

















For queries to join multiple tables, an important task of the optimizer is to determine the join order of tables, which has effects on the size of the intermediate result sets and the overall cost of plan execution.
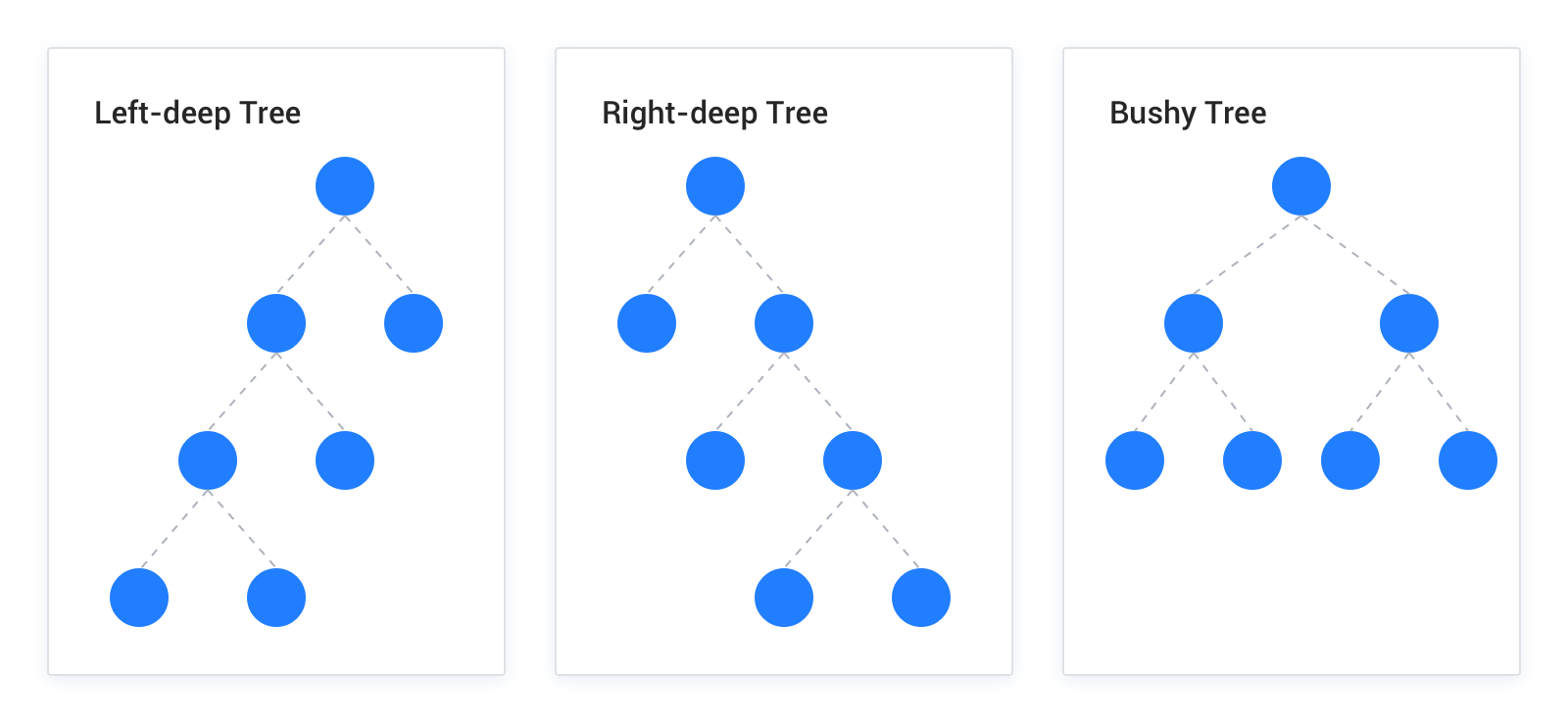
To reduce the search range and memory usage for plan execution, the OceanBase Database optimizer uses the left-deep join tree to determine the join order. The following figure shows the shapes of a left-deep tree, a right-deep tree, and a bushy tree.
OceanBase Database selects the enumeration algorithm based on the value of the system variable _join_order_enum_threshold, which is 10 by default:
- If the number of tables in the query is less than this threshold, the Iterative Dynamic Programming (IDP) algorithm is used.
