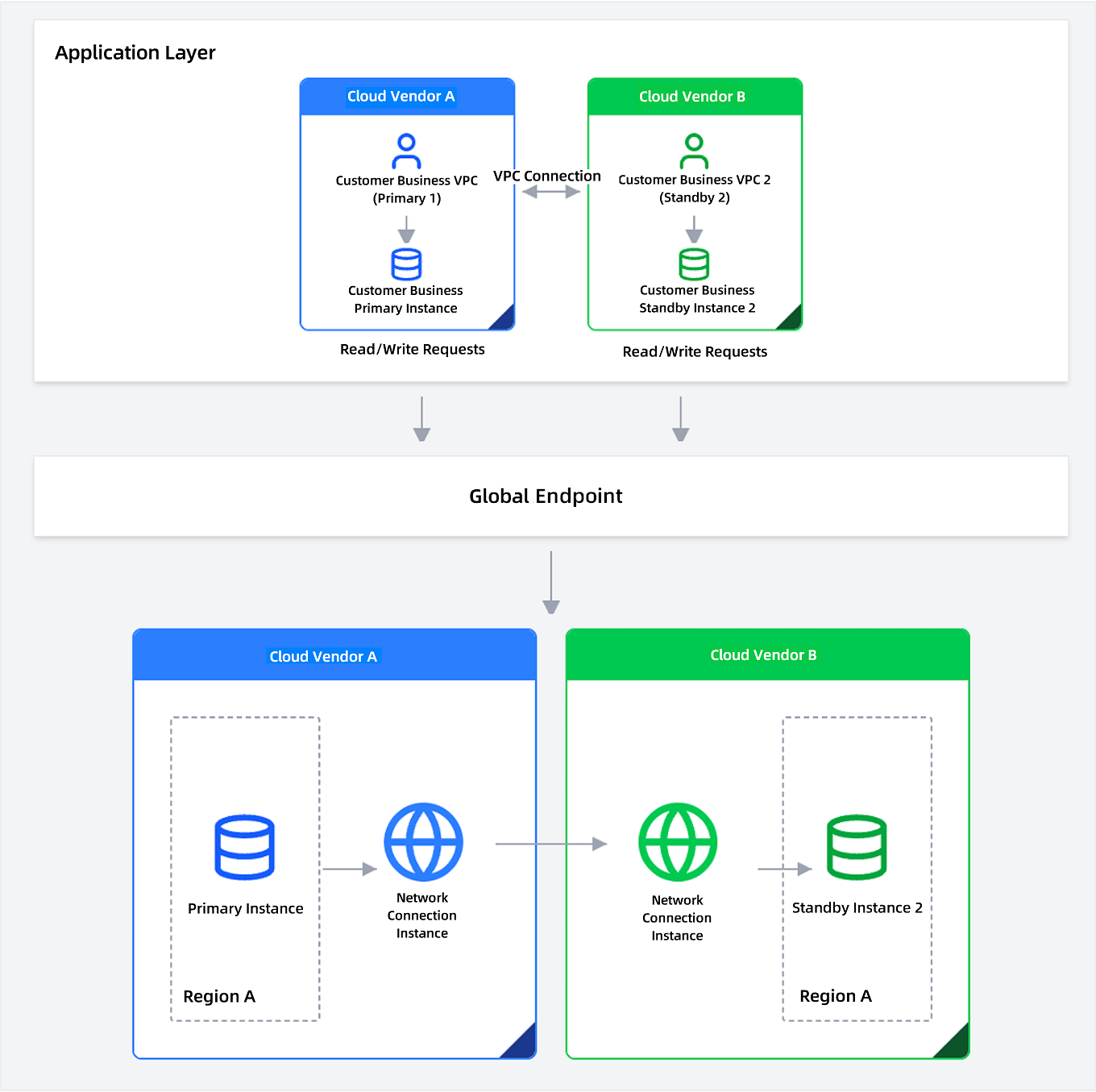
Each side lives in its own VPC. Application servers in the primary VPC connect to the primary instance directly; the standby VPC has its own application server on standby, connected but not serving traffic. Both sides are also reachable through the global endpoint, which handles routing automatically during failover — more on that in the next section.
One-Primary-Multi-Standby (1:n)
For environments that need higher redundancy, OceanBase Cloud supports up to three standby instances per primary. The standbys can be distributed across different cloud vendors and different regions within the same vendor — so you're protected against both cloud-vendor-level and region-level failures simultaneously.
