

















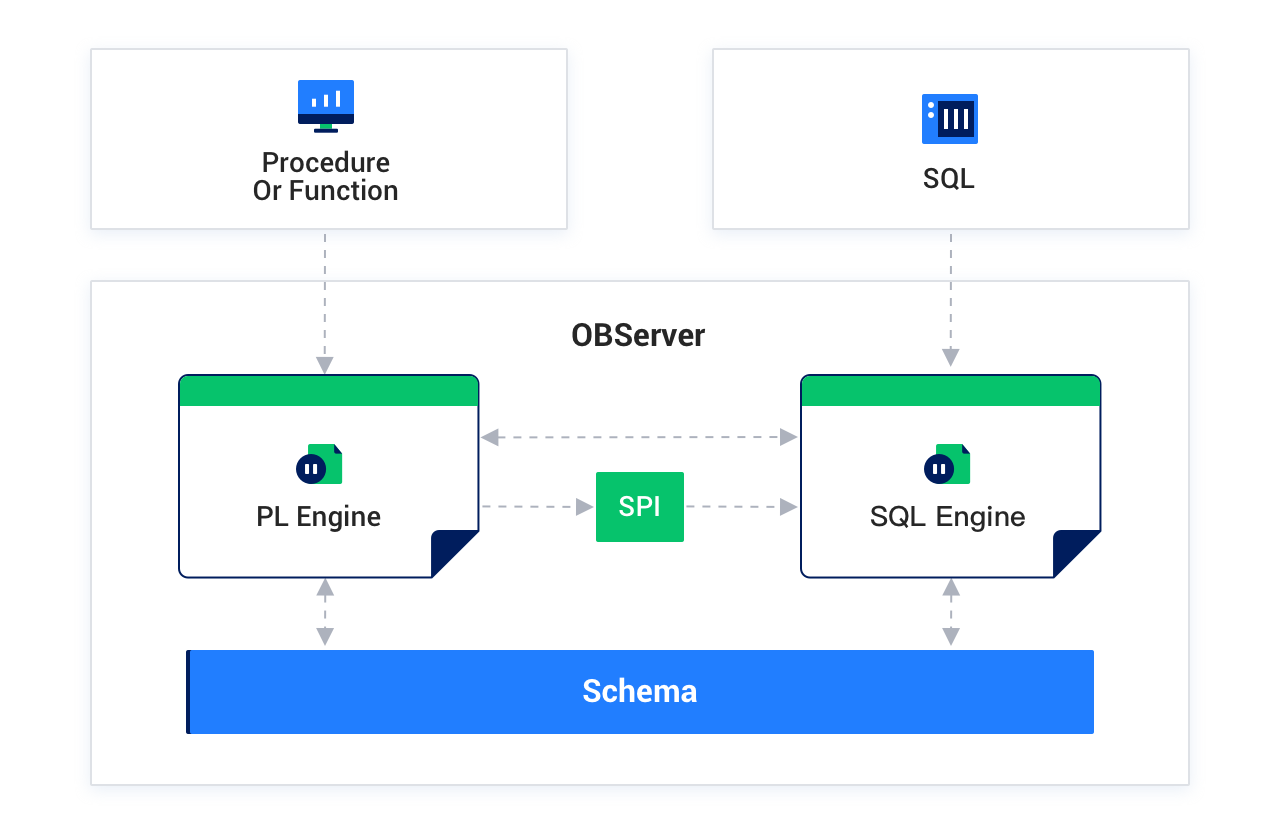
The PL engine (PL Engine) and SQL engine (SQL Engine) can interact with each other. SQL can directly access the PL engine, for example, by using user-defined functions. The PL engine can access the SQL engine through the SPI interface to perform expression calculations and execute SQL statements.
The interaction between the two engines is shown in the following figure:
The PL engine consists of six modules: Parser, Resolver, Code Generator, Compiler, Executor, and PL Cache. The Parser, Resolver, Code Generator, and Compiler modules form a complete PL compilation process. The following figure shows the modules.
Parser (syntax parser)
The Parser analyzes the syntax of PL and generates a syntax tree (Parse Tree). The PL engine and SQL engine each implement their own Parser, but the two Parsers avoid redundant work. In an OBServer node, a query string first enters the PL Parser for parsing. If the query string is an SQL statement, the SQL engine parses it.
Resolver (semantic parser)
The Resolver performs semantic analysis, such as checking variable scopes and data objects in static SQL statements, and generates an abstract syntax tree (AST) structure for each PL statement as well as a global AST structure. The AST stores basic information about the PL definition, including the global symbol table, global label table, and global exception table. The AST of each statement records logical information pointing to these global tables.
Code Generator (code generator)
The Code Generator uses the LLVM interface to further translate the AST into intermediate representation (IR) code. The IR code can be used to verify the correctness of the translation process.
Compiler (compiler)
The Compiler uses just-in-time (JIT) compilation to generate machine code from the IR code and outputs the result as an executable PL object.
Executor (executor)
The Executor constructs an execution environment based on the compiled PL executable object and input parameters, calls a function pointer, and obtains the function result.
PL Cache (execution plan cache module)
The PL Cache is an internal mechanism of the PL engine. The PL engine provides a unified interface for executing procedures or functions by ID, and external components do not need to understand the PL cache mechanism. They can simply execute PL through the PL engine. The PL Cache is a hash table that uses the ID of a procedure or function as the key to find the corresponding PL execution object (value). It also checks the validity of the PL execution object by accessing the schema. If the PL execution object is invalid, it is immediately deleted. The PL Cache avoids recompiling PL every time, thus improving the execution efficiency of PL. Therefore, anonymous blocks (Anonymous Blocks) do not require the use of the cache.
The PL engine provides an Execute interface, which includes parameters such as the PL ID, execution parameters params, execution environment Context, and execution result Result (only applicable to functions). First, the system checks the PL Cache for a compiled PL executable object based on the ID. If one is found, it further checks the version. If no valid PL executable object is found in the PL Cache, the system calls the compilation process to compile the PL. The compiled result is cached in the PL Cache and then passed to the Executor for execution. The compilation result is a memory address of binary code. The Executor converts this memory address into a function pointer and runs it with the execution parameters and environment to obtain the result.