- If the number of tables in the query is greater than or equal to this threshold, the permutation enumeration algorithm is used.
IDP algorithm
The execution steps of the IDP algorithm for joining N base tables are as follows:
Initialize a dynamic programming data structure with N layers, where the 0th layer consists of all candidate plans for the N base tables.
The algorithm divides the dynamic programming process into multiple rounds of iteration. In each round, it performs a certain number of steps of dynamic programming enumeration based on the previous results.
- In each round of DP, it enumerates plans for each layer from 1 to the current step length. A plan for the ith layer is generated by joining plans from the jth layer with plans from the (i-j-1)th layer.
- If the number of intermediate plans exceeds the threshold (controlled by
_idp_step_reduction_threshold, default 5000), the step length is reduced to control the search space. - At the end of each round, the algorithm selects the join plan with the lowest cost from the current plans using a greedy strategy as the starting point for the next round.
Finally, the algorithm selects the optimal plan from the highest layer.
Permutation enumeration algorithm
When the number of tables is large, the permutation enumeration algorithm is used. Its execution steps are as follows:
- Generate an initial solution as a left-deep join tree using the greedy method.
- Enumerate permutations based on this initial solution. Each permutation corresponds to a left-deep join tree. Heuristics are used during the enumeration to prune the search space. The maximum number of permutations to be enumerated is controlled by the system variable
_optimizer_max_permutations(default value 2000). - Select the optimal plan from all enumerated permutations.
Plan Comparison
In the process of join enumeration, multiple candidate plans for the same set of tables may be generated. When comparing two candidate plans, the optimizer evaluates their dominance across multiple dimensions to decide which plans to keep. When a new candidate plan is added, it is compared one by one with all existing candidate plans:
- If the new plan is dominated by an existing plan (or both plans are equivalent), the new plan is discarded.
- If the new plan dominates an existing plan, the existing plan is removed.
- If the plans are incomparable (each has its advantages), both are retained.
A plan dominates another only if it does not have any of the following weaknesses in all dimensions:
- Cost.
- Parallelism.
- Data distribution.
- Streaming property.
- Output order.
Hint Mechanism
OceanBase Database allows you to use the hint /*+LEADING(table_name_list)*/ to control the order of a multi-table join.
Examples:
Create the
tbl1table.obclient> CREATE TABLE tbl1(col1 INT, col2 INT, PRIMARY KEY(col1));Create the
tbl2table.obclient> CREATE TABLE tbl2(col1 INT, col2 INT, PRIMARY KEY(col1));Create the
tbl3table.obclient> CREATE TABLE tbl3(col1 INT, col2 INT, PRIMARY KEY(col1));Join
tbl1andtbl2first, then join the result withtbl3.obclient> EXPLAIN SELECT * FROM tbl1, tbl2, tbl3 WHERE tbl1.col1 = tbl2.col2 AND tbl2.col1 = tbl3.col2;The result is as follows:
+--------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------+ | ======================================================= | | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| | | ------------------------------------------------------- | | |0 |MERGE JOIN | |1 |7 | | | |1 |├─TABLE FULL SCAN |tbl1|1 |3 | | | |2 |└─SORT | |1 |5 | | | |3 | └─MERGE JOIN | |1 |5 | | | |4 | ├─TABLE FULL SCAN |tbl2|1 |3 | | | |5 | └─SORT | |1 |3 | | | |6 | └─TABLE FULL SCAN|tbl3|1 |3 | | | ======================================================= | | Outputs & filters: | | ------------------------------------- | | 0 - output([tbl1.col1], [tbl1.col2], [tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | equal_conds([tbl1.col1 = tbl2.col2]), other_conds(nil) | | merge_directions([ASC]) | | 1 - output([tbl1.col1], [tbl1.col2]), filter(nil), rowset=16 | | access([tbl1.col1], [tbl1.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl1.col1]), range(MIN ; MAX)always true | | 2 - output([tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | sort_keys([tbl2.col2, ASC]) | | 3 - output([tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | equal_conds([tbl2.col1 = tbl3.col2]), other_conds(nil) | | merge_directions([ASC]) | | 4 - output([tbl2.col1], [tbl2.col2]), filter(nil), rowset=16 | | access([tbl2.col1], [tbl2.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl2.col1]), range(MIN ; MAX)always true | | 5 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | sort_keys([tbl3.col2, ASC]) | | 6 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | access([tbl3.col1], [tbl3.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl3.col1]), range(MIN ; MAX)always true | +--------------------------------------------------------------------------------------------------------------------+ 35 rows in setIf you want to join