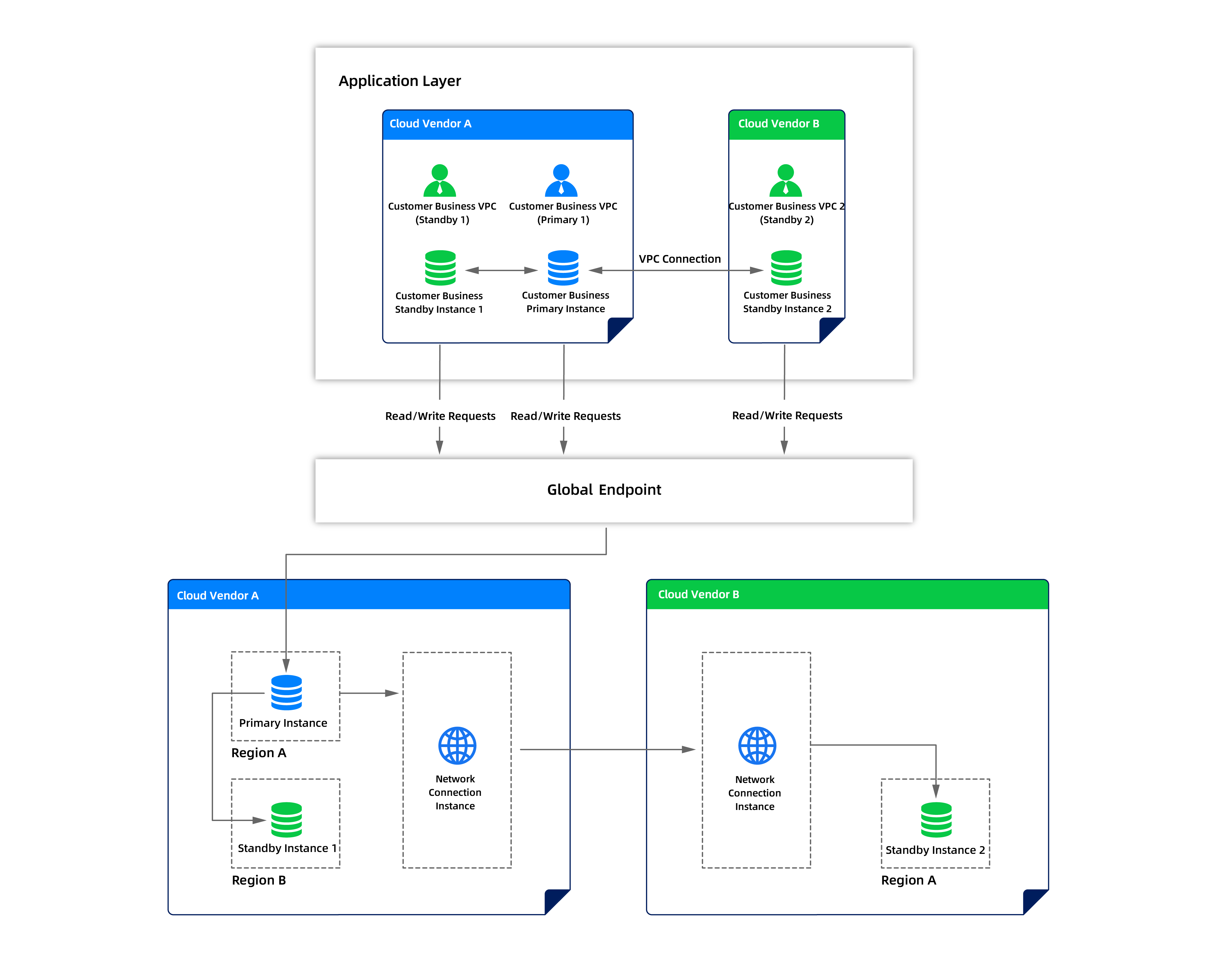
All standbys sync directly from the primary — there's no cascading replication between standbys, which avoids the latency accumulation and failure-mode complexity that cascading introduces. The primary and standby instances are connected across clouds through network connection instances that bridge each cloud vendor's VPC, and the global endpoint connects to all of them.
The key operational benefit is redundancy at the DR layer itself. If one standby becomes unavailable — say, its cloud vendor has a maintenance event — the other standbys remain synchronized and ready for failover. You're not one failure away from losing your DR capability. And after any failover, the remaining standby instances automatically establish new sync relationships with the promoted primary, preserving the 1:n topology without manual rewiring.
Failover: What Actually Happens
This is the scenario the entire architecture exists for: Cloud A goes down — not a single zone, not a single region, but the provider itself. Your primary database is unreachable, and everything behind that control plane is gone. Here's how the failover plays out.
1. Detection. The primary instance on Cloud A becomes unreachable. The cross-cloud sync link disconnects, and standby instances on Cloud B (and Cloud C, in a 1:n setup) stop receiving new logs.
2. Sync completion. Before promoting a standby, the system ensures all candidate standbys have replayed logs up to the largest synchronization point among them. This prevents data divergence between standbys — critical when the standbys live on entirely separate cloud infrastructures with no shared state.
3. Standby selection. In a 1:n topology, the operator selects which standby to promote based on: data sync completeness, current sync latency, availability status, geographic proximity to the application, and resource capacity. If one standby is on the same cloud vendor as the failed primary (different region), the operator can prefer a standby on a different vendor entirely — maximizing failure domain separation.
4. Promotion. The selected standby is promoted to primary and begins accepting read-write traffic on its own cloud provider's infrastructure.
5. Global endpoint update. The global endpoint — a single connection address that routes traffic to whichever instance is currently primary — updates to point to the new primary. This isn't DNS-based failover with TTL propagation delays; the routing happens at the endpoint layer through network connection instances that bridge each cloud vendor's VPC. Applications never change their connection strings. Traffic shifts within the failover window rather than waiting for DNS caches to expire. From the application's perspective, the database moved to a different cloud provider — and the connection string didn't change.
6. Re-establishment. In a 1:n topology, the remaining standby instances automatically establish new sync relationships with the promoted primary. The 1:n architecture is preserved without manual rewiring — even though the primary now lives on a different cloud than where it started.
Failover completes in 3–5 minutes with the direct network connection method. With log archiving, it's 1–5 minutes depending on how much archived log data the standby needs to catch up on. Either way, your database is back online on an entirely independent cloud provider — the exact scenario where same-cloud multi-region architectures would still be down.
OceanBase Cloud also supports planned primary-standby switching — the same mechanics, but initiated proactively for maintenance, migration, or DR testing. The primary gracefully hands off to the standby, and the former primary becomes a standby after the switch. This is worth running periodically: the worst time to discover your cross-cloud failover doesn't work is during an actual cloud-wide outage.
When to Use Primary-Standby vs. Active-Active
OceanBase Cloud offers both cross-cloud primary-standby and cross-cloud active-active, which we covered in our last post. They protect against the same failure domain — an entire cloud provider going down — but with different trade-offs.
Primary-Standby | Active-Active | |
|---|---|---|
| Write topology | Single-writer | Multi-writer (both sides accept writes) |
| Conflict handling | Not needed | Required (loopback prevention + conflict detection) |
| Failover speed | 3–5 minutes (promotion required) | Near-zero (both sides already serving) |
| Standby cost | As low as 0.33x primary spec | Full-capacity on both sides |
| Complexity | Lower (no conflict resolution logic) | Higher (OMS, CDC, conflict strategies) |
| Read scaling | Optional (direct network mode only) | Both sides serve reads by default |
Choose primary-standby when: cost-sensitive DR is the priority, your application has a natural single-writer model, you need cross-cloud protection but can tolerate minutes of RTO, or regulatory requirements mandate data residency with a passive replica in another jurisdiction.
Choose active-active when: you need near-zero RTO, your application already distributes traffic across regions, or you want both sides to serve production read-write traffic rather than keeping one side idle.
Limitations Worth Knowing
Download The Multi-Cloud DR Playbook to compare cross-cloud DR patterns, failover trade-offs, and cost profiles side by side.



Keep Reading
View all posts
Exploring OceanBase 4.3: New Features and Enhancements
At the OceanBase DevCon 2024, we introduced the OceanBase 4.3.0 Beta, unveiling a brand new columnar engine. This release achieves near petabyte-scale, real-time analytics in seconds, and enhances the integration of TP and AP capabilities.



How seekdb M0 Gives OpenClaw Persistent Memory and Shared Experience
OpenClaw's memory degrades over time—an architectural limitation, not a configuration issue. seekdb M0 solves this with cloud-based memory that persists across sessions and shares learned experience across agents.


Deploy and Run OceanBase from Qoder Desktop in One Sentence
See how the OceanBase plugin for Qoder Desktop handles host checks, deployment, verification, lifecycle operations, and ecosystem components.