tbl2andtbl3first, then join the result withtbl1, you can use the hint/*+LEADING(tbl2,tbl3,tbl1)*/.obclient> EXPLAIN SELECT /*+LEADING(tbl2,tbl3,tbl1)*/* FROM tbl1, tbl2, tbl3 WHERE tbl1.col1 = tbl2.col2 AND tbl2.col1 = tbl3.col2;The result is as follows:
+--------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------+ | ===================================================== | | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| | | ----------------------------------------------------- | | |0 |HASH JOIN | |1 |7 | | | |1 |├─MERGE JOIN | |1 |5 | | | |2 |│ ├─TABLE FULL SCAN |tbl2|1 |3 | | | |3 |│ └─SORT | |1 |3 | | | |4 |│ └─TABLE FULL SCAN|tbl3|1 |3 | | | |5 |└─TABLE FULL SCAN |tbl1|1 |3 | | | ===================================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([tbl1.col1], [tbl1.col2], [tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | equal_conds([tbl1.col1 = tbl2.col2]), other_conds(nil) | | 1 - output([tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | equal_conds([tbl2.col1 = tbl3.col2]), other_conds(nil) | | merge_directions([ASC]) | | 2 - output([tbl2.col1], [tbl2.col2]), filter(nil), rowset=16 | | access([tbl2.col1], [tbl2.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl2.col1]), range(MIN ; MAX)always true | | 3 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | sort_keys([tbl3.col2, ASC]) | | 4 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | access([tbl3.col1], [tbl3.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl3.col1]), range(MIN ; MAX)always true | | 5 - output([tbl1.col1], [tbl1.col2]), filter(nil), rowset=16 | | access([tbl1.col1], [tbl1.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl1.col1]), range(MIN ; MAX)always true | +--------------------------------------------------------------------------------------------------------------------+ 31 rows in setIf you want to join
tbl1andtbl3first, then join the result withtbl2, you can use the hint/*+LEADING(tbl1,tbl3,tbl2)*/.obclient> EXPLAIN SELECT /*+LEADING(tbl1,tbl3,tbl2)*/* FROM tbl1, tbl2, tbl3 WHERE tbl1.col1 = tbl2.col2 AND tbl2.col1 = tbl3.col2;The result is as follows:
+--------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------+ | ============================================================= | | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| | | ------------------------------------------------------------- | | |0 |HASH JOIN | |1 |7 | | | |1 |├─NESTED-LOOP JOIN CARTESIAN | |1 |5 | | | |2 |│ ├─TABLE FULL SCAN |tbl1|1 |3 | | | |3 |│ └─MATERIAL | |1 |3 | | | |4 |│ └─TABLE FULL SCAN |tbl3|1 |3 | | | |5 |└─TABLE FULL SCAN |tbl2|1 |3 | | | ============================================================= | | Outputs & filters: | | ------------------------------------- | | 0 - output([tbl1.col1], [tbl1.col2], [tbl2.col1], [tbl2.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | equal_conds([tbl1.col1 = tbl2.col2], [tbl2.col1 = tbl3.col2]), other_conds(nil) | | 1 - output([tbl1.col1], [tbl1.col2], [tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | conds(nil), nl_params_(nil), use_batch=false | | 2 - output([tbl1.col1], [tbl1.col2]), filter(nil), rowset=16 | | access([tbl1.col1], [tbl1.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl1.col1]), range(MIN ; MAX)always true | | 3 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | 4 - output([tbl3.col1], [tbl3.col2]), filter(nil), rowset=16 | | access([tbl3.col1], [tbl3.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl3.col1]), range(MIN ; MAX)always true | | 5 - output([tbl2.col1], [tbl2.col2]), filter(nil), rowset=16 | | access([tbl2.col1], [tbl2.col2]), partitions(p0) | | is_index_back=false, is_global_index=false, | | range_key([tbl2.col1]), range(MIN ; MAX)always true | +--------------------------------------------------------------------------------------------------------------------+ 29 rows in set